集合中我们经常使用的就是hashmap,我们知道它的底层实现是hash桶外加链表的方式来进行存储数据的,但是底层又是如何进行具体实现的,我们可能真的说不清除。现在我们从源码层次上进行讲解hashmap的原理;
-
get方法的底层实现
先看下源码

我们传入key的参数,底层调用的是getNode的方式,其中最重要的就是对我们传入的key进行了hash算法的处理,那么hash算法又是如何实现的哪,继续源码刨析

首先判断了key是否为空,空的话返回0;非空的话使用key的hashcode的高16位和低16位做异或运算;那么为什末要这样设计哪?这样更容易保留目标值的信息 减少碰撞。
再看getNode是如何获取结点信息的
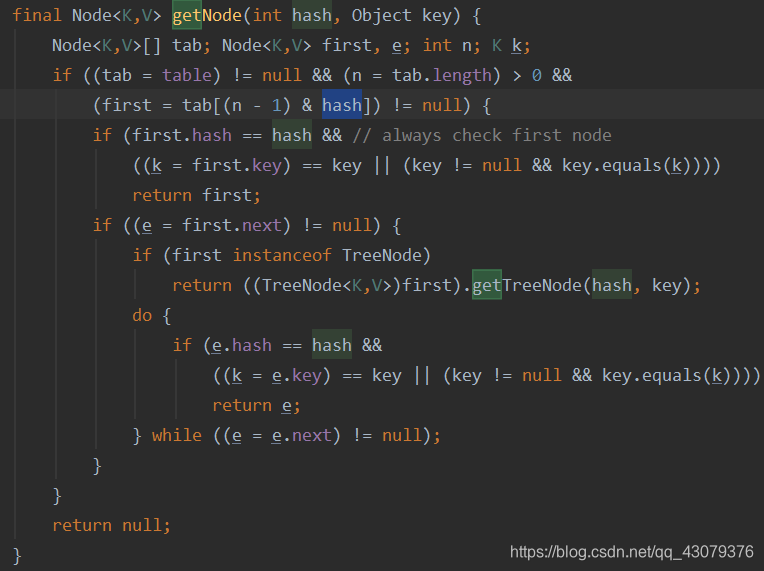
经过hash算法得到的hash值在hash桶里面与(length-1)进行相与处理得到k值所在的桶,里面的if判断语句,如果头节点的key和所要查询的key一样的话就返回头节点,如果不相等的话,判断头节点的next结点,是否是TreeNode的结点,是的话按照TreeNode的查询方式进行查询,如果不是的话是按照链表的方式进行查询结点; -
hashmap的核心扩容机制
主要的两个方法就是resize和rehash方法,hashmap默认的初始容量是16,初始的负载因子是0.75f源码如下

负载因子的概念:当数组的容量被使用75%以上的时候就会进行扩容; -
为什末每次hashmap扩容时是乘2
主要是在取模的时候做优化,cap %16 = cap & 15 因为取模的运算是比较耗时的,而按位与运算效率是很高的,
比如cap=32时,cap%16 =0 ,cap & 15 = 0 相同的结果 后者的运算速度更快 -
hashmap的线程安全问题?
hashmap是线程不安全的,我们通过源码可以看出来,它的put操作没有使用synchroized进行同步处理的