1.声明:
本文参考https://blog.csdn.net/weixin_40170902/article/details/80092628
2.拉伸运动:
在我看来,所有大神的思想无非是:早餐应该吃包子还是油条,这家2块但是不好吃,那家好吃但是5块钱有点贵,我应该怎么选的问题。朋友们如果觉得我说的不对,请保留你心中的宝贵意见,就当是为人类观点的多样性做贡献。如果你觉得这个人不是那么的让人讨厌,那我们开始吧!
3.总体概述:
以下的optimizer算法总体上是基于梯度下降算法进行优化,分为梯度和学习率两方面的优化。梯度优化包括:Momentum、 Nesterov;学习率优化包括:Adagrad、Adadelta、RMSprop、Adam。是不是很多,是不是很头疼。我不能把发明算法的人都毙掉,那我就试着说的简单一点。
4.开始:
刮风这天我试过握着你手,但偏偏雨渐渐大到我看你不见,还要多久我才能在你身边,等到放晴的那天也许我会比较好一点《晴天-周杰伦 》;试着以最轻松的状态唱完上面的歌,不行就多唱几遍,对对对,不要把自己催的那么紧!生命的旋律一定要优美,时间的脚步就需要和谐。
1.梯度优化类算法:
1.Momentum(前事不忘后事之师):
原始的梯度下降公式为:
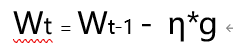
小人下山的时候,只考虑前面要怎么走。上帝还是很有智慧的,设计了惯性。那我们也给这个小人加上惯性吧。于是 就有了下面公式:这里Vt-1相当于是前面所有梯度的加权累计,t 时刻对应的权重为:α**t-1;

但是加上惯性之后的小人,处于局部处的时候就徘徊震荡。取得一点点的小成就就不思进取,我们肯定忘了点什么,对要让他有远见,展望明天!
2.Nesterov(人无远虑必有近忧)
小人从以前的经验中学到了知识,这会告诉他怎么走;但是对于人类上帝还有一句忠告:三思而后行;那么就让这个小人想一想这么走的后果,再继续走;于是我们的公式变成了:
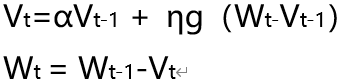
暂时我们解决了怎么走的问题,那是不是应该考虑一下走多少的问题了。先唱首歌,不负金樽、才能不负青春
没关系你也不用给我机会 反正我还有一生可以浪费 我就是剩这么一点点倔 称得上 我的优点
没关系你也不用对我惭愧 也许我根本喜欢被你浪费 随便你今天拼命爱上谁 我都会 坦然面对
即使要我跟你再耗个十年 无所谓《浪费-林宥嘉》
3.Adagrad()
传统调整学习率的方式:1/(1+衰减率*迭代次数) 作为衰减度,但是这样调整是有点武断。
所以我们的学习率就变成了下面这样,解释一下就是用学习率除以对应参数以前的梯度平方和,ε是为了方式分母为0;想象一个班级的小朋友去春游,要回家就要一起走到山下去,大家走了10分钟后,发现刘翔同学已经快到下面了,那就让他慢点走,发现杨超越同学还在山顶数星星,那就让她快点走。根据前面走的路判断接下来步子要跨多大。

但是这样还有个问题,就是越往后,学习率越小,后面就往往不调了。
4.RMSprop
名称已经暴露了算法本身,就是平均平方和再开根号,说到底就是把adagrad中的二阶导的平方和换成了平方的平均数。

5.Adadelta
这个算法不依赖于手动指定的学习率,简单理解为 一阶导/二阶导;这个算法是这些算法中唯一不需要指定学习率的,所以他很得儿。

6.Adam
这个算法相当于给一阶导和二阶导加上了矫正项;β1通常取0.9,β2通常取0.999;走的更稳健了

我累了,等我歇够了再来完善吧!基本思想体系已经完成。
我看透了她的心还有别人逗留的背影
她的回忆清除得不够乾净
我看到了她的心演的全是他和她的电影
他不爱我尽管如此她还是赢走了我的心《她不爱我-莫文蔚》