ndarray
- nadrray就是N维数组对象,是一个快速灵活的大数据集容器
- 可以用这种数组(ndarray)对整块数据执行数学运算
导入Nump库的代码
import numpy as np
生成一些随机数据
data = np.random.randn(2, 3)
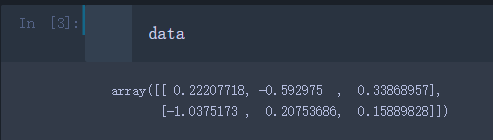
–numpy.random.randn()
- randn函数返回一个或一组样本,具有标准正态分布
- 标准正态分布又称为u分布,是以0为均值,以1为标准差的正态分布,记为N(0, 1)
–dn表示每个维度,randn(2, 3)表示返回一个2行3列的数组
数组可以进行数学运算
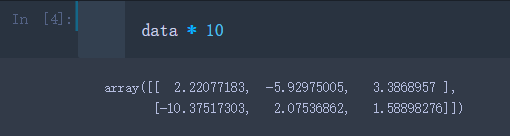
- 把数组中的每个元素都乘以10
data * 10
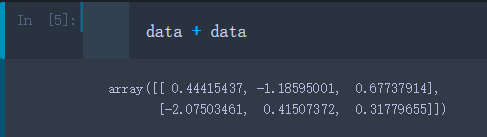
- 两个数组相加,数组中各个元素对应相加
data + data
numpy是一个通用的同构数据多维容器,其中所有的元素必须是相同类型的
每个数组都有
- shape(一个表示各维度大小的元组)
- dtype(一个用于说明数组数据类型的对象)
看一下data数组的shape和dtype
data.shape
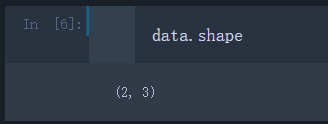
可以看出data是一个2行3列的数组
data.dtype
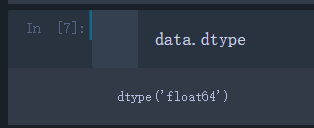
可以看出data的数组数据类型为’float64’
创建ndarray
array函数可以用来创建ndarray数组,它接受一切序列型的对象(包括其它数组)
以一个列表的转换为例:
data1 = [6, 7.5, 8, 0, 1]
arr1 = np.array(data1)
arr1
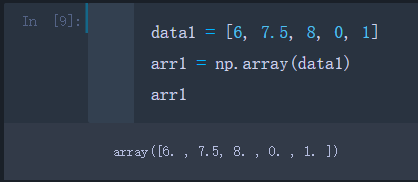
可以看到列表data1转换成了数组arr1
如果列表是由一组等长列表组成,array函数会将其转换为一个多维数组
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(data2)
arr2
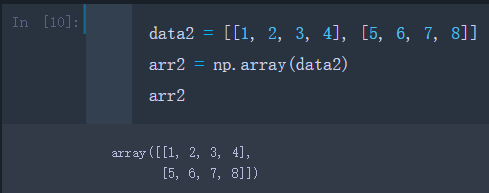
可以看出由两个列表组成的列表被转换成了一个2维数组
我们可以用属性ndim和shape验证
arr2.ndim
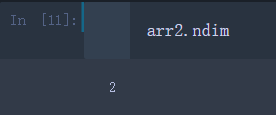
-ndim返回的是数组的维度,返回的只有一个数,该数即表示数组的维度
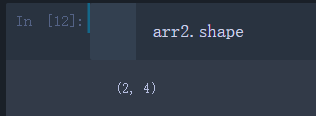
arr2.shape
–若无特殊说明,np.array会为待创建的数据选择最匹配的数据类型
–如上例的arr1,arr2,我们看一下创建的数据类型

可以看到,列表中有小数的话,array建立的数组数据类型为浮点型 --> ‘float64’
列表中如果都是整数,那么array建立的数组数据类型就为整数型 -->‘int32’
–np.zeros()方法可以创建指定长度或形状的全0数组
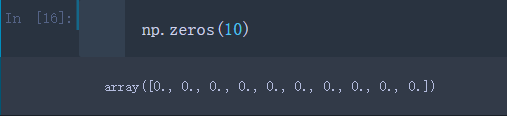
若传入一个数字10,那么默认创建一个一维的10个’0’的数组
np.zeros(10)
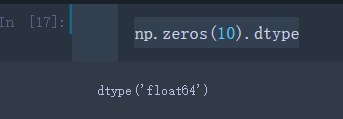
创建的数组数据类型为浮点型
np.zeros(10).dtype
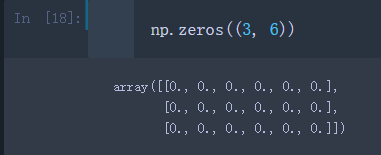
传入一个表示形状的元组,可以创建多维数组
比如创建一个3行6列的二维全’0’数组
np.zeros((3, 6))
–np.empty()方法指定长度或形状的未初始化数组,也可以传入元组创建多维数组
比如创建一个三维的未初始化数组(2 * 3行2列)
np.empty((2, 3, 2))

注意:np.empty返回全0数组的想法是不安全的,很多情况下返回的都是一些未初始化的垃圾值
np.arange()
–numpy中的arange是于python内置函数’range’的数组版
传入参数N,表示生成一个0到(N-1)的整数数组
例如创建一个0-14的整数数组
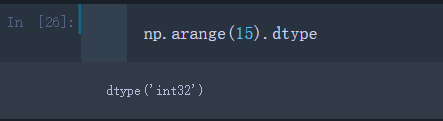
np.arange(15)

np.arange(15).dtype
注意:Numpy关注的是数值计算,如果没有特别指定,数据类型基本都是’float64’(浮点数)
下面是常用的一些数组创建函数,使用频率很高
- array: 将数据转换成ndarray(多维数组),dtype若不指定,默认匹配最适合源数据的数据类型
- asarry: 将数据转换未ndarray(多维数组),它和array的区别在于 --> 当源数据是ndarray时,array会
拷贝出一个ndarray副本,而asarray不会 - arange: 类似于python内置函数range,但是arange返回的是一个ndarry,而内置的range返回的是一个list
- ones: 根据指定的形状和dtype创建一个全’1’数组,默认为’float64’浮点型
- ones_like: 以另一个数组为参数(获取该数组的形状),根据该参数的形状创建一个全’1’数组
- zeros, zeros_like: 类似ones和ones_like,不过创建的是全’0’数组
- empty, empty_like: 类似ones和ones_like,不过它只分配内存空间,但是不填充任何值(创建的都是未初始化的垃圾值)
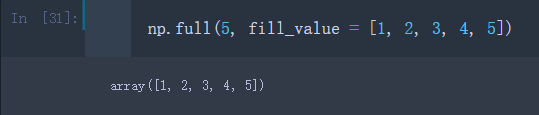
- full: 使用fill value中的所有值,根据指定的形状和dtype创建一个数组(此处模拟一组fill_value)
- full_like: 以另一个数组的形状创建一个相同形状的数组,数组值为fill_value
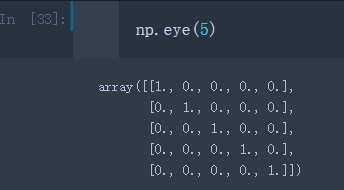
- eye: 输入参数N,创建一个正方的N * N单位矩阵(对角线为1,其余为0),数组类型为浮点型
- identity: 和np.eye()作用一致
dtype
–dtype含有将ndarry的一块内存解释为特定数据类型所需的信息
常见的Numpy数据类型
- int8: 类型代码:i1 -->有符号的8位(1个字节)整型
- uint8: 类型代码:u1 -->无符号的8位(1个字节)整型
- int16: 类型代码:i2 -->有符号的16位(2个字节)整型
- uint16: 类型代码:u2 -->无符号的16位(2个字节)整型
- int32: 类型代码:i4 -->有符号的32位(4个字节)整型
- uint32: 类型代码:u4 -->无符号的32位(4个字节)整型
- int64: 类型代码:i8 -->有符号的64位(8个字节)整型
- uint64: 类型代码:u8 -->无符号的64位(8个字节)整型
- float16: 类型代码:f2 -->半精度浮点数
- float32: 类型代码:f4或f -->标准的单精度浮点数(与C的float兼容)
- float64: 类型代码:f8或d -->标准的双精度浮点数(与C的double和Python的float对象兼容)
- float128: 类型代码:f16或g -->扩展精度浮点数
- complex64: 类型代码:c8 -->用两个32位浮点数表示的复数
- complex128: 类型代码:c16 -->用两个64位浮点数表示的复数
- complex256: 类型代码:c32 -->用两个128位浮点数表示的复数
- bool: 类型代码:? -->存储True和False的布尔类型
- object: 类型代码:O -->Python对象类型
- string_: 类型代码:S -->固定长度的字符串类型(每个字符1个字节),例如要创建一个长度为10的字符串,应使用S10
- unicode_: 类型代码:U -->固定长度的unicode类型(字节数由平台决定)
– 可以通过ndarray的astype方法明确地将一个数组从一个dtype转换成另一个dtype
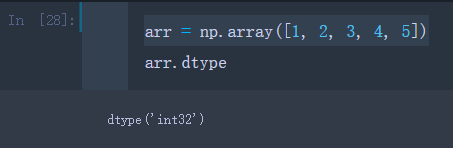
假设有一个整数型数组arr
arr = np.array([1, 2, 3, 4, 5])
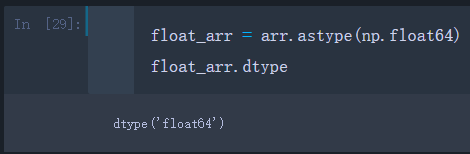
将arr转换成浮点数
float_arr = arr.astype(np.float64)
假如将浮点数转换为整数,那么小数部分会被截取删除
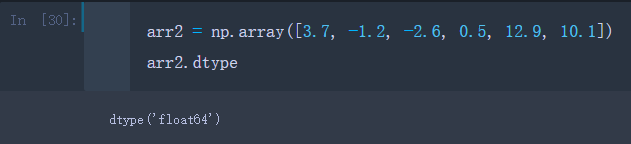
例如有个浮点型数组arr2
arr2 = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
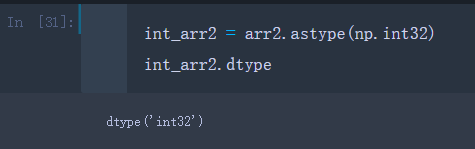
转换成整数型
int_arr2 = arr2.astype(np.int32)
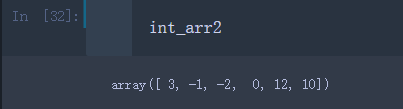
可以看到新数组int_arr2将原数组的小数部分截取删除了
也可以用astype将字符串数组转换为数值的形式
假设有一个字符串数组numeric_strings
numeric_strings = np.array(['1.25', '-9.6', '42'], dtype = np.string_)
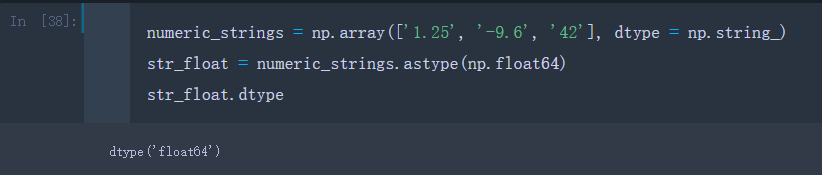
- 注意:使用np.string_类型时,要注意字符串长度,因为numpy的字符串数据大小是固定的,发生截取的时候不会报错
- 如果转换过程中,字符串 --> 数值的转换失败(如"一"无法转换成数值1,会引发一个ValueError
–我们也可以将一个数组的dtype当作参数传入astype方法中
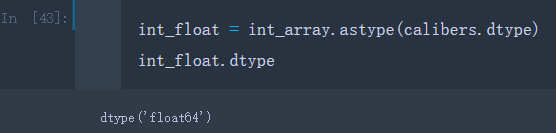
假设有一个整数型数组int_array和一个浮点型数组calibers
int_array = np.arange(10)
calibers = np.array([.22, .270, .357, .380, .44, .50], dtype = np.float64)

如果想把int_array转换成和calibers一样的浮点型数组,可以将calibers的dtype传入astype方法的参数中
int_float = int_array.astype(calibers.dtype)
int_float.dtype
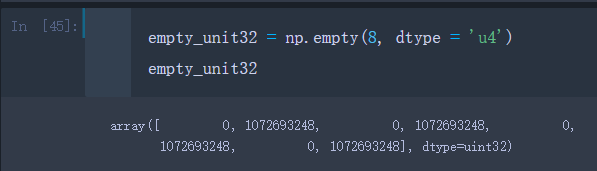
–也可以用数据类型的类型代码来表示dtype
empty_unit32 = np.empty(8, dtype = 'u4')
Numpy数组的运算
- 大小相等的数组之间的任何算术运算都会将运算应用到元素级
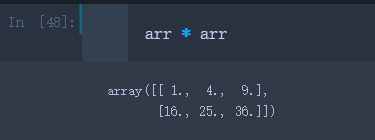
创建一个2行3列的二维数组arr
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr.shape

大小相等的数组之间做乘法,元素对应相乘
arr * arr
大小相等的数组之间做减法,元素对应相减
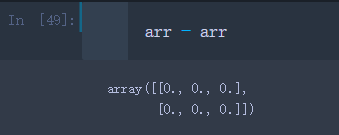
arr - arr
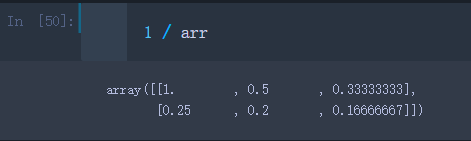
数组和标量之间的算术运算,会将标量值运算传播到各个元素
1 / arr
大小相同的数组之间比较,会产生布尔值数组
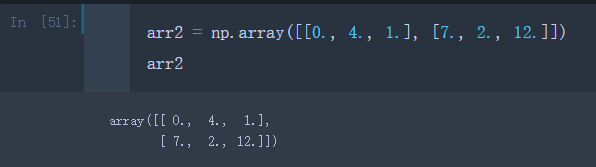
我们再创建一个大小和arr相同的二维数组arr
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
– 将arr和arr2作比较
arr2 > arr
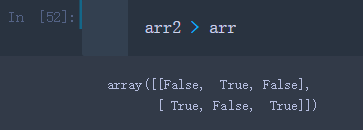
可以看到产生了一个大小相同的布尔型数组,数组中每个元素都是arr和arr2相对应的比较
基本的索引和切片
一维数组切片
- 从表面上来看,一维数组的切片和Python的list切片功能差不多
创建一个0-9的整数型数组arr
arr = np.arange(10)
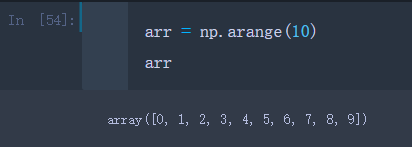
- 取arr中的第六个元素
arr[5]
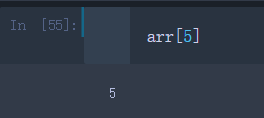
- 取arr中的第6个到第8个元素,切片前闭后开
arr[5: 8]
- 可以对切片的部分进行赋值,源数组原地修改
假如我将arr的第6到第8个数用’12’赋值
arr[5: 8] = 12

可以看到,arr数组被原地修改
– 所以,数组切片和python列表切片最重要的区别就是:数组切片是原始数据的视图,这意味着数据不会被复制,视图上的任何修改都会直接反应到源数组上
举个例子,创建一个arr的切片arr_slice
arr_slice = arr[5: 8]
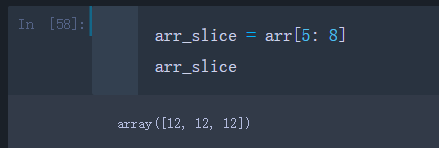
- 注意:如果我们修改了arr_slice的值,变动会体现在原始数组arr中
比方把arr_slice的第二个数用’12345’赋值
arr_slice[1] = 12345
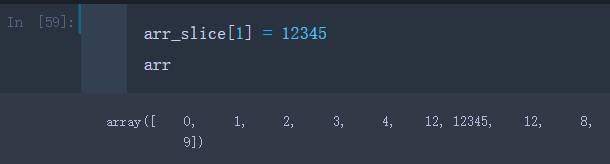
可以看到,源数组的数据也被修改
– 切片[:] 意思是切下数组中的所有值
比如我们给arr_slice中的每一个元组赋值’64’
arr_slice[:] = 64
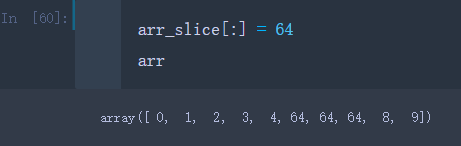
可以看出,arr_slice中每个元素都被’64’赋值
- 以上操作不同于python原生切片的原因在于,Numpy设计目的是处理大数据,如果将数据复制来复制去的,会给性能和内存带来非常大的压力
- 当然,如果想得到ndarray(数组)的切片副本而非视图的话,可以在切片之后增加一个copy()方法
例如,我们想得到arr第6个到第8个元素的切片副本,并用’6’赋值
arr3 = arr[5: 8].copy()
arr3[:] = 6

可以看到,对数组切片的副本进行操作并不会影响到源数组
二维数组
– 在一个二维数组中,它的各个索引位置上的元素不再是一维数组那样的标量,而是一个个一维数组
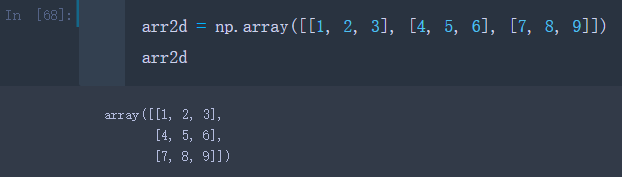
比如创建一个二维数组arr2d
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
取arr2d的第三个元素
arr2d[2]

得到的是一个一维数组
– 想要得到单个标量元素,可以对高维度的各个元素进行递归访问
比如我想取到二维数组第一个一维数组的第三个标量
arr2d[0, 2]

这里就用到了分层递归的思想

多维数组
– 多维数组道理和二维数组相似
我们创建一个2 * 2 * 3的三维数组arr3d
arr3d = np.array([[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]])

- 如果对arr3d切片,传入一个标量参数,那么返回的是降了一维的二维数组
比方我想获得arr3d的第一个二维数组
arr3d[0]
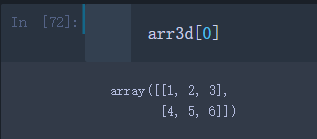
可以看到,返回的是一个2 * 3的二维数组
随着切片参数的增加,返回的数组维度也随之降低,直至返回一个标量值
– 标量值和数组都可以被赋值给arr3d[0]
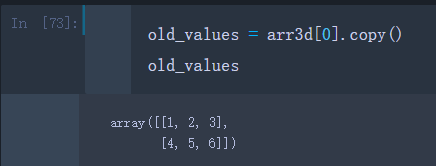
在展示赋值之前,我们先创建一个arr3d[0]的副本old_values以便恢复源数组
old_values = arr3d[0].copy()
然后,我们将arr3d这个三维数组的第一个二维数组赋值为42
arr3d[0] = 42

可以看到,切片得到的第一个二维数组中每个元素都被赋值为42
我们利用原先拷贝的副本恢复源数组
arr3d[0] = old_values
- 注意,没有特殊处理的情况下,切片所返回的都是源数组的视图,修改切片会影响到源数组的值
切片索引
– ndarray的切片语法跟Python列表这样的一维对象差不多
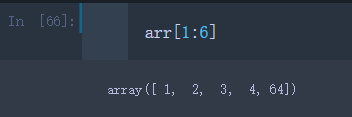
看一下之前的一维数组arr,我们取arr的第二个到第六个元素
arr[1:6]
对于3 * 3的二维数组arr2d,切片是沿着一个轴向选取元素的,第0轴为行,第1轴为列
我们选取二维数组的前两行
arr2d[:2]

这边可以看出,arr2d[ : 2]是arr2d[0: 2]的简便写法,表示选取arr2d的前两行(前闭后开)
– 也可以一次性传入多个切片
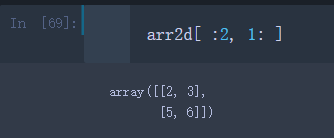
比方我们要选取arr2d前两行数组中,第二列以后的所有数据
arr2d[ :2, 1: ]
- 通过将整数索引和切片混合,可以得到低维度的切片
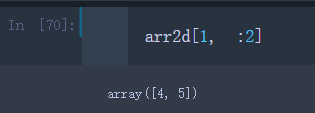
例如我要选取第二行的前两列
arr2d[1, :2]
我们得到了更低维度的一维数组
- 注意: 单个冒号,表示选取整个轴

- 当然,对切片的赋值操作也会被扩散到整个选取,因为切片是源数组处理后的视图,源数组会因切片的改变而收到影响
布尔型索引
– 假如,我们有一个用于存储数据的数组data和一个存储姓名的数组names(含有重复项)
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])

我们用numpy.random中的randn函数生成一个标准正态分布的7行4列随机数组data
data = np.random.randn(7, 4)

- 假设,names数组中的每个名字都对应着data数值中的每一行
我们想要选出对应’Bob’名字的所有行
– 我们先看下names中哪些名字是’Bob’
names == 'Bob'
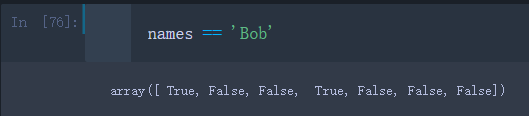
- 此处一定要用’==‘号而不是’='号,不然就把’Bob’赋值给names中每一个元素了
- 可以看出,产生了一个一维的布尔型数组,元素为’Bob’的返回了True,反之为False
– 接下来,我们把返回的布尔值数组作为索引传入data中
data[names == 'Bob']
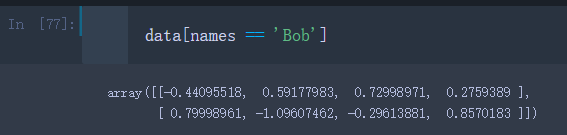
不难发现,data中对应’Bob’的行都被选取到了
- 注意:布尔型数组的长度必须跟被索引的轴的长度是一致的,如果长度不一致就会出错
– 当然也可以索引更多轴,比方加一个列索引,我想得到data中对应’Bob’的行的第二列以后的数据
data[names == 'Bob', 2: ]
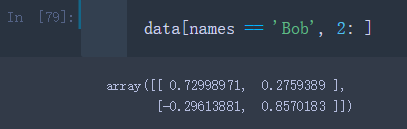
– 如果要选择除了’Bob’以外的其它值,可以使用不等号’! = ’ 或者’~'进行否定
data[names != 'Bob']

结果选出了除了Bob对应的行外的其余行
– 我们往往用’~'操作符来进行一些条件反转
比如我们先把’Bob’的布尔型数组传递给一个对象cond
cond = names == 'Bob'
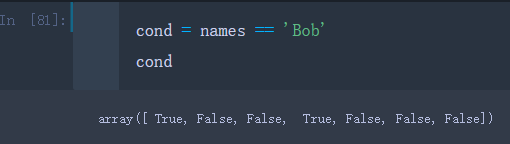
然后将该对象用~操作符进行反转传入data的索引中
data[~cond]
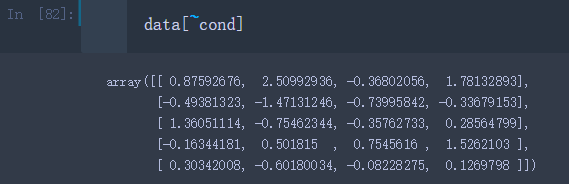
结果同样选出了除了Bob对应的行外的其余行
– 如果,我们想要增加判断条件,我们可以使用&(和), |(或),之类的布尔算术运算符(不能使用Python中的关键字and和or)
比如我想同时选出’Bob’和’Will’两个名字在data中对应的行
mask = (names == 'Bob') | (names == 'Will')
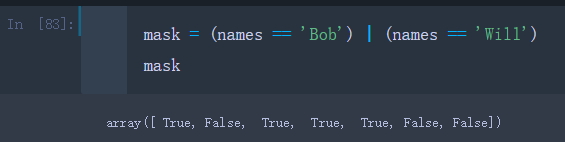
data[mask]
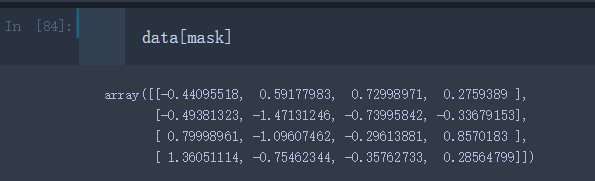
结果选出了Bob和Will对应的行
- 注意: 通过布尔值索引选取数组中的数据,将总是创建数据的视图
– 我们常常通过布尔型数组设置值
比如,把data中所有的负值都设置为0
data[data < 0] = 0

– 也可以通过一维布尔数组设置整行或者整列的值
data[names != 'Joe'] = 7

可以看到,data对应names为’Joe’的行中元素全部被赋值为7
花式索引
- 花式索引指的是:利用整数数组进行索引
– 假设有一个8 * 4的数组arr
arr = np.empty((8, 4))

这个数组仅仅为了创建空间,里面都是未初始化的垃圾值
– 现在我们用一个for循环填充这个数组
for i in range(8):
arr[i] = i

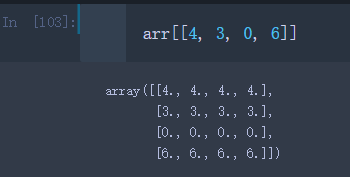
我们可以传入一个指定顺序的整数列表或者数组选取子集
arr[[4, 3, 0, 6]]
数组转置和轴兑换
- 转置类似于数组的重塑
- 转置不会进行任何复制操作,返回的是源数据的视图
- 数组有一个特殊的属性T用于转置
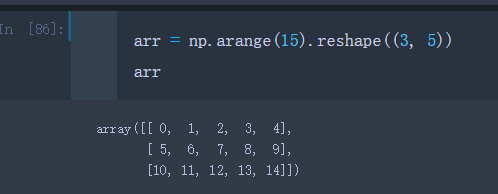
创建一个3行5列的二维数组
arr = np.arange(15).reshape((3, 5))
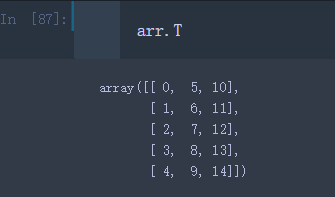
用属性T进行转置
arr.T
- 在进行矩阵计算时(如计算矩阵内积),往往需要用到转置
- 计算矩阵内积,我们可以用numpy中的dot函数
- 实际上,dot()返回的是两个数组的点积
– 我们创建一个二维数组尝试计算它和它的转置数组的内积
arr = np.random.randn(6, 3)

计算内积
np.dot(arr, arr.T)

– 至于三位数组的转置,这边得引入一个概念:transpose(转置)需要得到一个由轴编号组成的元组
举个例子,创建一个2 * 2 * 4的三维数组
arr = np.arange(16).reshape((2, 2, 4))

- 把三维数组的三个轴编号:0, 1, 2 我是想象成长方体的长(0),宽(1),高(2)
- 转置的时候,相当于长方体水平旋转90度,长和宽的值主观上理解为互换:原先的长变成了宽,而宽变成了长,所以转置后的长方体长宽高对应原先长方体的轴编号就是1(宽), 0(长), 2(高)
arr.transpose((1, 0, 2))

– 这边说一下numpy中的transpose函数,transpose中的参数可以理解为数组的轴标签
- 对于一维数组而言,numpy.transpose()是不起作用的,因为只有一个轴
- 对二维数组的transpose操作就是对原数组的转置操作,轴标签由(0, 1)转换成(1, 0)
- 对于三维数组,transpose会转换三个轴中的两个轴(看你怎么去定义这个转置了)
– ndarray中还有一个swapaxes方法,它可以进行轴交换
比方,我想交换三维数组的第二和第三个轴
arr.swapaxes(1, 2)

- swapaxes方法其实为转置另辟蹊径,很方便
- 同样要注意的是,swapaxes方法不会进行复制操作,返回的是源数据的视图