本节为大家介绍Dubbo的集群容错的整体架构,让大家对整个集群容错层有一个整体的理解,并且让大家知道,集群容错层是如何工作的,每个组件的作用以及结构。
导读
在分布式环境中,为了避免单点故障,通常一个业务会部署在多台机器上。服务消费方调用时,如果服务提供方由于某些原因不可用,在Dubbo的集群容错的作用下,会自动根据某些容错策略选择可用的服务给消费方,以达到整个服务集群的高可用。
集群容错
在讲解源码前,我们先看一下集群容错的整体架构图和每个组件的作用。
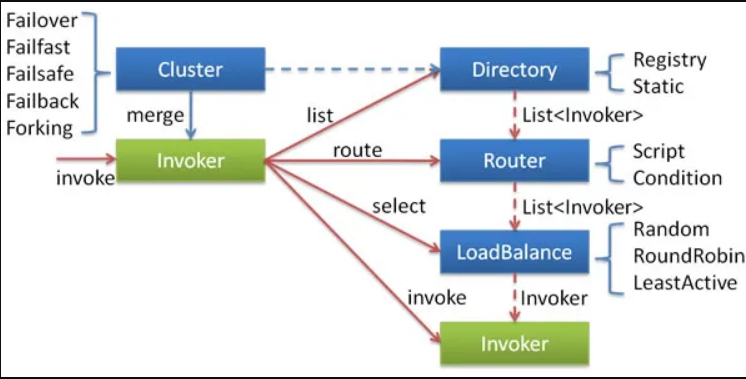
我们可以把Cluster看作是一个集群容错层,该层包含的组件有Cluster、Directory、Router、LoadBalance。
Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。服务消费方在发生远程调用时,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。Directory 的用途是保存 Invoker,可简单类比为 List<Invoker>,并调用 Router 的 route 方法进行路由,过滤掉不符合路由规则的 Invoker。然后它会通过 LoadBalance 从 Invoker 列表中选择一个 Invoker。最后会调用选择出的 Invoker 实例的 invoke 方法,进行真正的远程调用。
Dubbo的主要提供了如下几种容错方式:
-
Failover Cluster - 失败自动切换
-
Failfast Cluster - 快速失败
-
Failsafe Cluster - 失败安全
-
Failback Cluster - 失败自动恢复
-
Forking Cluster - 并行调用多个服务提供者
源码分析
Dubbo的集群容错层代码的入口是Cluster接口,代码如下:
org.apache.dubbo.rpc.cluster.Cluster
@SPI(FailoverCluster.NAME)
public interface Cluster {
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}Cluster是一个接口,返回一个Invoker,我们可以把它当成一个可用的服务实例,即当上层调用Invoker时,无论实际存在多少个Invoker,只要通过Cluster层,即可完成容错的逻辑,包括服务的路由、负载均衡等,对上层都是透明的。
public interface Invoker<T> extends Node {
Class<T> getInterface();
//执行调用
Result invoke(Invocation invocation) throws RpcException;
}我们看一下Invoker接口的抽象类AbstractClusterInvoker的invoke方法的实现
org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke
@Override
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// 绑定 attachments 到 invocation 中.
Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addObjectAttachments(contextAttachments);
}
// 列举 Invoker
List<Invoker<T>> invokers = list(invocation);
// 通过DubboSPI机制加载 LoadBalance
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
// 抽象方法,调用 doInvoke 进行后续操作。不同的实现在子类中
return doInvoke(invocation, invokers, loadbalance);
}AbstractClusterInvoker#invoke方法逻辑比较简单,主要完成以下几件事
1、绑定attachments到invocation中。
2、通过list方法获取所有的Invoker。从Directory中获取List<Invoker>
3、负载均衡(通过Dubbo SPI机制加载)。
4、doInvoke,是一个abstract方法,完成最后的容错逻辑。
Dubbo的SPI机制贯穿与整个Dubbo框架,如果大家对Dubbo SPI机制不熟悉的话,推荐阅读笔者的这篇文章
我们以FailoverCluster,失败自动切换为例:
public class FailoverCluster extends AbstractCluster {
public final static String NAME = "failover";
@Override
public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {
// 创建并返回 FailoverClusterInvoker 对象
return new FailoverClusterInvoker<>(directory);
}
}它的作用是创建并返回FailoverClusterInvoker的实例,调用FailoverClusterInvoker的invoke方法,即可完成服务的调用。接下来,我们分析FailoverClusterInvoker.doInvoke方法
org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker#doInvoke
@Override
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
// 获取重试次数
int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
// retry loop.
RpcException le = null; // last exception.
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
// 循环调用,达到重试的效果
for (int i = 0; i < len; i++) {
// 如果第一次调用失败,重试时重新获取最新的List<Invoker>
if (i > 0) {
checkWhetherDestroyed();
copyInvokers = list(invocation);
// check again
checkInvokers(copyInvokers, invocation);
}
// 通过负载均衡选择 Invoker
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
// 设置 invoked 到 RPC 上下文中
RpcContext.getContext().setInvokers((List) invoked);
try {
// 调用目标Invoker的invoke方法
Result result = invoker.invoke(invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("...");
}
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException("...");
}FailoverClusterInvoker 的 doInvoke 方法首先是获取重试次数,然后根据重试次数进行循环调用,失败后进行重试。在 for 循环内,首先是通过负载均衡组件选择一个 Invoker,然后再通过这个 Invoker 的 invoke 方法进行远程调用。如果失败了,记录下异常,并进行重试。重试时会再次调用父类的 list 方法列举 Invoker。下面我们看一下 select 方法的逻辑。
org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#select
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
String methodName = invocation == null ? StringUtils.EMPTY_STRING : invocation.getMethodName();
// 获取 sticky 配置,sticky 表示粘滞连接。所谓粘滞连接是指让服务消费者尽可能的调用同一个服务提供者
boolean sticky = invokers.get(0).getUrl()
.getMethodParameter(methodName, CLUSTER_STICKY_KEY, DEFAULT_CLUSTER_STICKY);
// 检测 invokers 列表是否包含 stickyInvoker,如果不包含,
// 说明 stickyInvoker 代表的服务提供者挂了,此时需要将其置空
if (stickyInvoker != null && !invokers.contains(stickyInvoker)) {
stickyInvoker = null;
}
//如果 selected 包含 stickyInvoker,表明 stickyInvoker 对应的服务提供者可能因网络原因未能成功提供服务。
// 但是该提供者并没挂,此时 invokers 列表中仍存在该服务提供者对应的 Invoker
if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) {
if (availablecheck && stickyInvoker.isAvailable()) {
return stickyInvoker;
}
}
// 执行到这一步,重新选择Invoker
Invoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);
if (sticky) {
stickyInvoker = invoker;
}
return invoker;
}select 方法的主要逻辑集中在了对粘滞连接特性的支持上。
1、首先是获取 sticky 配置,然后再检测 invokers 列表中是否包含 stickyInvoker,如果不包含,则认为该 stickyInvoker 不可用,此时将其置空。
2、如果这个列表不包含 stickyInvoker,那自然而然的认为 stickyInvoker 挂了,所以置空。
3、如果 stickyInvoker 存在于 invokers 列表中,此时要进行下一项检测 — 检测 selected 中是否包含 stickyInvoker。如果包含的话,说明 stickyInvoker 在此之前没有成功提供服务(但其仍然处于存活状态)。此时我们认为这个服务不可靠,不应该在重试期间内再次被调用,因此这个时候不会返回该 stickyInvoker。
4、如果 selected 不包含 stickyInvoker,此时还需要进行可用性检测,比如检测服务提供者网络连通性等。当可用性检测通过,才可返回 stickyInvoker,否则调用 doSelect 方法选择 Invoker。如果 sticky 为 true,此时会将 doSelect 方法选出的 Invoker 赋值给 stickyInvoker。
接下来,我们分析doSelect方法的实现
org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#doSelect
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation,
List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
if (invokers.size() == 1) {
return invokers.get(0);
}
// 通过负载均衡组件选择 Invoker
Invoker<T> invoker = loadbalance.select(invokers, getUrl(), invocation);
// 如果 selected 包含负载均衡选择出的 Invoker,或者该 Invoker 无法经过可用性检查,此时进行重选
if ((selected != null && selected.contains(invoker))
|| (!invoker.isAvailable() && getUrl() != null && availablecheck)) {
try {
// 重新选择Invoker
Invoker<T> rInvoker = reselect(loadbalance, invocation, invokers, selected, availablecheck);
if (rInvoker != null) {
// 选择成功
invoker = rInvoker;
} else {
// 选择不成功,从List<Invoker>中定位,并获取下一个位置的Invoker
int index = invokers.indexOf(invoker);
try {
invoker = invokers.get((index + 1) % invokers.size());
} catch (Exception e) {
logger.warn("...");
}
}
} catch (Throwable t) {
logger.error("...");
}
}
return invoker;
}doSelect总体干了三件事:
1、通过负载均衡组建选择Invoker
2、如果选择的Invoker在当前selected里,或者该Invoker不可用,重新选择
3、如果重新选择还是不成功,定位当前Invoker的位置,获取selected中下一个Invoker实例
到这里为止,我们用FailoverClusterInvoker为例,讲了Dubbo集群容错的整体架构和调用流程,总结一下:
1、Cluster是一个接口,服务消费方通过Cluser容错层,实现容错逻辑,Cluster接口的join方法返回一个Invoker实例。
2、Invoker我们可以理解为一个服务提供方实例,调用Invoker.invoke方法,即可达到调用。
3、Invoker的抽象实现类AbstractClusterInvoker,实现了集群容错的通用逻辑,不同的容错逻辑在抽象方法doInvoke里实现。
4、doInvoke方法,是各种集群容错策略的实现。
5、通过Direcorty.list方法获取List<Invoker>,然后通过获取LoadBalance.select方法,选择出不同负载均衡策略下的Invoker。
6、如果负载均衡选择失败,会执行reselect的逻辑。
好了,这就是今天分享的内容,谢谢大家。
推介阅读
Apache Dubbo系列:Netty与Dubbo是如何对接的
加作者好友,获取更多福利
