select、poll、eopll是操作系统处理网络上传输过来的数据的不同实现,数据从经过网线流入网卡,网卡中的驱动程序会向CPU发出中断信号,在交互系统中,中断信号的优先级是很高的,CPU立刻去处理这个中断信息,CPU通过终端表找到相应的处理函数:
1、禁用网卡的中断信号,告诉网卡下次有数据过来直接写内存就ok
2、通过驱动程序申请、初始化一块内存,将网卡中的数据写进内存中
3、然后解析处理数据:操作系统先校验数据是否符合os structure、数据往上层传递,Ehthernet校验数据是否符合预期的格式,继续向上层传递到ip层,再往上到tcp/udp层并按照指定的协议去解析
4、应用层想使用这部分数据就有一个拆包+格式校验的过程
内存指的socket文件的接受缓冲区。
作为一个网络服务器同一时刻可能有多个socket和他建立连接与他进行数据的交互,这里的select、poll、epoll说的其实就是在众多的socket中如何快速高效的找到接受缓冲区存在数据的socket文件,然后交给应用层的代码去处理它
Select模型

操作系统为每一个Tcp连接都会相应的创建sock文件,这些sock文件隶属于操作系统的文件列表。
当sock收到了数据,会调用中断程序唤醒进程A,将进程A从所有的Sock的等来队列中移除,加入到内核空间的工作队列中进程A只知道至少有一个sock的接受缓冲区已经由数据了,但是它不知道到底是哪个sock,所以它得通过遍历sock列表的方式找到这个sock。
select的缺点和不足:
- 进程A需要添加进所有的sock的等待队列中,这会进行一次遍历。
- 当有sock就收到数据时,又得将进程A从所有的sock等待队列中移除,这又是一次遍历。
- 进程A寻找有数据的sock时,还会发生一次遍历。
- 为了放置单个进程将系统的所有资源都耗干,linux会限制单个进程能打开的fd文件句柄数,即使你可以修改配置,突破这会个限制
下图截自《UNIX环境高级编程》第二版

上图可以看到,使用select系统调用上有三个核心参数:分别是 readfds、writefds、exceptfds指向文件描述符号指针,每个描述符都被放在fd_set中, 也就是说针对read、write、和except分别对应着一个独立的fd_set , (并没有网上流传的数组哦,至少《UNIX环境高级编程》是这样讲的)
下图是截取自《UNIX环境高级编程》的关于fd_set的相关信息,fd_set 是一个bit mask,不是数组。

Poll模型
网上一直流传着这样一句话:poll本质上和select没有区别,都会进行好几次无谓的遍历才能找到到底是那个sock文件的接受缓冲区中接受到了数据。
下图是我截自《UNIX环境高级编程》关于poll部分的内容
书中关于poll的描述,poll模型中定义了一个pollfd,对fd进行了封装,也就是说,poll是使用数组来保存fd的,就是上图中的pollfd数组
网上流传的另一个版本就是说:poll使用链表维护着fd,所以poll没有最大连接数的限制,这一点有待证实,至少《UNIX环境高级编程》中对链表的事只字未提
从书中的描述看,poll确实是用数组来维护fd的,并且还自己封装了个pollfd,维护的是pollfd数组,那为什么poll没有连接数的限制呢?
我是这样理解的:select之所以受到能仅仅能打开1024的限制,是因为操作系统层面上默认就有对单个进程能打开fd的作出的限制,比如32位的OS默认就是1024。那我用poll同也会受到这个1024的限制,但是我能修改这个限制,让他变得比1024大。比如改成10万(只要你的服务器性能够好就行,数组中就能存更多的fd,遍历处理起来就更快)。所以这才会说,poll理论上可以没有限制。
当然我上面说的不一定就对,如果你有更好的解析,欢迎留言。
Epoll模型

Epoll的设计目标就是优化掉Select 和 Poll模型中查找接收到数据的sock文件时进行的无谓的遍历操作。
看上图:在select模型中,需要将进程添加进每一个sock的等待队列,然后阻塞,假如10万TCP连接对应着10万个sock文件,那这个添加+阻塞的操作就得重复10万次
对于epoll来说可以看到,这个添加的过程只进行了一次...见下图
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1){
int n = epoll_wait(...)
for(接收到数据的socket){
//处理
}
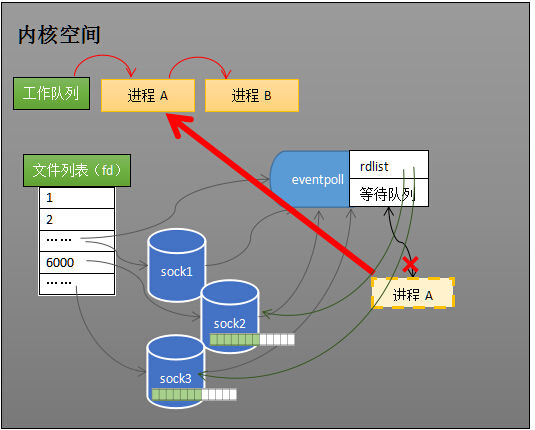
当执行系统调用 epoll_create(...) 内核会创建上图中的eventpoll对象,eventpoll对象也隶属于操作系统的文件系统,此外所有的sock都注册在eventpoll中。
进程不再注册在每一个sock的等待队列中,而是注册在eventpoll的等待队列中,此外,接受缓冲区存在数据的sock会被注册进eventpoll的rdlist中。这样当进程再次被唤醒添加到操作系统的工作队列中时,从eventpoll的rdlist中就能确切的获取到哪些sock是需要处理的sock,免去了遍历之苦。
eventpoll中的数据结构
rdlist: 里面存放就绪列的socket,为了满足快速方便删除、添加。它被设计成了双向链表
epoll中也是需要保存受监视的sock,为了方便添加、搜索、检索。被设计成红黑树。因为它的搜索、插入、删除的时间复杂度都是O(logN)
Epoll的连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。