大家好,今天是对 SSM进行整合第二期!。 本文是坐着对bilibili的尚硅谷的SSM整合视频进行使用并记录流程进行发布。
逆向工程
执行完上期的内容后,我们现在来进行Mybatis的基本配置,以及逆向工程。
Mybatis的很多固定的语句可以在官方文档直接复制使用–>我是官方文档
首先需要先将下面的语句导入进我们的mybatis配置文件上方,有了这个语句,才能进行之后mybatis的配置操作。

<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
</configuration>
然后我们可以在配置文件中配置一些命名属性,如驼峰命名,起别名等。。这些可以便于数据库查出来直接与javabean对应,以及起别名方便使用。
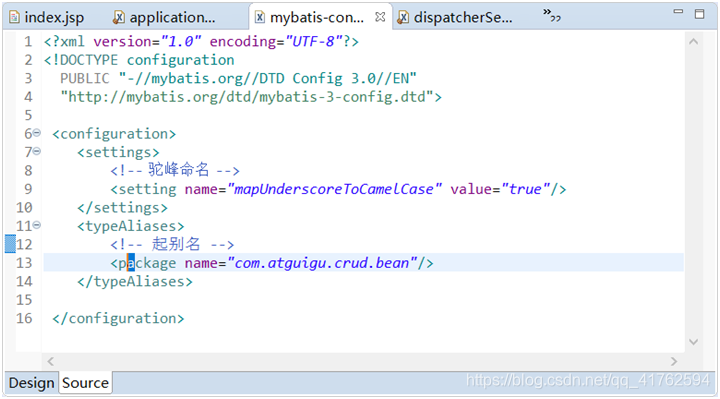
<configuration>
<settings>
<!-- 驼峰命名 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<typeAliases>
<!-- 起别名 -->
<package name="com.atguigu.crud.bean"/>
</typeAliases>
</configuration>
配置好以上最最基本的配置以后,我们需要去建立数据库的表,未来是要从数据库中提取数据进行CRUD的操作。
我们使用的数据库是Mysql,首先创建一个database,名字就叫ssm_crud吧。
然后开始建表的操作,创建一个emp表和dept表。
CREATE TABLE `tbl_dept` (
`dept_id` int(11) NOT NULL AUTO_INCREMENT,
`dept_name` varchar(255) NOT NULL,
PRIMARY KEY (`dept_id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
CREATE TABLE `tbl_emp` (
`emp_id` int(11) NOT NULL AUTO_INCREMENT,
`emp_name` varchar(255) NOT NULL,
`gender` char(1) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`d_id` int(11) DEFAULT NULL,
PRIMARY KEY (`emp_id`),
KEY `fk_emp_dept` (`d_id`),
CONSTRAINT `fk_emp_dept` FOREIGN KEY (`d_id`) REFERENCES `tbl_dept` (`dept_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1006 DEFAULT CHARSET=utf8
创建好以后我们可以随便加一两条数据进入试试。
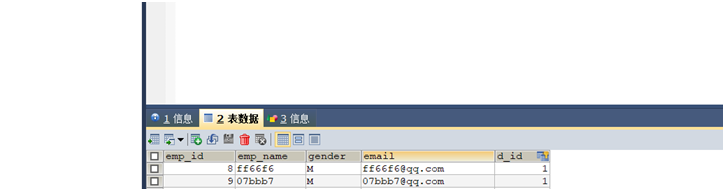
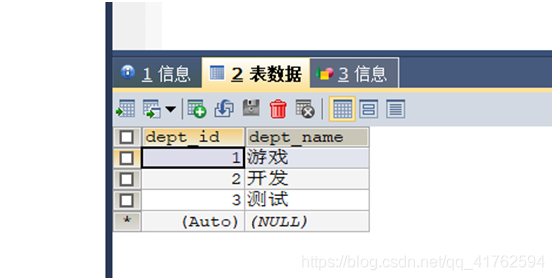
当表设置好以后,我们可以通过mybatis的逆向工程来创建对应的bean和对应的dao信息以及mapper信息。 逆向工程的网址:–>我是网址
可以在网址的Quick Start Guide 中进行找到配置。
这里我们需要引入逆向工程的jar包。
<!-- 逆向工程jar包 MBG -->
<!-- https://mvnrepository.com/artifact/org.mybatis.generator/mybatis-generator-core -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.5</version>
</dependency>
然后导入后需要建立MGB(逆向工程)的xml文件, 我们在ssm-crud的目录下建立xml文件 (这里我的名字错了 大家别介意)。
为这个xml文件取名为mgb.xml。
然后将以下配置的内容都放到mgb.xml中去,配置的来源地址是在 – >我是地址
因为官方有已经完善好的模板,我们直接拿来修改一些内容直接套用就好了。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<classPathEntry location="/Program Files/IBM/SQLLIB/java/db2java.zip" />
<context id="DB2Tables" targetRuntime="MyBatis3">
<jdbcConnection driverClass="COM.ibm.db2.jdbc.app.DB2Driver"
connectionURL="jdbc:db2:TEST"
userId="db2admin"
password="db2admin">
</jdbcConnection>
<javaTypeResolver >
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<javaModelGenerator targetPackage="test.model" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<sqlMapGenerator targetPackage="test.xml" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="test.dao" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<table schema="DB2ADMIN" tableName="ALLTYPES" domainObjectName="Customer" >
<property name="useActualColumnNames" value="true"/>
<generatedKey column="ID" sqlStatement="DB2" identity="true" />
<columnOverride column="DATE_FIELD" property="startDate" />
<ignoreColumn column="FRED" />
<columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" />
</table>
</context>
</generatorConfiguration>

首先我们将刚复制进去的内容的开头 ,这一句话删除。
<classPathEntry location="/Program Files/IBM/SQLLIB/java/db2java.zip" />
然后先将上头的jdbcConnection中的数据源替换成我们自己的配置。代码就不放了哈。
然后修改我们的bean包生成的位置,将javaModelGenerator这个文件中的文件地址修改一下即可。
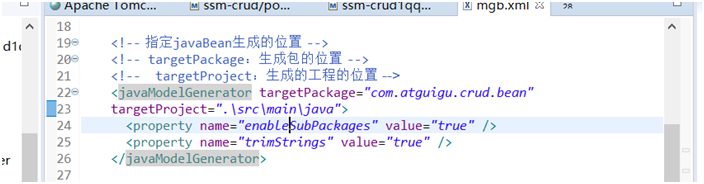
<!-- 指定javaBean生成的位置 -->
<!-- targetPackage:生成包的位置 -->
<!-- targetProject:生成的工程的位置 -->
<javaModelGenerator targetPackage="com.atguigu.crud.bean"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
然后需要指定我们的sql生成位置的映射。在sqlMapGenerator中。

<!-- 指定sql映射文件生成的位置 -->
<sqlMapGenerator targetPackage="mapper"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
之后再指定dao接口生成的位置。在javaClientGenerator配置中。

<!-- 指定dao接口生成的位置,mapper接口 -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.atguigu.crud.dao" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
最后的table指定每个表的生成策略。我们替换原内容,表示数据库表和bean的对应。

<!-- table指定每个表的生成策略 -->
<table tableName="tbl_emp" domainObjectName="Employee"></table>
<table tableName="tbl_dept" domainObjectName="Department"></table>
最后再将这个页的完整代码贴一遍,可以再对照着看一下。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="DB2Tables" targetRuntime="MyBatis3">
<!-- 配置数据库连接 -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/ssm_crud"
userId="root"
password="root">
</jdbcConnection>
<javaTypeResolver >
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- 指定javaBean生成的位置 -->
<!-- targetPackage:生成包的位置 -->
<!-- targetProject:生成的工程的位置 -->
<javaModelGenerator targetPackage="com.atguigu.crud.bean"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- 指定sql映射文件生成的位置 -->
<sqlMapGenerator targetPackage="mapper"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<!-- 指定dao接口生成的位置,mapper接口 -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.atguigu.crud.dao" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<!-- table指定每个表的生成策略 -->
<table tableName="tbl_emp" domainObjectName="Employee"></table>
<table tableName="tbl_dept" domainObjectName="Department"></table>
</context>
</generatorConfiguration>
在将配置文件这样配置好以后,我们就可以让逆向工程帮我们生成mapper.xml,dao等文件了。
首先我们在test文件下生成一个MGB的java文件。
内容如下图所示,主要是将File(“mgb.xml”) 改成刚才设置的文件就ok了 ,然后我们直接main方法运行。
然后刷新一下,就发现需要生成的东西都帮我们生成了。
package com.atguigu.crud.test;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.exception.XMLParserException;
import org.mybatis.generator.internal.DefaultShellCallback;
public class MGB {
public static void main(String[] args) throws Exception {
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
File configFile = new File("mgb.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
myBatisGenerator.generate(null);
}
}
然后我们进入dao层,来到生成的文件,可以发现里面有开发者给我们写的一大堆的配置的注释,我们看的非常乱。所以我们可以选择将这些注释都删除掉。
那当然不能是自己手动的一个个删除,我们选择先将已经生成的文件删除掉,然后重新生成一遍没有注释的。
删掉以后,我们需要修改的仅仅是在mgb.xml中加入一段代码即可,具体在该网址中有–>我的网址
加入这段代码即可。
<commentGenerator>
<property name="suppressAllComments" value="true" />
</commentGenerator>
然后我们来重新生成一遍 ,生成的就是没有注释的了,记得生成了要刷新。
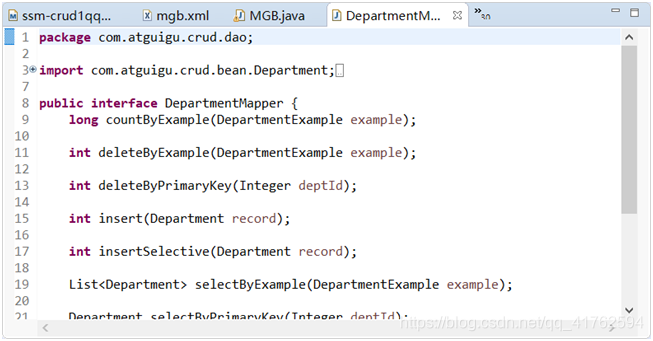
这就大概生成了所有的方法啦,到时候我们可以修改一些我们需要用的。
Mybatis设置
首先我们来到为我们生成的EmployeeMapper.xml,会发现里面的文件非常多,我们可以进行缩小便于整理。
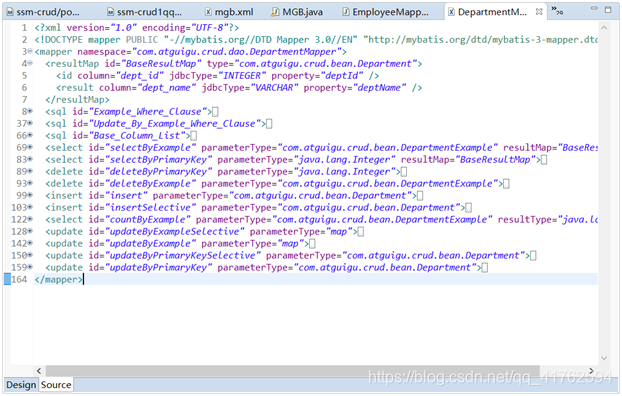
我们查看其中为我们生成的方法,发现少了两个我们需要的方法,根据ID找到Employee连带Department。
那我们来到EmployeeMapper,来自己写一个方法。

//新增兩個
List<Employee> selectByExampleWithDept(EmployeeExample example);
Employee selectByPrimaryKeyWithDept(Integer empId);
然后我们来到Employee,会发现我们的Employee根本没有获取到部门的信息,所以我们也得加上。
所以需要为Employee增加department字段 并且生成get,set方法。
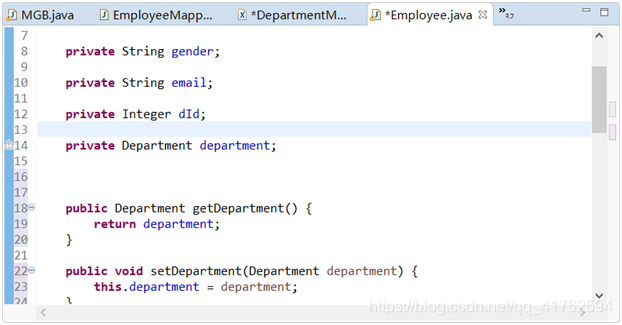
private Department department;
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
定义好了EmployeeMapper 和 bean 那么就需要去定义xml的映射sql语句。
来到EmployeeMapper.xml ,插入下方内容。
<!-- List<Employee> selectByExampleWithDept(EmployeeExample example);
Employee selectByPrimaryKeyWithDept(Integer empId);
-->
<select id="selectByExampleWithDept" >
select
<if test="distinct">
distinct
</if>
<include refid="Base_Column_List" />
from tbl_emp
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
<if test="orderByClause != null">
order by ${
orderByClause}
</if>
</select>
这个之后再进行修改,先进行修改那个Base_Column_List的引用语句,这个语我们查询的属性不一致,并不包含新增加的department。所以我们重新写一个一致的。

<sql id="WithDept_Column_List">
emp_id, emp_name, gender, email, d_id,dept_id,dept_name
</sql>
然后将原来的Base_Column_List 改成我们新定义的id(WithDept_Column_List),然后因为原来的语句是从emp表查询,而我们需要查出department的属性,那就肯定需要联合查询了。
那我这里就直接放代码了.
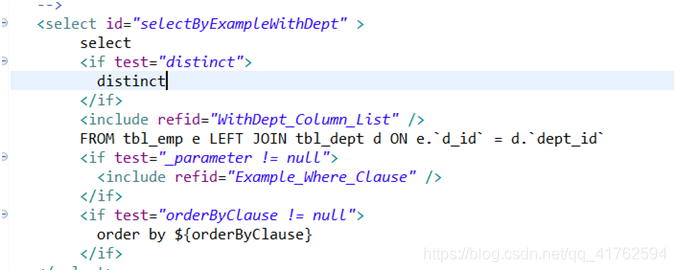
<!-- List<Employee> selectByExampleWithDept(EmployeeExample example);
Employee selectByPrimaryKeyWithDept(Integer empId);
-->
<select id="selectByExampleWithDept" >
select
<if test="distinct">
distinct
</if>
<include refid="WithDept_Column_List" />
FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`d_id` = d.`dept_id`
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
<if test="orderByClause != null">
order by ${
orderByClause}
</if>
</select>
将上述动态sql信息定义好后,还需要定义一个返回的类型,因为我们使用了别名,就使用resultMap来定义返回的Employee对象。
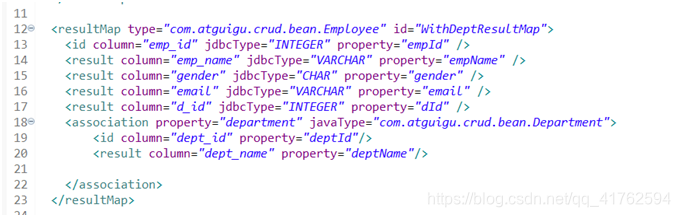
<resultMap type="com.atguigu.crud.bean.Employee" id="WithDeptResultMap">
<id column="emp_id" jdbcType="INTEGER" property="empId" />
<result column="emp_name" jdbcType="VARCHAR" property="empName" />
<result column="gender" jdbcType="CHAR" property="gender" />
<result column="email" jdbcType="VARCHAR" property="email" />
<result column="d_id" jdbcType="INTEGER" property="dId" />
<association property="department" javaType="com.atguigu.crud.bean.Department">
<id column="dept_id" property="deptId"/>
<result column="dept_name" property="deptName"/>
</association>
</resultMap>
然后将定义好的resultMap的id传回之前的select语句。

到这里第一个方法就完成了,然后我们来写第二个方法,根据主键查询,并且将resultMap设为刚才的resultMap的id 其他的都与上一个一样.。
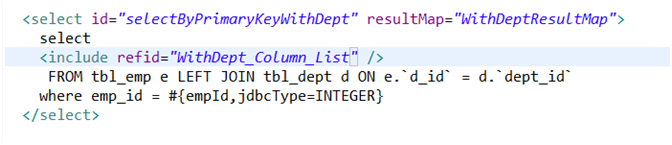
<select id="selectByPrimaryKeyWithDept" resultMap="WithDeptResultMap">
select
<include refid="WithDept_Column_List" />
FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`d_id` = d.`dept_id`
where emp_id = #{
empId,jdbcType=INTEGER}
</select>
然后我们需要的sql方法也就设置好了,可以去写一个测试的方法测试一下效果。
现在test包下建立测试类。
这里我们直接使用Spring的单元测试,则需要导入Spring单元测试的jar包。
<!-- Spring单元测试 -->
<!-- https://mvnrepository.com/artifact/org.springframework/spring-test -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.3.7.RELEASE</version>
<!-- <scope>test</scope> -->
</dependency>
然后使用**@ContextConfiguration这个注解,这个注解代表可以使用Spring测试类**,并制定Spring配置文件的位置。
然后再加上RunWith,表示使用Spring的单元测试模块。
再用@Autowired注解,这里没有标注任何信息则是通过Department这个类去寻找引入,引入我们的Department类。

然后我们如下测试一下,看看我们是否能成功取到Autowired所标注的对象。
如果出现如下就代表成功了。

然后我们要去给department表中插入数据,首先要给department赋值,我们建立一个构造方法来方便赋值,来到department实体类,加上如下构造方法。记得加上有参构造的同时也一定要加上无参构造。
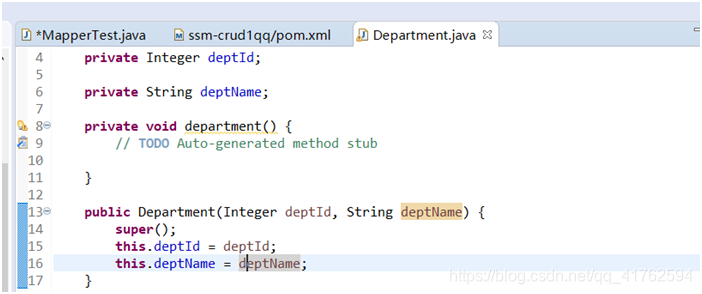
private void department() {
// TODO Auto-generated method stub
}
public Department(Integer deptId, String deptName) {
super();
this.deptId = deptId;
this.deptName = deptName;
}
然后我们开始插入部门信息 ,顺便测试一下数据库是否能成功的插入数据。
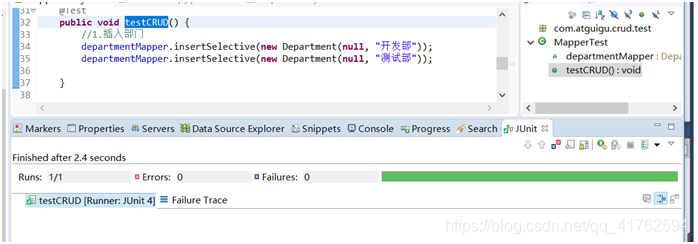
@Test
public void testCRUD() {
//1.插入部门
departmentMapper.insertSelective(new Department(null, "开发部"));
departmentMapper.insertSelective(new Department(null, "测试部"));
}
然后部门插入完毕以后,我们可以插入Employee的具体信息,为了方便,还是一样去Employee实体类增加有参构造和无参构造器。 有参构造器先不要加department。
private void employee() {
// TODO Auto-generated method stub
}
public Employee(Integer empId, String empName, String gender, String email, Integer dId) {
super();
this.empId = empId;
this.empName = empName;
this.gender = gender;
this.email = email;
this.dId = dId;
}
然后我们再插入一条用户信息试试。

@Test
public void testCRUD() {
//1.插入部门
// departmentMapper.insertSelective(new Department(null, "开发部"));
// departmentMapper.insertSelective(new Department(null, "测试部"));
//测试员工插入
employeeMapper.insertSelective(new Employee(null, "sasa", "M", "[email protected]", 1));
}
运行成功后可以去数据库里看看。看看数据是否已经成功插入了。
如果成功了,我们可以进行批量的插入数据。
那么既然要批量的插入数据,那么我们就需要返回applicationContext.xml中去定义可以批量插入的sqlSession了。 其中SqlSessionTemplate 就是跟Spring整合时使用的。

<!-- 配置一个可以执行批量的SqlSession executorType 执行器类型改为批量-->
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"></constructor-arg>
<constructor-arg name="executorType" value="BATCH"></constructor-arg>
</bean>
配置好以后就可以在测试页面注入sqlsession了 。

然后我们来编写代码,使用UUID来插入名字各不相同的用户。

@Test
public void testCRUD() {
//1.插入部门
// departmentMapper.insertSelective(new Department(null, "开发部"));
// departmentMapper.insertSelective(new Department(null, "测试部"));
//测试员工插入
//employeeMapper.insertSelective(new Employee(null, "sasa", "M", "[email protected]", 1));
// for() {
// employeeMapper.insertSelective(new Employee(null, empName, gender, email, dId))
// }
//只有通过sqlSession来插入才是批量 直接for循环那就不是批量插入了
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
for(int i=0;i<1000;i++) {
String uid = UUID.randomUUID().toString().substring(0,5)+i;
mapper.insertSelective(new Employee(null, uid, "M", uid+"@qq.com", 1));
}
}
如下是成功插入的效果图:

到这基本所有的配置,以及数据库的设置都已经完成了,剩下的就是正式开工做项目了!
分页查询
在成功的测试了Departmentmapper的功能与在EmployeeMapper中插入1000条数据后,我们可以正式的开始写项目类。首先要完成的是一个分页的操作,首先我们要进入员工信息表格的话 需要先将员工的信息全部查找出来放在页面上,需要一个通道进入controller查找,于是我们将index.jsp改造一下,变成一个跳板,去到我们的Controller。

在将index.jsp设置好跳板后,我们就需要写一个后续接收的地方(controller)层。
新建一个EmployeeController类

在设置好以后进入,因为这是要接收页面通过Springmvc的请求,之前在SpringMVC中标注了只扫描@Controller的包,那么就给这个class标注@Controller。
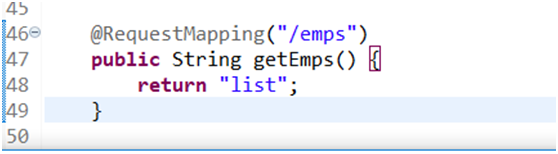
标注好后,我们需要写一个方法来接收之前传输来的/emp请求,创建一个getEmps方法 并标注@RequestMapping(“/emps”)接收页面传来的指令。
然后我们要去数据库中获取员工的信息,所以我们要去Service层进行数据库操作,在service中创建一个EmployeeService。

创好以后先给EmployeeService标注上@Service注解,表示被Spring扫描,之后需要引用EmployeeMapper来进行引用dao层方法进行数据库操作。
通过@Autowired引入EmployeeMapper的bean对象。

然后建立一个查询所有员工的方法。暂时先标注为null,代表返回表中所有的信息。

所以现在EmployeeService的样子是这样的。

然后就回到EmployeeController,在上方引入EmployeeService,也是加@Autowired。

并使用getAll()方法,用一个List接收传输过来的表信息。
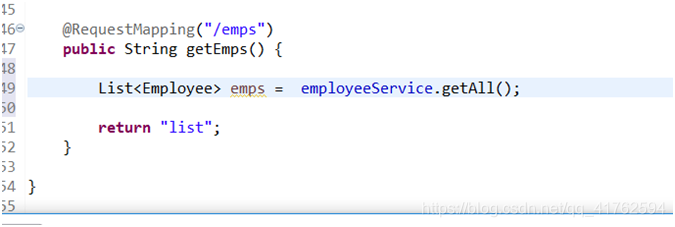
但是由于我们做的是分页查询,需要对每一页进行判别,参数会传来需要获取哪一页的信息,于是我们需要在getEmps()中写入可能会传来的参数,并赋给一个值。

再然后我们可以通过分页的插件对分页进行处理,这时需要引入PageHelper插件,通过插件来帮我们进行数据的分页,会比我们自己手动精确并且稳定一些。
所以来到pom.xml。

<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.0.0</version>
</dependency>
传入后保存加载,回到EmployeeController。
这时就可以引用传入的插件了,首先在查询之前先调用startPage() 传入页码以及每页需要多少的数据,我们规定为5.

然后要注意了,这个分页查询的PageHelper的下一行一定是分页数据(就是从service传回来的所有表信息),之后我们通过new一个PageInfo对查询后的结果进行包装,只需要将pageInfo交给页面就行了
PageInfo(emps,num) 将查询后的结果传入,num代表一个页码连续显示几页 比如传入的是第3页,那么就从3开始连续显示num页。
最后用model接收这个pageinfo, 这时要在参数处传入Model model 。

最后将model传到request请求中。
最后的页面是这样的:

好的,当我们已经将分页的步骤基本设计好以后,那么就先去测试中测试一下。在test包下建立一个MvcTest.

当我们建好以后,还是跟上次一样通过Spring进行测试 那么先引入注解.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = {
"classpath:applicationContext.xml","file:src/main/webapp/WEB-INF/dispatcherServlet-servlet.xml"})
因为这次我们测试用到了Springmvc ,所以需要它的配置文件,我们也顺带一起引入.
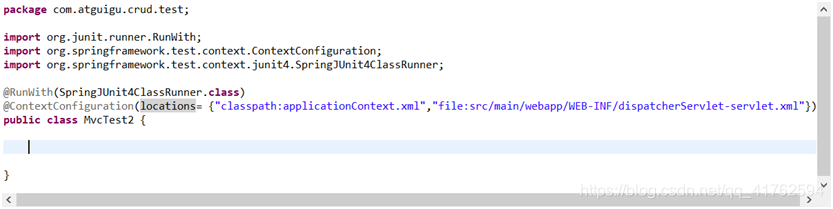
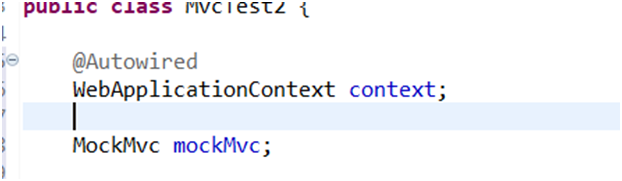
引入后,因为我们这次要配合SpringMVC一起测试,那么先传入SpringMvc的ioc WebApplicationContext,然后虚拟MVC请求并获取处理结果,在这里我们使用MockMvc(详细见图)
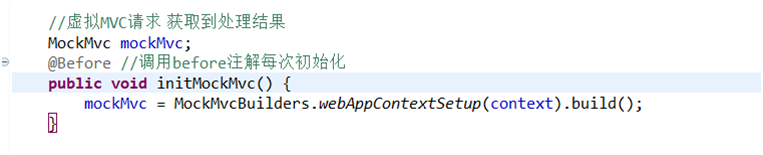
然后我们写一个初始化MockMvc的方法。
建立好后呢,我们就可以开始写Test方法 ,首先 先建立一个testPage方法并标注@Test。
然后在方法中设置MvcResult,result用来接收处理的结果,并使用刚初始化的mockMvc执行模拟进入**/emps**,并传入参数pn为1的参数返回。

在获取之后 创建一个MockHttpServletRequest request 获取结果中的请求信息。
然后再从请求信息中获取pageInfo。

(之前忘了一个在initMockMvc前加上一个@Before注解表示最先执行,记住引入的是测试的包)
并且在类上方加入@WebAppConfiguration注解表示传入web ioc容器。
做到这一步后,之后就是从pageInfo中获取信息啦,就不一一阐述了,直接上图。
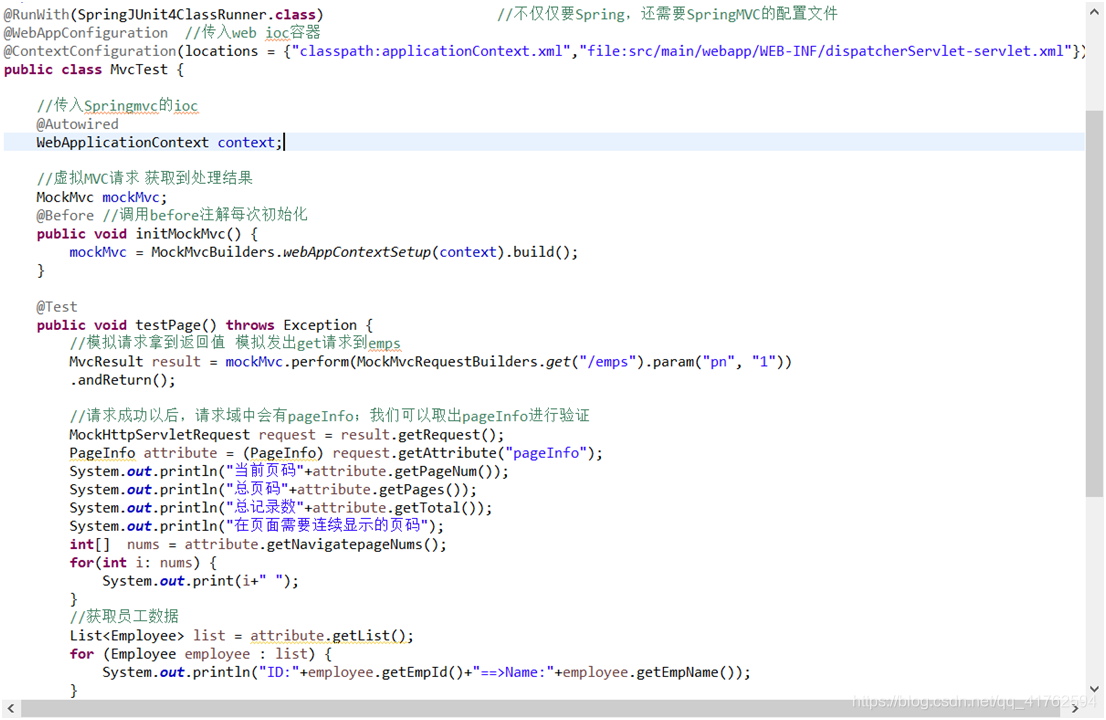
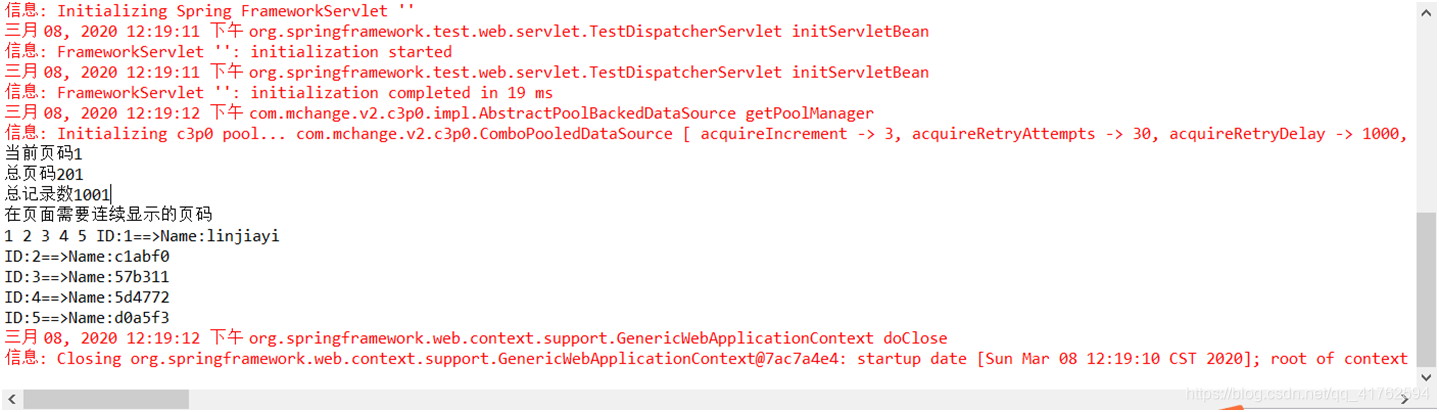
输出的结果是这样的 ,我们的测试也就完成了!
剩下的内容就下一期上吧!应该还有两期…