文章目录
1. 初始Spark
1.1 什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是 UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室) 所开源的类似 Hadoop MapReduce 的通用计算框架。Spark 拥有Hadoop MapReduce 所具有的优点;单不同于MapReduce 的是 Job的中间结果可以保存在内存中,而不需要读写DHFS。因此Spark能更好的适用于数据挖掘和机器学习等需要迭代的MapReduce的算法。
1.2 Spark与MapReduce的区别
- 都是分布式计算框架
- Spark基于内存,MR基于HDFS
- Spark处理数据能力一般是MR的十倍以上
- Spark基于DAG有向无环图来切分任务的执行先后顺序
1.3 Spark 运行模式
-
Local
多用于本地测试,如在eclipse、idea中编写程序测试等。
-
Standalone
Standalone 是Spark自带的一个资源调度框架,它支持完全分布式。
-
Yarn
Hadoop生态圈里的资源调度框架,Spark也可以基于Yarn来计算。
-
Mesos
资源调度框架
扫描二维码关注公众号,回复: 11908543 查看本文章
要基于Yarn 来进行资源调度,必须实现ApplicationMaster接口。Spark实现了这个接口,就可以基于Yarn。
2. SparkCore
2.1 RDD
2.1.1 概念
RDD(Resilient Distributed Dateset) ,弹性分布式数据集。
2.1.2 RDD的五大特性
- RDD是由一系列的partition组成的。
- 函数是作用在每个partition上的。
- RDD之间有一系列的依赖关系。
- 分区器是作用在K,V 格式的RDD上。
- RDD 提供一系列最佳的计算位置。
2.1.3 RDD 图解

从上往下看:
-
textFile 方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。
-
RDD 实际上不存储数据,这里为了方便理解,暂时理解为存储数据。
-
什么是K,V格式的RDD?
如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
-
哪里体现RDD的弹性/容错?
patition数量、RDD大小没有限制体系了RDD的弹性。
RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
-
哪里体现RDD的分布式?
RDD由partition组成,partition是分布在不同的节点上的。
-
RDD提供计算最佳位置,体现了数据本地化。体系了大数据中"计算移动数据不移动"的理念。
2.2 Spark 任务执行原理
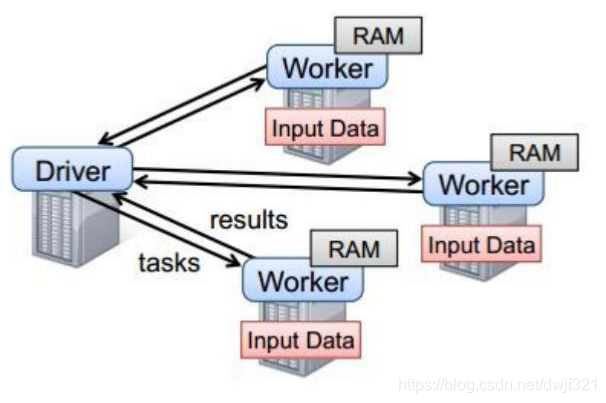
以上图中的四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中。
- Driver与集群节点之间频繁通信。
- Driver负责任务(task)的分发和回收结果,任务的调度。如果task的计算结果非常大就不用回收了,会造成OOM。
- Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
- Master是Standalone资源调度框架里面的资源管理的主节点。也是JVM进程。
2.3 Spark代码流程
-
创建SparkConf对象
可以设置 appName
可以设置运行模式以及资源需求
-
创建SparkContext对象。
-
基于Spark的上下文创建RDD,对RDD进行处理。
-
应用程序中要有Action类算子来触发Transformation类算子执行。
-
关闭Spark上下文对象SparkContext。
2.4 Transformations 转换算子
2.4.1 概念
Transformations 类算子是一类算子(函数),叫做转换算子。如:map、flatMap、reduceByKey等。Transformations 算子延迟执行,也叫懒加载执行。
2.4.2 Transformation 类算子
| Transformations算子 | 作用 |
|---|---|
| map(func) | 返回一个新的分布式数据集,其中每个元素都是由源RDD中的一个元素经过func函数转换得到的 |
| filter(func) | 返回一个新的数据集,其中包含的元素来自源RDD中元素经过func函数过滤后的结果(func函数返回true的结果) |
| flatMap(func) | 类似于map,但每个元素可以映射到0到n个输出元素(func函数必须返回的是一个序列(Seq) 而不是单个元素) |
| mapPartitions(func) | 类似于map,但是它是基于RDD的每个partition(或者数据block)独立运行,所以如果RDD包含元素类型为T,则func函数必须是Iterator => Iterator的映射函数 |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,只是func多了一个整型的分区索引,因此RDD包含元素类型为T,则func函数必须是Iterator => Iterator的映射函数 |
| mapWith(func1,func2) | mapWith是map的另一个变种,map只需要一个输入函数,而mapWith有两个输入函数。第一个函数把RDD的partion index (index从0开始)作为输入,输出为新类型A;第二个函数f把二元组(T,A)作为输入(其中T为原RDD中的元素,A为第一个函数的输出),输出类型为U |
| reduceByKey(func,[numTasks]) | 如果源RDD包含元素类型为(K,V)对,则该算子也返回包含(K,V)对的RDD,只不过每个key对应的Value是经过func函数聚合后的结果,而func函数本身是一个(V,V) => V 的映射函数。另外,和groupByKey类型。可以通过可选参数numTasks指定reduce任务个数 |
| aggregateByKey(zeroValue,seqOp,combOp,[numTasks]) | 如果源RDD包含(K,V)对,则返回的新RDD包含(K,V)对,其中每个Key对应的Value都是由combOp函数和一个 “0” 值zeroValue聚合得到。运行聚合后Value类型和输入Value类型不同,避免了不必要的开销。和groupByKey类似。可以通过可选参数numTasks指定reducer任务的个数 |
| sortByKey([ascending],[numTasks]) | 如果源RDD包含元素(K,V)对,其中K可以排序,则返回新的RDD包含(K,V)对,并按照K进行排序(由ascending参数决定是升序还是降序) |
| sortBy(func,[ascending],[numTasks]) | 类似于sortByKey,只不过sortByKey只能够按照Key去排序,sortBy更加灵活,既可以按照key,也可以按照value排序 |
| randomSplit(Array[Double],Long) | 该函数根据weights权重,将一个RDD切分成多个RDD。该权重参数为一个Double数组,第二个参数为random的种子,基本可以忽略 |
| glom() | 该函数是将RDD中每一个分区中类型为T的元素转换成Array[T],这样每一个分区就只有一个数组元素。 |
| zip(otherDataSet) | 用于将两个RDD组合成K,V形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。 |
| partitionBy(Partitioner) | 该函数根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区。 |
| join(otherDataset,[numTasks]) | 相当于mysql的INNER JOIN,当join左右两边的数据集都存在时才返回。join后的分区数与父RDD分区数多的那一个相同 |
| leftOuterJoin(otherDataset) | 相当于mysql的LEFT JOIN,leftOuterJoin返回数据集左边的全部数据和数据集左边与右边有交集的数据,不存在的数据以None填充 |
| rightOuterJoin(otherDataset) | 相当于mysql的RIGHT JOIN,rightOuterJoin返回数据集右边的全部数据和数据集右边与左边有交集的数据,不存在的数据以None填充 |
| fullOuterJoin(otherDataset) | 返回左右数据集的全部数据,左右有一边不存在的数据以None填充 |
| union | 合并两个数据集。两个数据集的类型要一致。返回新的RDD的分区数是合并RDD分区数的总和。 |
| intersection | 取两个数据集的交集,返回新的RDD与父RDD分区多的一致 |
| subtract | 取两个数据集的差集,结果RDD的分区数与subtract前面的RDD的分区数一致 |
| distinct | 去重,相当于(map+reduceByKey+map) |
| cogroup | 当调用类型(K,V)和(K,W)的数据时,返回一个数据集(K,(Iterable,Iterable)),子RDD的分区与父RDD多的一致。 |
2.5 Action 行动算子
2.5.1 概念
Action 类算子也是一类算子(函数),叫做行动算子,如foreach。collect,count等。Transformations 类算子是延迟执行,Action类算子是触发执行。一个APP 应用程序中有几个Action 类算子执行,就有几个job运行。
2.5.2 Action算子
| Action 算子 | 作用 |
|---|---|
| reduce(func) | 将RDD中元素按func函数进行聚合,func函数是一个(T,T) ==> T 的映射函数,其中T为源RDD的元素类型,并且func需要满足交换律和结合律以便支持并行计算 |
| collect() | 将数据集集中,所有元素以数组形式返回驱动器(driver)程序。通常用于在RDD进行了filter或其他过滤后,将足够小的数据子集返回到驱动器内存中,否则会OOM。 |
| count() | 返回数据集中元素个数 |
| first() | 返回数据中首个元素(类似于take(1)) |
| take(n) | 返回数据集中前n个元素 |
| takeSample(withReplacement,num,[seed]) | 返回数据集的随机采样子集,最多包含num个元素,withReplacement表示是否使用回置采样,最后一个参数为可选参数seed,随机数生成器的种子。 |
| takeOrderd(n,[ordering]) | 按元素排序(可以通过ordering自定义排序规则)后,返回前n个元素 |
| foreach(func) | 循环遍历数据集中的每个元素,运行相应的逻辑 |
| foreachParition(func) | foreachParition和foreach类似,只不过是对每个分区使用函数,性能比foreach要高,推荐使用。 |
2.6 控制算子
2.6.1 概念
控制算子有三种:cache、persist、checkpoint。以上算子都是可以将RDD持久化,持久化单位是partition。cache和persist都是懒执行的,必须有一个action 类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
2.6.2 控制算子介绍
-
cache
默认将RDD的数据持久化到内存中。cache是懒执行。
cache() = persist(StorageLevel.MEMORY_ONLY()); -
persist
可以指定持久化的级别。最常用的是
StorageLevel.MEMORY_ONLY()和StorageLevel.MEMORY_AND_DISK()。"_2"表示有副本。持久化级别如下:
def useDisk : scala.Boolean = { /* compiled code */ } def useMemory : scala.Boolean = { /* compiled code */ } def useOffHeap : scala.Boolean = { /* compiled code */ } def deserialized : scala.Boolean = { /* compiled code */ } def replication : scala.Int = { /* compiled code */ }持久化级别 作用 NONE不做持久化 DISK_ONLY只持久化到磁盘 DISK_ONLY_2只持久化到磁盘,并且有2个副本 MEMORY_ONLY只持久化到内存 MEMORY_ONLY_2只持久化到内存,并且有2个副本 MEMORY_ONLY_SER只持久化到内存,并且序列化 MEMORY_ONLY_SER_2只持久化到内存,存储2个副本,并且序列化 MEMORY_AND_DISK持久化到内存和磁盘,内存不够时存储到磁盘 MEMORY_AND_DISK_2持久化到内存和磁盘,内存不够时存储到磁盘,并且有2个副本 MEMORY_AND_DISK_SER持久化到内存和磁盘,内存不够时存储到磁盘,并且序列化 MEMORY_AND_DISK_SER_2持久化到内存和磁盘,内存不够时存储到磁盘,并且有2个副本,并且序列化 OFF_HEAP持久化到堆外内存 cache 和persist 的注意事项:
- cache 和 persist 都是懒执行,必须有一个action类算子触发执行。
- cache 和 persist 算子的返回值可赋值给一个变量,在其他job 中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache 和 persist 算子后不能立即紧跟 action 算子。
- cache 和 persist 算子持久化的数据当 APP 执行完成之后会被清除。
错误: rdd.cache().count() 返回的部署持久化的RDD,而是一个数值。
-
checkpoint
checkpoint 将 RDD 持久化到磁盘,还可以切断 RDD 之间的依赖关系。checkpoint 目录数据当 APP 执行完之后不会被清除。
checkpoint 的执行原理:
- 当 RDD 的job 执行完毕后,会从 finalRDD 从后往前回溯。
- 当回溯到某一个RDD 调用了checkpoint 方法,会对当前的RDD 做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据。将数据持久化到HDFS上。
优化:对RDD 执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以了,省去了重新计算着一步。
使用:
SparkSession spark = SparkSession.builder() .appName("JavaLogQuery").master("local").getOrCreate(); JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); JavaRDD<String> dataSet = sc.parallelize(exampleApacheLogs); dataSet = dataSet.cache(); sc.setCheckpointDir("/checkpoint/dir"); dataSet.checkpoint(); -
unpersist
将持久化到内存和磁盘的数据删除。