7. 长短期记忆(LSTM)
本节将介绍另一种常用的门控循环神经网络:长短期记忆(long short-term memory,LSTM)。
它比门控循环单元的结构稍微复杂一点。
7.1 概念
LSTM 中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。
7.1.1 输入门、遗忘门和输出门
与门控循环单元中的重置门和更新门一样,长短期记忆的门的输入均为当前时间步输入 X t \boldsymbol{X}_t Xt与上一时间步隐藏状态 H t − 1 \boldsymbol{H}_{t-1} Ht−1,输出由激活函数为sigmoid函数的全连接层计算得到。由此,这3个门元素的值域均为 [ 0 , 1 ] [0,1] [0,1]。如下图所示:

具体来说,假设隐藏单元个数为 h h h,给定时间步 t t t的小批量输入 X t ∈ R n × d \boldsymbol{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d(样本数为 n n n,输入个数为 d d d)和上一时间步隐藏状态 H t − 1 ∈ R n × h \boldsymbol{H}_{t-1} \in \mathbb{R}^{n \times h} Ht−1∈Rn×h。 时间步 t t t的输入门 I t ∈ R n × h \boldsymbol{I}_t \in \mathbb{R}^{n \times h} It∈Rn×h、遗忘门 F t ∈ R n × h \boldsymbol{F}_t \in \mathbb{R}^{n \times h} Ft∈Rn×h和输出门 O t ∈ R n × h \boldsymbol{O}_t \in \mathbb{R}^{n \times h} Ot∈Rn×h分别计算如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) F t = σ ( X t W x f + H t − 1 W h f + b f ) O t = σ ( X t W x o + H t − 1 W h o + b o ) \begin{aligned} \boldsymbol{I}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xi} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hi} + \boldsymbol{b}_i) \\ \boldsymbol{F}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xf} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hf} + \boldsymbol{b}_f) \\ \boldsymbol{O}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xo} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{ho} + \boldsymbol{b}_o) \end{aligned} ItFtOt=σ(XtWxi+Ht−1Whi+bi)=σ(XtWxf+Ht−1Whf+bf)=σ(XtWxo+Ht−1Who+bo)
其中, W x i \boldsymbol{W}_{xi} Wxi 、 W x f \boldsymbol{W}_{xf} Wxf、 W x o ∈ R d × h \boldsymbol{W}_{xo} \in \mathbb{R}^{d \times h} Wxo∈Rd×h和 W h i \boldsymbol{W}_{hi} Whi、 W h f \boldsymbol{W}_{hf} Whf 、 W h o ∈ R h × h \boldsymbol{W}_{ho} \in \mathbb{R}^{h \times h} Who∈Rh×h是权重参数, b i \boldsymbol{b}_i bi、 b f \boldsymbol{b}_f bf、 b o ∈ R 1 × h \boldsymbol{b}_o \in \mathbb{R}^{1 \times h} bo∈R1×h是偏差参数。
7.1.2 候选记忆细胞
长短期记忆需要计算候选记忆细胞 C ~ t \tilde{\boldsymbol{C}}_t C~t。其计算与上述的3个门类似,但使用了值域在 [ − 1 , 1 ] [-1, 1] [−1,1]的tanh函数作为激活函数,如下图所示:
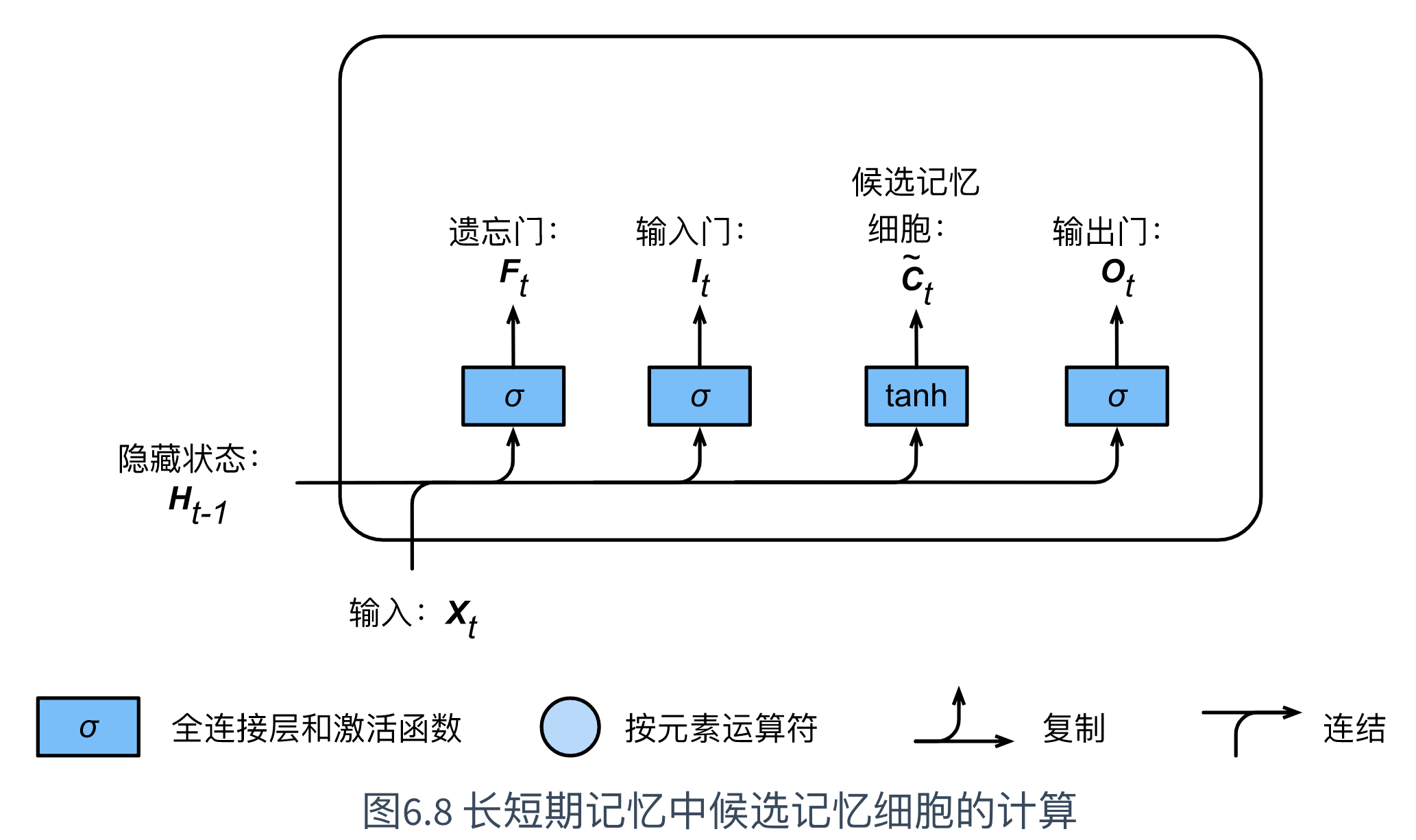
具体来说,时间步 t t t的候选记忆细胞 C ~ t ∈ R n × h \tilde{\boldsymbol{C}}_t \in \mathbb{R}^{n \times h} C~t∈Rn×h的计算为:
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \tilde{\boldsymbol{C}}_t = \text{tanh}(\boldsymbol{X}_t \boldsymbol{W}_{xc} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hc} + \boldsymbol{b}_c) C~t=tanh(XtWxc+Ht−1Whc+bc)
其中, W x c ∈ R d × h \boldsymbol{W}_{xc} \in \mathbb{R}^{d \times h} Wxc∈Rd×h和 W h c ∈ R h × h \boldsymbol{W}_{hc} \in \mathbb{R}^{h \times h} Whc∈Rh×h为权重参数, b c ∈ R 1 × h \boldsymbol{b}_c \in \mathbb{R}^{1 \times h} bc∈R1×h为偏差参数。
7.1.3 记忆细胞
可以通过元素值域在 [ 0 , 1 ] [0, 1] [0,1]的输入门、遗忘门和输出门来控制隐藏状态中信息的流动,这一般是通过使用按元素乘法(符号为 ⊙ \odot ⊙)来实现的。
当前时间步记忆细胞 C t ∈ R n × h \boldsymbol{C}_t \in \mathbb{R}^{n \times h} Ct∈Rn×h的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门来控制信息的流动:
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t \boldsymbol{C}_t = \boldsymbol{F}_t \odot \boldsymbol{C}_{t-1} + \boldsymbol{I}_t \odot \tilde{\boldsymbol{C}}_t Ct=Ft⊙Ct−1+It⊙C~t

如上图所示,遗忘门控制上一时间步的记忆细胞 C t − 1 \boldsymbol{C}_{t-1} Ct−1中的信息是否传递到当前时间步,而输入门则控制当前时间步的输入 X t \boldsymbol{X}_t Xt通过候选记忆细胞 C ~ t \tilde{\boldsymbol{C}}_t C~t如何流入当前时间步的记忆细胞。
若遗忘门一直近似1且输入门一直近似0,过去的记忆细胞将一直通过时间保存并传递至当前时间步。
该设计可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
7.1.4 隐藏状态
有了记忆细胞之后,可以通过输出门来控制从记忆细胞到隐藏状态 H t ∈ R n × h \boldsymbol{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h的信息的流动:
H t = O t ⊙ tanh ( C t ) \boldsymbol{H}_t = \boldsymbol{O}_t \odot \text{tanh}(\boldsymbol{C}_t) Ht=Ot⊙tanh(Ct)
其中,tanh函数确保隐藏状态元素值在-1到1之间。
长短期记忆中隐藏状态的计算,具体如下图所示:
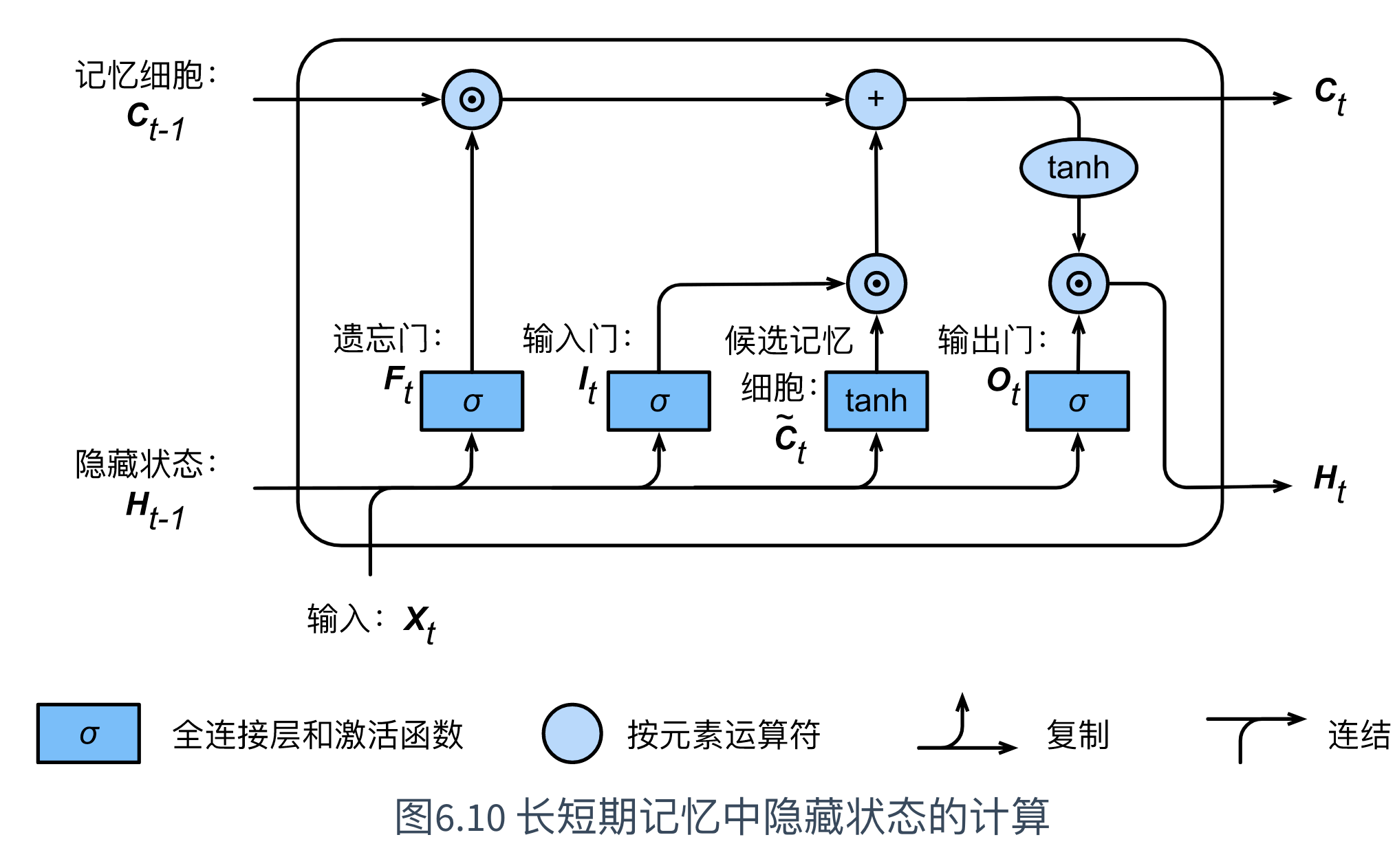
值得注意的是,
当输出门近似1时,记忆细胞信息将传递到隐藏状态供输出层使用;
当输出门近似0时,记忆细胞信息仅自己保留。
7.2 代码示例
7.2.1 读取数据集
为了实现并展示长短期记忆,依然使用周杰伦歌词数据集来训练模型作词。
读取数据集,依然有代码示例如下:
import tensorflow as tf
from tensorflow import keras
import time
import math
import sys
import numpy as np
import d2lzh_tensorflow2 as d2l
def load_data_jay_lyrics():
"""加载周杰伦歌词数据集"""
import zipfile
with zipfile.ZipFile('./data/jaychou_lyrics.txt.zip') as zin:
with zin.open('jaychou_lyrics.txt') as f:
corpus_chars = f.read().decode('utf-8')
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices, char_to_idx, idx_to_char, vocab_size
(corpus_indices, char_to_idx, idx_to_char,vocab_size) = load_data_jay_lyrics()
7.2.2 简洁实现
使用 循环神经网络 小节已封装的函数:
class RNNModel(tf.keras.layers.Layer):
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.dense = tf.keras.layers.Dense(units=vocab_size)
def call(self, inputs, state):
# 将输入转置为(num_steps, batch_size),再进行one-hot向量表示
X = tf.one_hot(indices=tf.transpose(inputs), depth=self.vocab_size)
Y, state = self.rnn(X, state)
# Y先reshape to (num_steps * batch_size, num_hiddens),再过dense层
# 最终输出形状: (num_steps * batch_size, vocab_size)
output = self.dense(tf.reshape(Y, shape=(-1, Y.shape[-1])))
return output, state
def get_initial_state(self, *args, **kwargs):
return self.rnn.cell.get_initial_state(*args, **kwargs)
def predict_rnn_keras(prefix, num_chars, model, vocab_size, idx_to_char, char_to_idx):
# 使用model的成员函数来初始化隐藏状态
state = model.get_initial_state(batch_size=1, dtype=tf.float32)
output = [char_to_idx[prefix[0]]]
for t in range(len(prefix)+num_chars-1):
X = np.array([output[-1]]).reshape((1, 1))
Y, state = model(X, state)
if t < len(prefix)-1:
output.append(char_to_idx[prefix[t+1]])
else:
# 取Y中max值
output.append(int(np.array(tf.argmax(Y, axis=-1))))
return ''.join([idx_to_char[i] for i in output])
def grad_clipping(grads, theta):
norm = np.array([0])
for i in range(len(grads)):
norm += tf.reduce_sum(grads[i]**2)
norm = np.sqrt(norm).item()
new_gradients = []
if norm > theta:
for grad in grads:
new_gradients.append(grad*theta/norm)
else:
for grad in grads:
new_gradients.append(grad)
return new_gradients
def train_and_predict_rnn_keras(model, num_hiddens, vocab_size,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
import time
import math
loss = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.SGD(learning_rate=lr)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
# 相邻采样
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps)
state = model.get_initial_state(batch_size=batch_size, dtype=tf.float32)
for X, Y in data_iter:
with tf.GradientTape(persistent=True) as tape:
(outputs, state) = model(X, state)
y = Y.T.reshape((-1, ))
l = loss(y, outputs)
grads = tape.gradient(l, model.variables)
# 梯度裁剪
grads = grad_clipping(grads, clipping_theta)
optimizer.apply_gradients(zip(grads, model.variables))
l_sum += np.array(l).item()*len(y)
n += len(y)
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (epoch+1, math.exp(l_sum/n), time.time()-start))
for prefix in prefixes:
print(' -', predict_rnn_keras(prefix, pred_len, model, vocab_size, idx_to_char, char_to_idx))
调用tf.keras中的layers模块中的LSTM类:
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e-2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lstm_layer = keras.layers.LSTM(units=num_hiddens,time_major=True,return_sequences=True,return_state=True)
model = RNNModel(lstm_layer, vocab_size)
train_and_predict_rnn_keras(model, num_hiddens, vocab_size,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
- [记] 代码报错。ValueError: too many values to unpack (expected 2)