What is a graph?
图的结构如下图所示
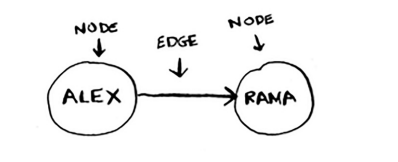
图由node和edge组成,一个node可利用edge与其他node连结,连结的node称为当前node的neighbors,
下图中,rama为alex的neighbor,而adit不是alex的neighbor

Breadth-frst search
以芒果售卖为例子,你需要在你的朋友中找到芒果售卖商,你找你的朋友,bob,Alice,Claire,看看他们是否售卖芒果,如下图所示,很有可能你的朋友们都不售卖芒果

这时候改变思路, 不仅联系你的朋友,还联系你朋友的朋友,范围非常广

算法流程为:联系你的一个朋友Alice,假如他售卖芒果就结束,else:把所有alice的朋友的名字增加进搜索列表

Finding the shortest path
Breadth-frst search算法会给你两个结果

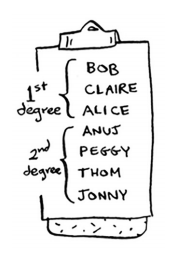
现在定义frst-degree connections 和second-degree connections,以芒果售卖为例
first-degree connections:和你直接关联的朋友
second-degree connections: 你朋友的朋友
在算法搜寻过程中,先搜寻first-degree connections,然后在搜寻second-degree connections,如下图所示,先搜寻BOB,再搜寻ANUJ

搜索顺序写成表的形式,就像下面这样
一定要以先first-degree 再second-degree的顺序来进行搜寻,否则求出的路径不会是最短路径。
Queues
queue(队列):不能随机读取队列中的任意元素,只有两种操作,enqueue和dequeue,如下图所示
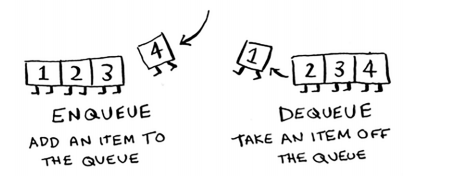
queue的特点是FIFO,first in , first out
stack的特点是LILO,last in, last out (详情见第3章的递归)
Implementing the graph
可以用哈希表,也就是Python中的字典对下图进行表述:

graph = {}
graph[“you”] = [“alice”, “bob”, “claire”]
graph[“bob”] = [“anuj”, “peggy”]
graph[“alice”] = [“peggy”]
graph[“claire”] = [“thom”, “jonny”]
graph[“anuj”] = []
graph[“peggy”] = []
graph[“thom”] = []
graph[“jonny”] = []因为哈希表不care顺序,所以以下的表达也是成立的

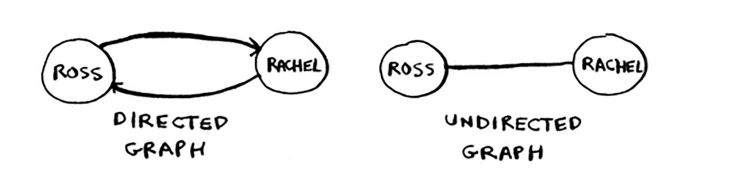
如上图所示,Anuj这个节点,有一个箭头指向他,然而,这个节点却没有箭头指向其他地方,这种单项关系叫有向图(directed graph),因此Anuj是rob的邻居,然而,rob却不是Anuj的邻居。无向图(undirected graph)没有箭头,因此两个节点都是各自的邻居,如下图所示,下图是等价的
Implementing the algorithm
执行细节,如下图所示

代码实现,把'you'的邻居都增加进queue中
from collections import deque
search_queue = deque()
search_queue += graph[“you”]搜寻过程的伪代码如下所示:

在添加邻居的时候,需要检查这位邻居以前有没有被添加过,否则会造成死循环。
最终代码如下所示

例子

上图,做的顺序可以是

也可以是

在举一个例子

因为dressed依赖于shower,因此,只要dressed在shower后面就可以,dressed和brush teeth没有依赖关系,所以排列的位置可以任意。
树 的定义:没有edge point back(edge不会返回到上一个节点),是一种特殊的图

本章要点
