DataNode工作机制
NameNode & DataNode工作机制
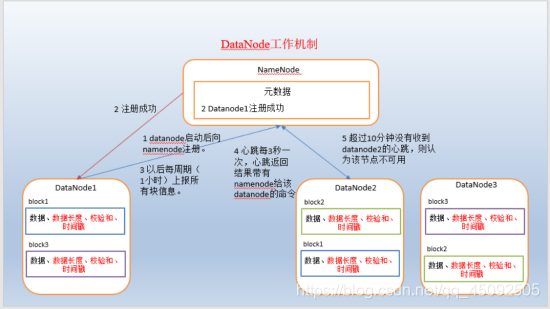 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
数据完整性
1)当DataNode读取block的时候,它会计算checksum校验和
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum校验和
掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
DataNode的目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
- 在/opt/module/hadoop-2.8.4/data/dfs/data/current这个目录下查看版本号
[dingshiqi@bigdata111 current]$ cat VERSION
storageID=DS-1b998a1d-71a3-43d5-82dc-c0ff3294921b
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
datanodeUuid=970b2daf-63b8-4e17-a514-d81741392165
storageType=DATA_NODE
layoutVersion=-56
-
具体解释
(1)storageID:存储id号
(2)clusterID集群id,全局唯一
(3)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文 件系统升级之后,该值会更新到新的时间戳。
(4)datanodeUuid:datanode的唯一识别码
(5)storageType:存储类型
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
-
在/opt/module/hadoop-2.8.4/data/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current这个目录下查看该数据块的版本号
[dingshiqi@bigdata111 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
namespaceID=1933630176
cTime=0
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-56
具体解释
1)namespaceID:是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可用这个属性来区分不同datanode。
(2)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(3)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的
BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(4)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
DataNode多目录配置
datanode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
具体配置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${
hadoop.tmp.dir}/dfs/data1,file:///${
hadoop.tmp.dir}/dfs/data2</value>
</property>
HDFS其他功能
集群间数据拷贝
- scp实现两个远程主机之间的文件复制
- scp -r hello.txt root@bigdata111:/user/itstar/hello.txt // 推 push
scp -r root@bigdata112:/user/itstar/hello.txt hello.txt // 拉 pull
scp -r root@bigdata112:/opt/module/hadoop-2.8.4/LICENSE.txt root@bigdata113:/opt/module/hadoop-2.8.4/LICENSE.txt
//是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
采用discp命令实现两个hadoop集群之间的递归数据复制(注:不用设置其他,直接写IP)
bin/hadoop distcp hdfs://192.168.1.51:9000/LICENSE.txt hdfs://192.168.1.111:9000/HAHA
Hadoop(不适合存储小文件)存档
-
理论概述
每个文件均按块存储,每个块的元数据存储在namenode的内存中,因此hadoop存储小文件会非常低效。因为大量的小文件会耗尽namenode中的大部分内存。但注意,存储小文件所需要的磁盘容量和存储这些文件原始内容所需要的磁盘空间相比也不会增多。例如,一个1MB的文件以大小为128MB的块存储,使用的是1MB的磁盘空间,而不是128MB。
Hadoop存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少namenode内存使用的同时,允许对文件进行透明的访问。具体说来,Hadoop存档文件可以用作MapReduce的输入。
https://www.cnblogs.com/staryea/p/8603112.html
-
案例实操
-
需要启动yarn进程
start-yarn.sh -
归档文件
归档成一个叫做xxx.har的文件夹,该文件夹下有相应的数据文件。Xx.har目录是一个整体,该目录看成是一个归档文件即可。
 - 用法:hadoop archive -archiveName 归档名称 -p 父目录 [-r <复制因子>] 原路径(可以多个) 目的路径
- 用法:hadoop archive -archiveName 归档名称 -p 父目录 [-r <复制因子>] 原路径(可以多个) 目的路径
bin/ hadoop archive -archiveName foo.har -p /Andy -r 3 a b c / -
-
查看归档
hadoop fs -lsr /user/my/myhar.har hadoop fs -lsr har:///myhar.har
 - - 解归档文件
- - 解归档文件取消存档:hadoop fs -cp har:/// user/my/myhar.har /* /user/itstar 并行解压缩:hadoop distcp har:/foo.har /001
快照管理
快照相当于对目录做一个备份。并不会立即复制所有文件,而是指向同一个文件。当写入发生时,才会产生新文件。
-
基本语法
hdfs dfsadmin -allowSnapshot 路径 (功能描述:开启指定目录的快照功能) hdfs dfsadmin -disallowSnapshot 路径 (功能描述:禁用指定目录的快照功能,默认是禁用) hdfs dfs -createSnapshot 路径 (功能描述:对目录创建快照) hdfs dfs -createSnapshot 路径 名称 (功能描述:指定名称创建快照) hdfs dfs -renameSnapshot 路径 旧名称 新名称 (功能描述:重命名快照) hdfs lsSnapshottableDir (功能描述:列出当前用户所有已快照目录) hdfs snapshotDiff 路径1 路径2 (功能描述:比较两个快照目录的不同之处) hdfs dfs -deleteSnapshot <path> <snapshotName> (功能描述:删除快照) -
案例实操
(1)开启/禁用指定目录的快照功能 hdfs dfsadmin -allowSnapshot /user/itstar/data hdfs dfsadmin -disallowSnapshot /user/itstar/data (2)对目录创建快照 hdfs dfs -createSnapshot /user/itstar/data // 对目录创建快照 用相同数据块 hdfs dfs -lsr /user/itstar/data/.snapshot/ (3)指定名称创建快照 hdfs dfs -createSnapshot /user/itstar/data miao170508 (4)重命名快照(注:快照是只读的,无法修改名) 快照的目录 老快照的名字 新快照的名字 hdfs dfs -renameSnapshot /Andy/ andy bndy 注:路径只是你创建得名字/Andy,不要带后边得/Andy/.snapshot/,不然会出现 renameSnapshot: Modification on a read-only snapshot is disallowed (5)列出当前用户所有可快照目录 hdfs lsSnapshottableDir (6)比较两个快照目录的不同之处 快照的名字 之前的快照名字 新快照的名字 hdfs snapshotDiff /user/itstar/data/ plus plus1 (7)恢复快照 1.自定义创建一个快照名:hdfs dfs -createSnapshot /HAHA1 miaomiao 2.展示原文件包含内容:Hadoop fs -ls /HAHA1 3.里面有五个文件、删除其中1~2个 4.回复快照:hdfs dfs -cp /HAHA1/.snapshot/miaomiao1 /miaomiao (8)删除快照 hdfs dfs -deleteSnapshot /001名字
回收站
-
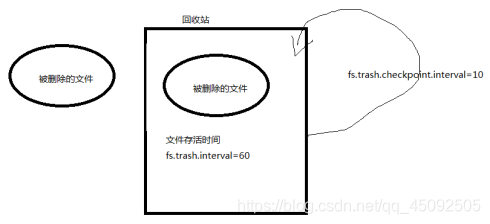
默认回收站
默认值fs.trash.interval=0,0表示禁用回收站,可以设置删除文件的存活时间。
默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。
要求fs.trash.checkpoint.interval<=fs.trash.interval。
 - 启用回收站
- 启用回收站修改core-site.xml,配置垃圾回收时间为1分钟。
<property> <name>fs.trash.interval</name> <value>1</value> </property> -
查看回收站
回收站在集群中的;路径:/user/itstar/.Trash/….
-
修改访问垃圾回收站用户名称
进入垃圾回收站用户名称,默认是dr.who,修改为itstar用户
#core-site.xml <property> <name>hadoop.http.staticuser.user</name> <value>itstar</value> </property> -
通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf); trash.moveToTrash(path); -
恢复回收站数据
hadoop fs -mv /user/itstar/.Trash/Current/user/itstar/input /user/itstar/input -
清空回收站
hdfs dfs -expunge