这一张承接上一章的IMDB数据集
修改训练相关参数,对比实验,看一看在二分类问题上不用参数,优化器,激活函数,对于模型的变化。
加深理解,和参悟。
代码只截取片段:
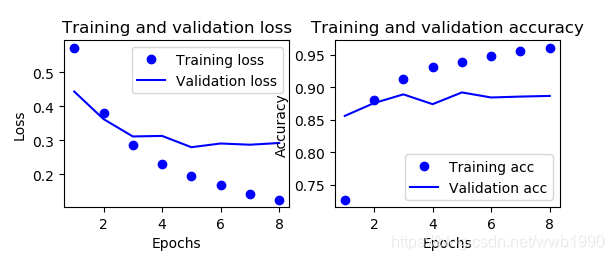
(2)上一篇的结果
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=512,
validation_data=(x_val,y_val))
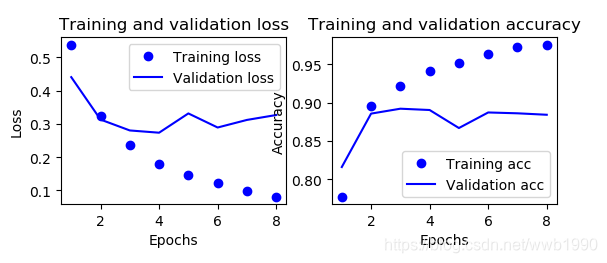
(2)减小batch_size,过拟合的最低点提前到来
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
h
istory = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=128,
validation_data=(x_val,y_val))
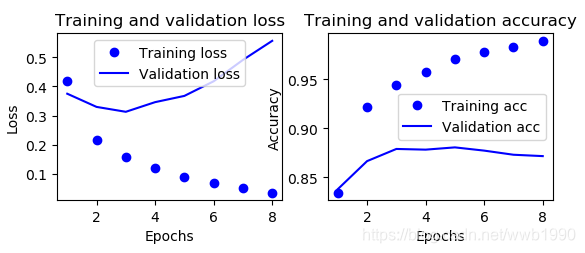
(3)猜测增大batch_size会让最低loss延后,增大到1024后如下图。
确实是延后了
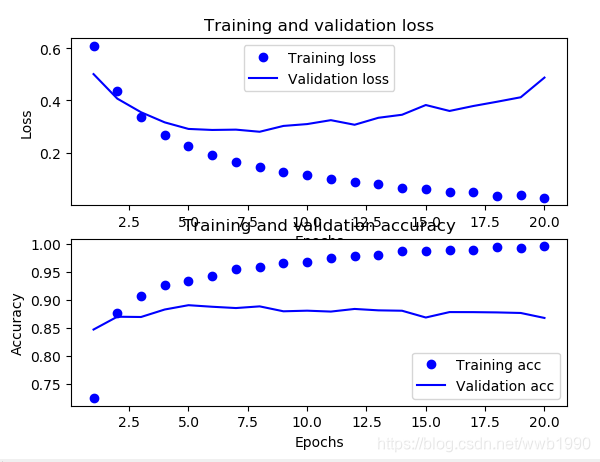
(4)在(3)的基础上,增加周期的次数,看看之后是不是还是一样平稳。
可以看出,趋势还是一样的,不过周期变长了,也就是说batch_size决定了变化的周期长度。
(5)回到原始基础上,再改一改网络层数。先减少一层。
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
# model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
history = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=512,
validation_data=(x_val,y_val))
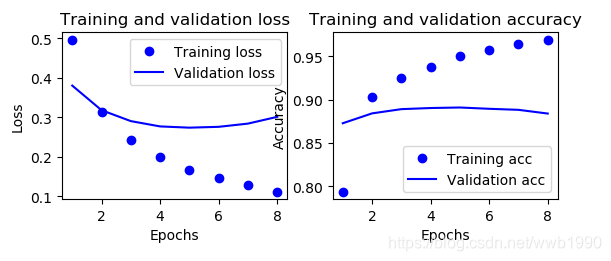
大概在第5轮是最低的loss,和最高准确率。我来输出一下训练五轮的测试集结果:

对比一下训练四轮(loss最低,acc最高点),初始网络的测试集结果:
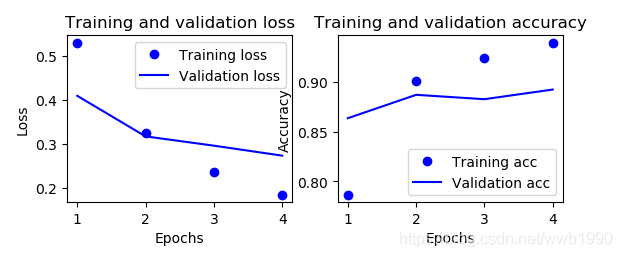

可以看出一层隐藏层,是差于两层的。
(6)那就有思路了,我们来增加网络层数,还是基于最原始状态:
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
history = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=512,
validation_data=(x_val,y_val))
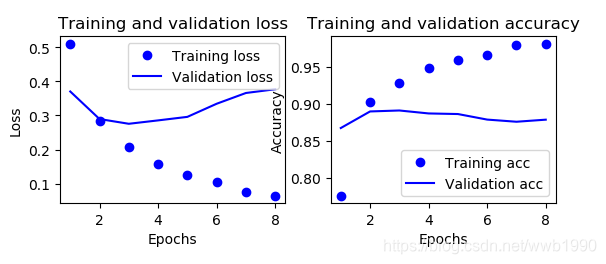
可见3隐藏层的比2层隐藏层提早了1个周期到达loss最小,acc最大点。
我们来输出一下,训练三轮(最小loss,最大acc点),测试集准确率:
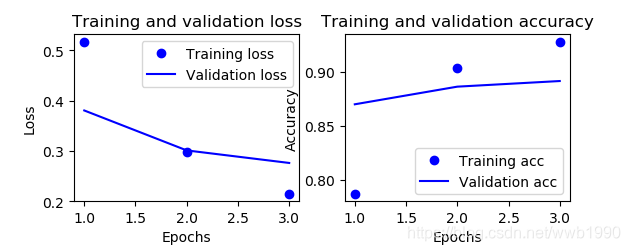

可以看出比2隐藏层还差了一点点。所以也不是层数多就更好。
看起来就很玄学。。。
(7)接下来回到原始状态,换一下激活函数试试。tanh代替relu
model.add(layers.Dense(16,activation='tanh',input_shape=(10000,)))
model.add(layers.Dense(16,activation='tanh'))
model.add(layers.Dense(1,activation='sigmoid'))
history = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=512,
validation_data=(x_val,y_val))
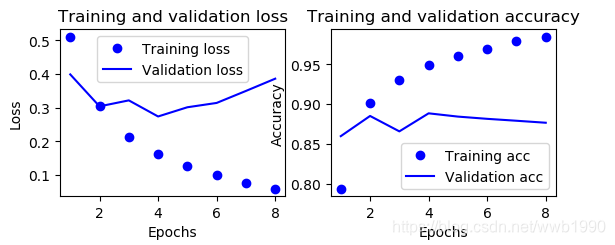
原始结果:
看到,和原始一样,最优点也出现在了第四轮,就是折线的形状不大相似。
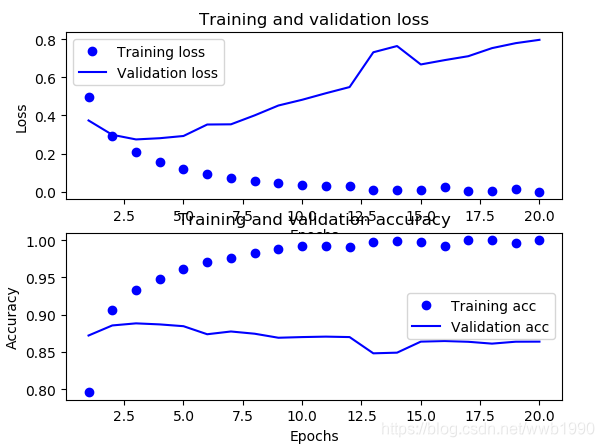
我训练20轮,来对比也下这两种激活函数的形状。
tanh激活:
relu激活:
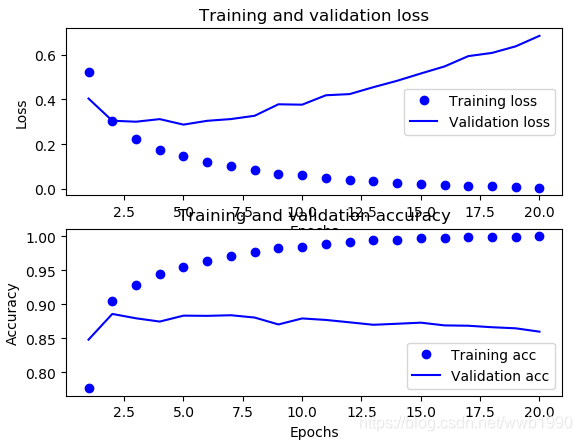
总体分部并没有看出什么区别。
但是对于找acc最高值,前几轮看起来relu更平稳一些。
(8)继续回到初始状态,调整损失函数,用mse代替binary_crossentropy
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='mse',
metrics=['accuracy'])
history = model.fit(partial_x_train,
partial_y_trail,
epochs=8,
batch_size=512,
validation_data=(x_val,y_val))
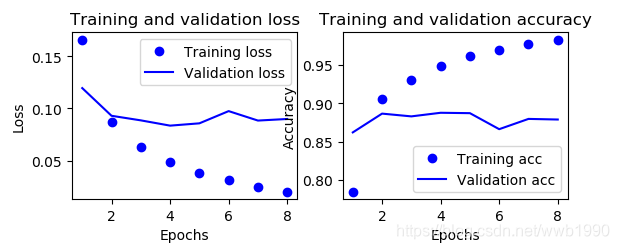
原始结果:
看起来换损失函数能改变波动的幅度,依然是第四个点是最佳,不过loss的值所在范围(<0.15)小于之前的实验loss范围(0.5~0.2),对于结果位置出现影响不大。
我在四轮,测试集测试一下精确度

初始网络:
可以看到虽然loss看着是小很多,但是准确度是一样的,甚至这次训练结果还差了一点点。
总结一哈
隐藏层数,多或少说不准,这个很玄。
隐藏单元个数,会影响过拟合的来临时间。
激活函数,暂时看出是影响变化浮动。
损失函数的作用是确定损失值的范围,对于模型是否更优的作用还没看出来。