操作系统:Ubuntu-18.04
Hadoop版本:hadoop-2.7.2
Spark版本:spark-2.4.3
Python版本:Python 3.6.9
一、安装Spark
1.解压,在/opt目录下准备好spark-2.4.3-bin-hadoop2.7文件(下载的spark版本需要对应hadoop版本)
cd /opt
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz # 解压
mv spark-2.4.3-bin-hadoop2.7 spark-2.4.3 # 把解压后的目录名字改简单一点
2.配置环境变量,vim /etc/profile.d/spark.sh,内容如下:
export SPARK_HOME=/opt/spark-2.4.3 # 这里是自己解压spark包的位置
export PATH=$PATH:/opt/spark-2.4.3/bin:/opt/spark-2.4.3/sbin
输入:wq保存退出,然后在终端输入source /etc/profile,使环境变量生效。
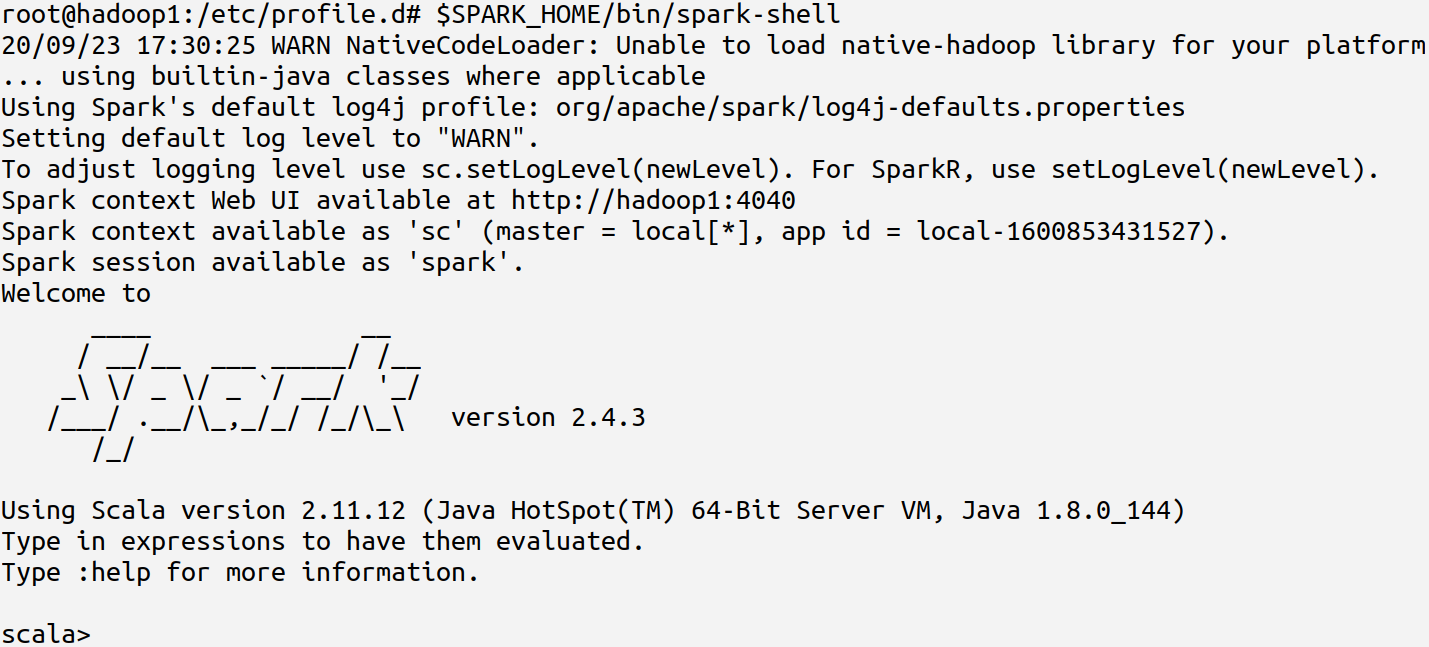
$SPARK_HOME/bin/spark-shell,可以进入spark的shell界面,如下图:
3.修改spark配置文件
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
cp log4j.properties.template log4j.properties
vim spark-env.sh,添加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_144 # java路径
export HADOOP_HOME=/opt/hadoop-2.7.2 # hadoop路径
SPARK_MASTER_IP=hadoop1 # master节点IP(如果/etc/hosts添加了主机和IP对应关系,可以直接写主机名)
vim slaves,修改内容如下(更改原文件中的"localhost"):
hadoop2 # 这里写自己需要的spark从节点的主机名
hadoop3
vim log4j.properties,修改内容如下:
log4j.rootCategory=WARN, console # 将原来的INFO改成WARN,否则每次运行输出太多信息
二、安装pyspark
编写spark的原生语言是Scala,但是我们可以用python来操作spark,这就需要安装pyspark。(PySpark 是 Spark 为 Python 开发者提供的 API)
apt install python3-pip
# 这里用的国内豆瓣的镜像网址,网速飞快
pip3 install pyspark -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
# 这里还得安装一个findspark,否则python程序找不到spark的位置(真坑啊!)
pip3 install findspark -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
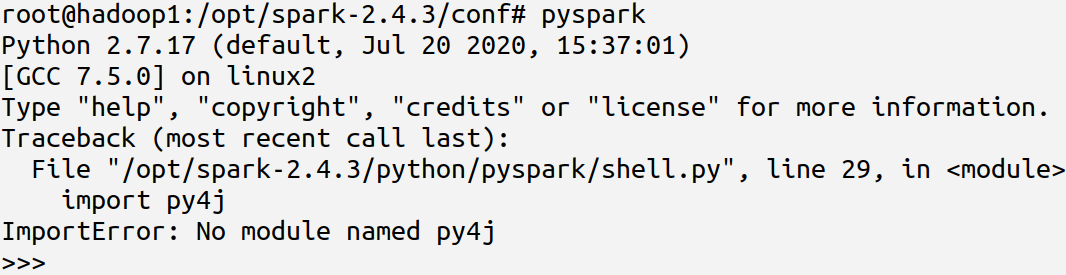
安装完成后,输入pyspark即可进入其shell界面,如下图:
三、编写python测试程序(wordCount.py)
编写一个计算单词数的python程序测试一下。
mkdir -p /opt/workspace/spark-work
cd /opt/workspace/spark-work
vim wordCount_input.txt,内容如下:
hadoop spark
hive hbase
hadoop
spark spark
python
vim wordCount.py,代码:
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
# 创建SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf = conf)
inputFile = "file:///opt/workspace/spark-work/wordCount_input.txt" # 输入文件的路径
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
wordCount.foreach(print)
四、运行wordCount.py程序(本地运行)
本地运行wordCount.py,有两种方法:
(1)直接用python3运行
python3 wordCount.py,运行结果如下图:

(2)通过spark-submit提交程序
vim $SPARK_HOME/conf/spark-env.sh,添加内容:
export PYSPARK_DRIVER_PYTHON=/usr/bin/python3
export PYSPARK_PYTHON=/usr/bin/python3
$SPARK_HOME/bin/spark-submit wordCount.py,运行结果如下图:
