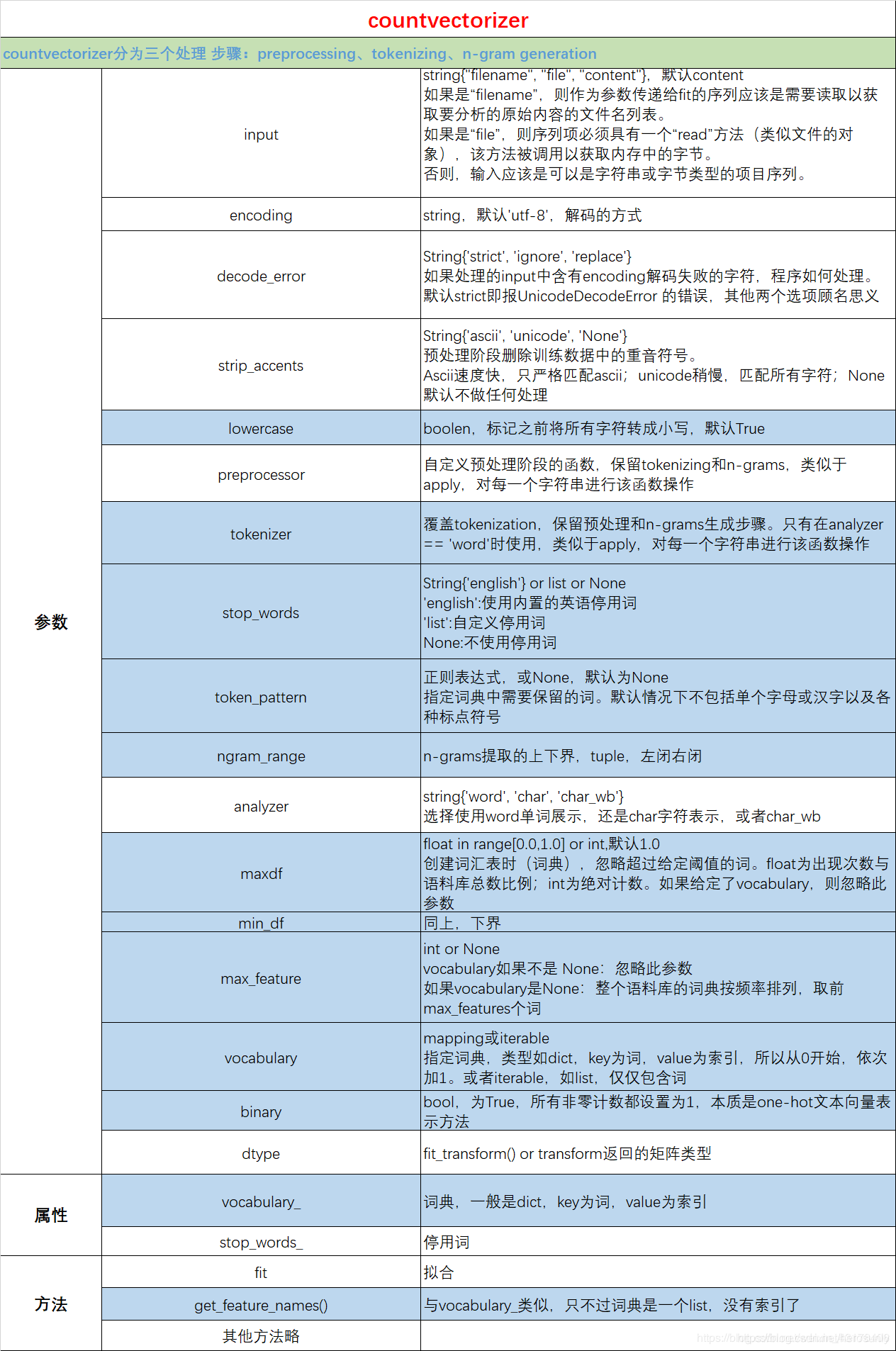
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['a fine cut', '他 喜欢 动物']
vectorizer = CountVectorizer(binary=False, analyzer='word', vocabulary=['a', '他', '喜欢'], stop_words=['a'])
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
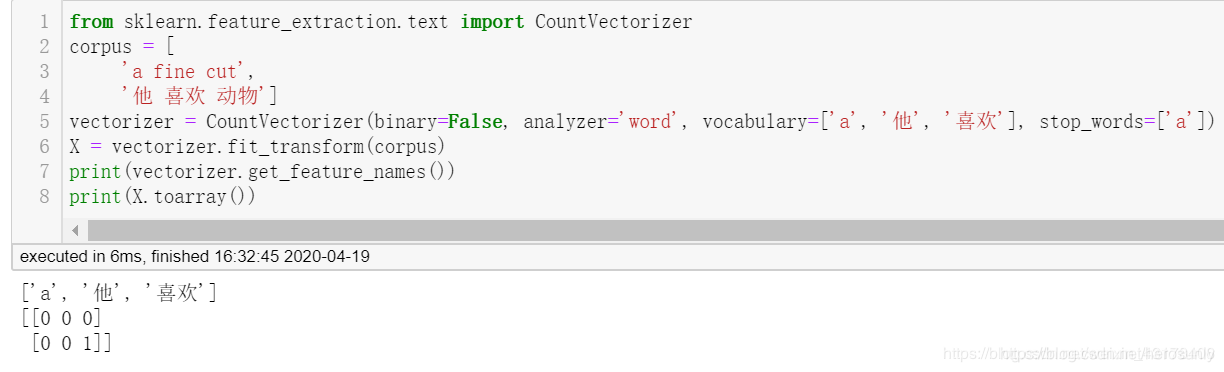
- 指定vocabulary,此时tokenizer/token_pattern/stop_words/max_df等都无效,即和分词有关的参数都无效。可以看到最终生成的词典只有我们参数中指定的a/他/喜欢
为什么会这样呢?我们去研究一下源代码(sklearn/feature_extraction/text.py):
其中CountVectorizer中的fit_transform的源代码如下所示,需要重点关注的是 self._validate_vocabulary()和self.count_vocab(raw_documents,self.fixed_vocabulary)
def fit_transform(self, raw_documents, y=None):
if isinstance(raw_documents, six.string_types):
raise ValueError(
"Iterable over raw text documents expected, "
"string object received.")
self._validate_params() # 确保n-gram的两个输入值的大小关系正确
self._validate_vocabulary() # 如果输入参数包含vocabulary,则使self.fixed_vocabulary_ = True和self.vocabulary_ = dict(vocabulary)
max_df = self.max_df
min_df = self.min_df
max_features = self.max_features
vocabulary, X = self._count_vocab(raw_documents,
self.fixed_vocabulary_) # 重点关注
if self.binary:
X.data.fill(1)
if not self.fixed_vocabulary_:
X = self._sort_features(X, vocabulary)
n_doc = X.shape[0]
max_doc_count = (max_df
if isinstance(max_df, numbers.Integral)
else max_df * n_doc)
min_doc_count = (min_df
if isinstance(min_df, numbers.Integral)
else min_df * n_doc)
if max_doc_count < min_doc_count:
raise ValueError(
"max_df corresponds to < documents than min_df")
X, self.stop_words_ = self._limit_features(X, vocabulary,
max_doc_count,
min_doc_count,
max_features)
self.vocabulary_ = vocabulary
return X
如果参数输入包括vocabulary,则生成的是字典对象,否则就会生成defaultdict对象。而如果是字典对象,对于feature_idx = vocabulary[feature],如果输入是不存在的key,则就会引发异常。
def _count_vocab(self, raw_documents, fixed_vocab):
if fixed_vocab:
vocabulary = self.vocabulary_
else:
# Add a new value when a new vocabulary item is seen
vocabulary = defaultdict()
vocabulary.default_factory = vocabulary.__len__
analyze = self.build_analyzer()
j_indices = []
indptr = []
values = _make_int_array()
indptr.append(0)
for doc in raw_documents:
feature_counter = {}
for feature in analyze(doc):
try:
feature_idx = vocabulary[feature]
if feature_idx not in feature_counter:
feature_counter[feature_idx] = 1
else:
feature_counter[feature_idx] += 1
except KeyError:
# Ignore out-of-vocabulary items for fixed_vocab=True
continue
j_indices.extend(feature_counter.keys())
values.extend(feature_counter.values())
indptr.append(len(j_indices))
if not fixed_vocab:
# disable defaultdict behaviour
vocabulary = dict(vocabulary)
if not vocabulary:
raise ValueError("empty vocabulary; perhaps the documents only"
" contain stop words")
if indptr[-1] > 2147483648: # = 2**31 - 1
if sp_version >= (0, 14):
indices_dtype = np.int64
else:
raise ValueError(('sparse CSR array has {} non-zero '
'elements and requires 64 bit indexing, '
' which is unsupported with scipy {}. '
'Please upgrade to scipy >=0.14')
.format(indptr[-1], '.'.join(sp_version)))
else:
indices_dtype = np.int32
j_indices = np.asarray(j_indices, dtype=indices_dtype)
indptr = np.asarray(indptr, dtype=indices_dtype)
values = np.frombuffer(values, dtype=np.intc)
X = sp.csr_matrix((values, j_indices, indptr),
shape=(len(indptr) - 1, len(vocabulary)),
dtype=self.dtype)
X.sort_indices()
return vocabulary, X
- 在不指定vocabulary的情况下,指定tokenizer,即指定分词的函数,此时stop_words等还是有效的,因为我们指定这个参数,仅仅是确定如何分词,不影响最终生成的词典还需要去停用词,去不满足max_features等的词,但是token_pattern无效。
def build_tokenizer(self):
"""Return a function that splits a string into a sequence of tokens"""
if self.tokenizer is not None:
return self.tokenizer
token_pattern = re.compile(self.token_pattern)
return lambda doc: token_pattern.findall(doc)

- 在不指定vocabulary和tokenizer的情况下,指定token_pattern,该参数和tokenizer相似,指定了要保留哪些词,需要用正则表达式。

build_analyzer: build_preprocessor-> return lambda doc: self._word_ngrams(tokenize(preprocess(self.decode(doc))), stop_words)