一般地,贝叶斯算法可用于新闻分类,文本分类以及邮件分类
贝叶斯统计学方法 = 总体信息 + 样本信息 + 先验信息
- 总体信息:当前总体样本符合某种分布。比如抛硬币,二项分布。学生某一科的成绩符合正态分布
- 样本信息:通过抽样得到的部分样本的某种分布。
- 先验信息:抽样之前,有关推断问题中位置参数的一些信息,通常来源于经验或历史资料(比如让一个音乐家猜某歌曲的作者和让一个小学生猜某歌曲的作者,音乐家具有先验信息)
古典学派和贝叶斯学派的矛盾:是否承认先验知识
贝叶斯定理:

对公式的分析: 后验概率 = 先验概率 * 调整因子
- 如果 调整因子>1 ,意味着’先验概率’被增强,事件A的发生的可能性变大;
- 如果 调整因子=1 ,意味着B事件无助于判断事件A的可能性;
- 如果 调整因子<1 ,意味着"先验概率"被削弱,事件A的可能性变小
在邮件分类的应用中:
- P(A):是垃圾邮件的概率
- P(B):带有某特征的邮件的概率
- P(A|B):已知一封邮件具有某特征,该邮件为垃圾邮件的概率
朴素贝叶斯:
X1,X2,…,Xn之间相互独立,则
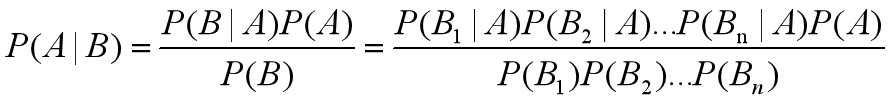
我们大脑中也是有贝叶斯算法的:

在Line1中,由于我们的大脑认识A、C,存在先验信息,因此我们会把Line1的图案当作字母“B”。而Line2中,由于两侧是12、14,我们的大脑会帮我们把图案理解为数字“13”。由于有了“样本信息”和“先验信息”,我们会将相同的图案理解为不同的含义。
利用朴素贝叶斯进行文档分类
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def navieBayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割,分成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tfidf = TfidfVectorizer()
# 抽取训练集的特征,x_train由文本变成特征矩阵
x_train = tfidf.fit_transform(x_train)
print(tfidf.get_feature_names())
print('训练集统计结果为:', x_train.toarray())
# x_train由文本变成特征矩阵
x_test = tfidf.transform(x_test)
# 实例化朴素贝叶斯对象,alpha表示拉普拉斯平滑系数,确保概率不为0
mlt = MultinomialNB(alpha=1.0)
# 将训练集的特征值和目标值传入API进行计算,计算每个词在特定类别文章中出现的次数
mlt.fit(x_train, y_train)
# 给测试数据,得到文章分类的预测结果
y_predict = mlt.predict(x_test)
print('预测的文章类别为:', y_predict)
# 得出准确率
print('准确率为:',mlt.score(x_test, y_test))
if __name__ == '__main__':
navieBayes()
朴素贝叶斯的优缺点
优点:
- 朴素贝叶斯发源于古典数学理论,有稳定的分类效率
- 对缺失数据不敏感,算法较简单,常用于文本分类
- 分类准确度高,速度快
缺点:
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联试效果不好