文章目录
声明:
本博客是本人在学习《Java 编程的逻辑》后整理的笔记,旨在方便复习和回顾,并非用作商业用途。
本博客已标明出处,如有侵权请告知,马上删除。
开头语
程序主要就是数据以及对数据的操作,为方便理解和操作,高级语言使用数据类型这个概念,不同的数据类型有不同的特征和操作。
Java 定义了八种基本数据类型,四种整型 byte/short/int/long,两种浮点类型 float/double,一种真假类型 boolean,一种字符类型 char,其他类型的数据都用类这个概念表达。
3.1 类的基本概念
在第1章,我们暂时将类看做函数的容器,在某些情况下,类也确实基本上只是函数的容器,但类更多表示的是自定义数据类型。我们先从容器的角度,然后从自定义数据类型的角度谈谈类。
3.1.1 函数容器
我们看个例子,Java API 中的类 Math,它里面主要就包含了若干数学函数,表 3-1 列出了其中一些。

使用这些函数,直接在前面加 Math. 即可,例如 Math.abs(-1) 返回 1。
这些函数都有相同的修饰符,public static。
static 表示类方法,也叫静态方法,与类方法相对的是实例方法。实例方法没有 static 修饰符,必须通过实例或者叫对象(待会介绍)调用,而类方法可以直接通过类名进行调用的,不需要创建实例。
public 表示这些函数是公开的,可以在任何地方被外部调用。与 public 相对的有 private, 如果是 private,表示私有,这个函数只能在同一个类内被别的函数调用,而不能被外部的类调用。在 Math 类中,有一个函数 Random initRNG() 就是 private 的,这个函数被 public 的方法 random() 调用以生成随机数,但不能在 Math 类以外的地方被调用。
将函数声明为 private 可以避免该函数被外部类误用,调用者可以清楚的知道哪些函数是可以调用的,哪些是不可以调用的。类实现者通过 private 函数封装和隐藏内部实现细节,而调用者只需要关心 public 的就可以了。可以说,通过 private 封装和隐藏内部实现细节,避免被误操作,是计算机程序的一种基本思维方式。
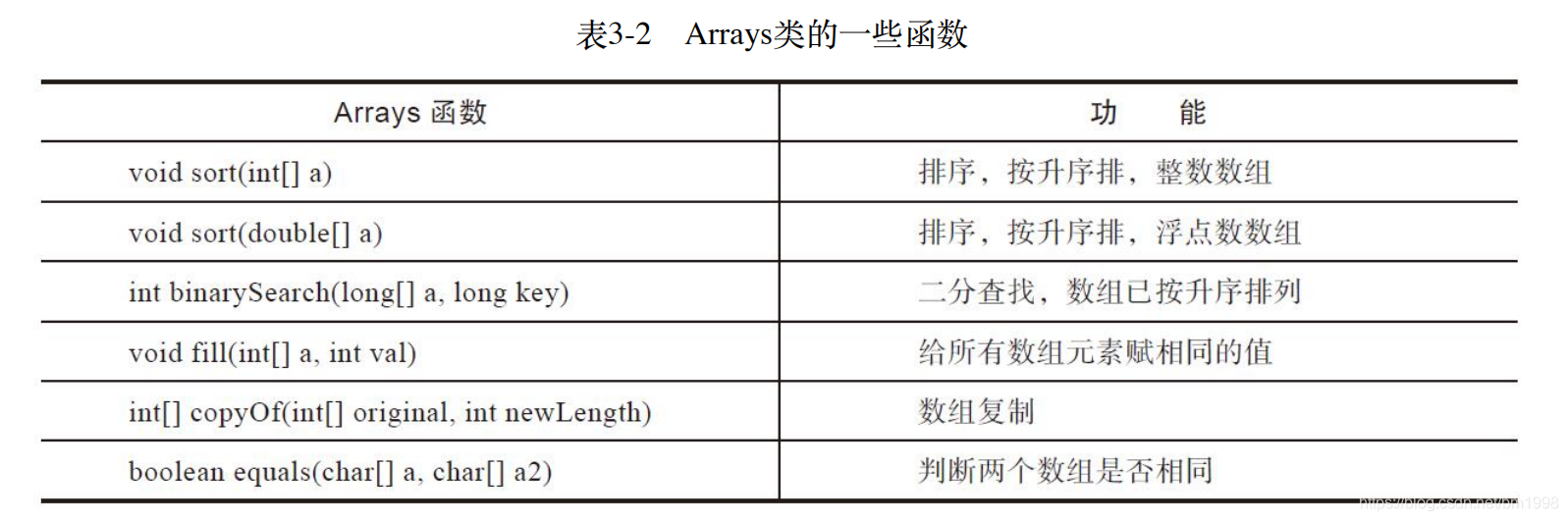
除了 Math 类,我们再来看一个例子 Arrays,Arrays 里面包含很多与数组操作相关的函数,表 3-2 列出了其中一些。
这里将类看做函数的容器,更多的是从语言实现的角度看,从概念的角度看,Math 和 Arrays 也可以看做是自定义数据类型,分别表示数学和数组类型,其中的 public static 函数可以看做是类型能进行的操作。接下来让我们更为详细的讨论自定义数据类型。
3.1.2 自定义数据类型
我们将类看做自定义数据类型,所谓自定义数据类型就是除了八种基本类型以外的其他类型,用于表示和处理基本类型以外的其他数据。
一个数据类型由其包含的属性以及该类型可以进行的操作组成,属性又可以分为是类型本身具有的属性,还是一个具体数据具有的属性,同样,操作也可以分为是类型本身可以进行的操作,还是一个具体数据可以进行的操作。
这样,一个数据类型就主要由四部分组成:
- 类型本身具有的属性,通过类变量体现
- 类型本身可以进行的操作,通过类方法体现
- 类型实例具有的属性,通过实例变量体现
- 类型实例可以进行的操作,通过实例方法体现
不过,对于一个具体类型,每一个部分不一定都有,Arrays 类就只有类方法。
类变量和实例变量都叫成员变量,也就是类的成员,类变量也叫静态变量或静态成员变量。类方法和实例方法都叫成员方法,也都是类的成员,类方法也叫静态方法。
类方法我们上面已经看过了,Math 和 Arrays 类中定义的方法就是类方法,这些方法的修饰符必须有 static。下面解释下类变量,实例变量和实例方法。
3.1.2.1 类变量
类型本身具有的属性通过类变量体现,经常用于表示一个类型中的常量。比如 Math 类,定义了两个数学中常用的常量,如下所示:
public static final double E = 2.7182818284590452354;
public static final double PI = 3.14159265358979323846;
E 表示数学中自然对数的底数,自然对数在很多学科中有重要的意义,PI 表示数学中的圆周率 π。与类方法一样,类变量可以直接通过类名访问,如 Math.PI。
这两个变量的修饰符也都有 public static,public 表示外部可以访问,static 表示是类变量。与 public 相对的主要也是 private,表示变量只能在类内被访问。与 static 相对的是实例变量,没有 static 修饰符。
这里多了一个修饰符 final,final 在修饰变量的时候表示常量,即变量赋值后就不能再修改了。使用 final 可以避免误操作,比如说,如果有人不小心将 Math.PI 的值改了,那么很多相关的计算就会出错。另外,Java 编译器可以对 final 变量进行一些特别的优化。所以,如果数据赋值后就不应该再变了,就加 final 修饰符吧。
表示类变量的时候,static 修饰符是必需的,但 public 和 final 都不是必需的。
3.1.2.2 实例变量和实例方法
所谓实例,字面意思就是一个实际的例子。实例变量表示具体的实例所具有的属性,实例方法表示具体的实例可以进行的操作。如果将微信订阅号看做一个类型,那"老马说编程"订阅号就是一个实例,订阅号的头像、功能介绍、发布的文章可以看做实例变量,而修改头像、修改功能介绍、发布新文章可以看做实例方法。与基本类型对比,“int a;” 这个语句,int 就是类型,而 a 就是实例。
接下来,我们通过定义和使用类,来进一步理解自定义数据类型。
3.1.3 定义第一个类
我们定义一个简单的类,表示在平面坐标轴中的一个点,代码如下:
class Point {
public int x;
public int y;
public double distance(){
return Math.sqrt(x*x+y*y);
}
}
我们来解释一下:
public class Point
表示类型的名字是 Point,是可以被外部公开访问的。这个 public 修饰似乎是多余的,不能被外部访问还能有什么用?在这里,确实不能用 private 修饰 Point。但修饰符可以没有(即留空),表示一种包级别的可见性,我们后续章节介绍,另外,类可以定义在一个类的内部,这时可以使用 private 修饰符,我们也在后续章节介绍。
public int x;
public int y;
定义了两个实例变量,x 和 y,分别表示 x 坐标和 y 坐标,与类变量类似,修饰符也有 public 或 private 修饰符,表示含义类似,public 表示可被外部访问,而 private 表示私有,不能直接被外部访问,实例变量不能有 static 修饰符。
public double distance(){
return Math.sqrt(x*x+y*y);
}
定义了实例方法 distance,表示该点到坐标原点的距离。该方法可以直接访问实例变量 x 和 y,这是实例方法和类方法的最大区别。实例方法直接访问实例变量,到底是什么意思呢?其实,在实例方法中,有一个隐含的参数,这个参数就是当前操作的实例自己,直接操作实例变量,实际也需要通过参数进行。
实例方法和类方法更多的区别如下所示:
- 类方法只能访问类变量,但不能访问实例变量,可以调用其他的类方法,但不能调用实例方法。
- 实例方法既能访问实例变量,也可以访问类变量,既可以调用实例方法,也可以调用类方法。
关于实例方法和类方法更多的细节,后续会进一步介绍。
3.1.4 使用第一个类
定义了类本身和定义了一个函数类似,本身不会做什么事情,不会分配内存,也不会执行代码。方法要执行需要被调用,而实例方法被调用,首先需要一个实例。实例也称为对象,我们可能会交替使用。
下面的代码演示了如何使用:
public static void main(String[] args) {
Point p = new Point();
p.x = 2;
p.y = 3;
System.out.println(p.distance());
}
我们解释一下:
Point p = new Point();
这个语句包含了 Point 类型的变量声明和赋值,它可以分为两部分:
Point p;
p = new Point();
Point p 声明了一个变量,这个变量叫 p,是 Point 类型的。这个变量和数组变量是类似的,都有两块内存,一块存放实际内容,一块存放实际内容的位置。声明变量本身只会分配存放位置的内存空间,这块空间还没有指向任何实际内容。因为这种变量和数组变量本身不存储数据,而只是存储实际内容的位置,它们也都称为引用类型的变量。
p = new Point(); 创建了一个实例或对象,然后赋值给了 Point 类型的变量 p,它至少做了两件事:
- 分配内存,以存储新对象的数据,对象数据包括这个对象的属性,具体包括其实例变量 x 和 y。
- 给实例变量设置默认值,int 类型默认值为 0。
与方法内定义的局部变量不同,在创建对象的时候,所有的实例变量都会分配一个默认值,这与在创建数组的时候是类似的,数值类型变量的默认值是 0,boolean 是 false, char 是 ‘\u0000’,引用类型变量都是 null,null 是一个特殊的值,表示不指向任何对象。这些默认值可以修改,我们待会介绍。
p.x = 2;
p.y = 3;
给对象的变量赋值,语法形式是:<对象变量名>.<成员名>。
System.out.println(p.distance());
调用实例方法 distance,并输出结果,语法形式是:<对象变量名>.<方法名>。实例方法内对实例变量的操作,实际操作的就是 p 这个对象的数据。
我们在介绍基本类型的时候,是先定义数据,然后赋值,最后是操作,自定义类型与此类似:
- Point p = new Point(); 是定义数据并设置默认值
- p.x = 2; p.y = 3; 是赋值
- p.distance() 是数据的操作
可以看出,对实例变量和实例方法的访问都通过对象进行,通过对象来访问和操作其内部的数据是一种基本的面向对象思维。本例中,我们通过对象直接操作了其内部数据 x 和 y,这是一个不好的习惯,一般而言,不应该将实例变量声明为 public,而只应该通过对象的方法对实例变量进行操作。原因也是为了减少误操作,直接访问变量没有办法进行参数检查和控制,而通过方法修改,可以在方法中进行检查。
3.1.5 变量默认值
之前我们说,实例变量都有一个默认值,如果希望修改这个默认值,可以在定义变量的同时就赋值,或者将代码放入初始化代码块中,代码块用 {} 包围,如下面代码所示:
int x = 1;
int y;
{
y = 2;
}
x 的默认值设为了 1,y 的默认值设为了 2。在新建一个对象的时候,会先调用这个初始化,然后才会执行构造方法中的代码。关于构造方法,我们稍后介绍。
静态变量也可以这样初始化:
static int STATIC_ONE = 1;
static int STATIC_TWO;
static
{
STATIC_TWO = 2;
}
STATIC_TWO=2; 语句外面包了一个 static {},这叫静态初始化代码块。静态初始化代码块在类加载的时候执行,这是在任何对象创建之前,且只执行一次。
3.1.6 private 变量
上面我们说一般不应该将实例变量声明为 public,下面我们修改一下类的定义,将实例变量定义为 private,通过实例方法来操作变量,代码如下:
class Point {
private int x;
private int y;
public void setX(int x) {
this.x = x;
}
public void setY(int y) {
this.y = y;
}
public int getX() {
return x;
}
public int getY() {
return y;
}
public double distance() {
return Math.sqrt(x * x + y * y);
}
}
这个定义中,我们加了四个方法,setX/setY 用于设置实例变量的值,getX/getY 用于获取实例变量的值。
这里面需要介绍的是 this 这个关键字。this 表示当前实例,在语句 this.x=x; 中,this.x 表示实例变量 x,而右边的 x 表示方法参数中的 x。前面我们提到,在实例方法中,有一个隐含的参数,这个参数就是 this,没有歧义的情况下,可以直接访问实例变量,在这个例子中,两个变量名都叫 x,则需要通过加上 this 来消除歧义。
这四个方法看上去是非常多余的,直接访问变量不是更简洁吗?而且上节我们也说过,函数调用是有成本的。在这个例子中,意义确实不太大,实际上,Java 编译器一般也会将对这几个方法的调用转换为直接访问实例变量,而避免函数调用的开销。但在很多情况下,通过函数调用可以封装内部数据,避免误操作,我们一般还是不将成员变量定义为 public。
使用这个类的代码如下:
public static void main(String[] args) {
Point p = new Point();
p.setX(2);
p.setY(3);
System.out.println(p.distance());
}
将对实例变量的直接访问改为了方法调用。
3.1.7 构造方法
在初始化对象的时候,前面我们都是直接对每个变量赋值,有一个更简单的方式对实例变量赋初值,就是构造方法,我们先看下代码,在 Point 类定义中增加如下代码:
public Point(){
this(0,0);
}
public Point(int x, int y){
this.x = x;
this.y = y;
}
这两个就是构造方法,构造方法可以有多个。不同于一般方法,构造方法有一些特殊的地方:
- 名称是固定的,与类名相同。这也容易理解,靠这个用户和 Java 系统就都能容易的知道哪些是构造方法。
- 没有返回值,也不能有返回值。这个规定大概是因为返回值没用吧。
与普通方法一样,构造方法也可以重载。第二个构造方法是比较容易理解的,使用 this 对实例变量赋值。
我们解释下第一个构造方法,this(0,0) 的意思是调用第二个构造方法,并传递参数 0,0。我们前面解释说 this 表示当前实例,可以通过 this 访问实例变量,这是 this 的第二个用法,用于在构造方法中调用其他构造方法。
这个 this 调用必须放在第一行,这个规定应该也是为了避免误操作。构造方法是用于初始化对象的,如果要调用别的构造方法,先调别的,然后根据情况自己再做调整,而如果自己先初始化了一部分,再调别的,自己的修改可能就被覆盖了。
这个例子中,不带参数的构造方法通过 this(0,0) 又调用了第二个构造方法,这个调用是多余的,因为 x 和 y 的默认值就是 0,不需要再单独赋值,我们这里主要是演示其语法。
我们来看下如何使用构造方法,代码如下:
Point p = new Point(2,3);
这个调用就可以将实例变量 x 和 y 的值设为 2 和 3。前面我们介绍 new Point() 的时候说,它至少做了两件事,一个是分配内存,另一个是给实例变量设置默认值,这里我们需要加上一件事,就是调用构造方法。调用构造方法是 new 操作的一部分。
通过构造方法,可以更为简洁的对实例变量进行赋值。关于构造方法,下面我们讨论两个细节概念:一个是默认构造方法;另一个是私有构造方法。
3.1.7.1 默认构造方法
每个类都至少要有一个构造方法,在通过 new 创建对象的过程中会被调用。但构造方法如果没什么操作要做,可以省略。Java 编译器会自动生成一个默认构造方法,也没有具体操作。但一旦定义了构造方法,Java 就不会再自动生成默认的。具体什么意思呢?在这个例子中,如果我们只定义了第二个构造方法(带参数的),则下面语句:
Point p = new Point();
就会报错,因为找不到不带参数的构造方法。
为什么 Java 有时候帮助自动生成,有时候不生成呢?你在没有定义任何构造方法的时候,Java 认为你不需要,所以就生成一个空的以被 new 过程调用,你定义了构造方法的时候,Java 认为你知道自己在干什么,认为你是有意不想要不带参数的构造方法的,所以不会帮你生成。
3.1.7.2 私有构造方法
构造方法可以是私有方法,即修饰符可以为 private, 为什么需要私有构造方法呢?大概可能有这么几种场景:
- 不能创建类的实例,类只能被静态访问,如 Math 和 Arrays 类,它们的构造方法就是私有的。
- 能创建类的实例,但只能被类的的静态方法调用。有一种常用的场景,即类的对象有但是只能有一个,即单例模式(后续文章介绍),在这个场景中,对象是通过静态方法获取的,而静态方法调用私有构造方法创建一个对象,如果对象已经创建过了,就重用这个对象。
- 只是用来被其他多个构造方法调用,用于减少重复代码。
3.1.8 类和对象的生命周期
了解了类和对象的定义和使用,下面我们再从程序运行的角度理解下类和对象的生命周期。
3.1.8.1 类
在程序运行的时候,当第一次通过 new 创建一个类的对象的时候,或者直接通过类名访问类变量和类方法的时候,Java 会将类加载进内存,为这个类分配一块空间,这个空间会包括类的定义,它有哪些变量,哪些方法等,同时还有类的静态变量,并对静态变量赋初始值。后续文章会进一步介绍有关细节。
类加载进内存后,一般不会释放,直到程序结束。一般情况下,类只会加载一次,所以静态变量在内存中只有一份。
3.1.8.2 对象
当通过 new 创建一个对象的时候,对象产生,在内存中,会存储这个对象的实例变量值,每 new 一次,对象就会产生一个,就会有一份独立的实例变量。
每个对象除了保存实例变量的值外,可以理解还保存着对应类型即类的地址,这样,通过对象能知道它的类,访问到类的变量和方法代码。
实例方法可以理解为一个静态方法,只是多了一个参数 this,通过对象调用方法,可以理解为就是调用这个静态方法,并将对象作为参数传给 this。
对象的释放是被 Java 用垃圾回收机制管理的,大部分情况下,我们不用太操心,当对象不再被使用的时候会被自动释放。
具体来说,对象和数组一样,有两块内存,保存地址的部分分配在栈中,而保存实际内容的部分分配在堆中。栈中的内存是自动管理的,函数调用入栈就会分配,而出栈就会释放。
堆中的内存是被垃圾回收机制管理的,当没有活跃变量指向对象的时候,对应的堆空间就可能被释放,具体释放时间是 Java 虚拟机自己决定的。活跃变量,具体的说,就是已加载的类的类变量,和栈中所有的变量。
3.1.9 小结
本节我们主要从自定义数据类型的角度介绍了类,谈了如何定义类,以及如何创建对象,如何使用类。自定义类型由类变量、类方法、实例变量和实例方法组成,为方 便对实例变量赋值,介绍了构造方法。本节引入了多个关键字,我们介绍了这些关键字的含义。最后我们介绍了类和对象的生命周期。
通过类实现自定义数据类型,封装该类型的数据所具有的属性和操作,隐藏实现细节,从而在更高的层次上(类和对象的层次,而非基本数据类型和函数的层次)考虑和操作数据,是计算机程序解决复杂问题的一种重要的思维方式。
本节我们提到了多个关键字,这里汇总一下:
- public:可以修饰类、类方法、类变量、实例变量、实例方法、构造方法,表示可被外部访问。
- private:可以修饰类、类方法、类变量、实例变量、实例方法、构造方法,表示不可以被外部访问,只能在类内被使用。
- static:修饰类变量和类方法,它也可以修饰内部类(后续章节介绍)。
- this:表示当前实例,可以用于调用其他构造方法,访问实例变量,访问实例方法。
- final:修饰类变量、实例变量,表示只能被赋值一次,final 也可以修饰实例方法和局部变量(后续章节介绍)。
本节介绍的 Point 类,其属性只有基本数据类型,下节我们介绍类的组合,以表达更为复杂的概念。
3.2 类的组合
程序是用来解决现实问题的,将现实中的概念映射为程序中的概念,是初学编程过程中的一步跨越。本节通过一些例子来演示,如何将一些现实概念和问题,通过类以及类的组合来表示和处理。
我们先介绍两个基础类 String 和 Date,他们都是 Java API 中的类,分别表示文本字符串和日期。
3.2.1 基础类
3.2.1.1 String
String 是 Java API 中的一个类,表示多个字符,即一段文本或字符串,它内部是一个 char 的数组,它提供了若干方法用于方便操作字符串。
String 可以用一个字符串常量初始化,字符串常量用双引号括起来(注意与字符常量区别,字符常量是用单引号),例如,如下语句声明了一个 String 变量 name,并赋值为"老马说编程"。
String name = "老马说编程";
String 类提供了很多方法,用于操作字符串。在 Java 中,由于 String 用的非常普遍,Java 对它有一些特殊的处理,本节暂不介绍这些内容,只是把它当做一个表示字符串的类型来看待。
3.2.1.2 Date
Date 也是 Java API 中的一个类,表示日期和时间,它内部是一个 long 类型的值,它也提供了若干方法用于操作日期和时间。
用无参的构造方法新建一个 Date 对象,这个对象就表示当前时间。
Date now = new Date();
日期和时间处理是一个比较长的话题,我们留待后续章节详解,本节我们只是把它当做表示日期和时间的类型来看待。
3.2.2 图形类
3.2.2.1 拓展 Point
我们先扩展一下 Point 类,在其中增加一个方法,计算到另一个点的距离,代码如下:
public double distance(Point p){
return Math.sqrt(Math.pow(x-p.getX(), 2)
+Math.pow(y-p.getY(), 2));
}
3.2.2.1 线 Line
在类型 Point 中,属性 x,y 都是基本类型,但类的属性也可以是类,我们考虑一个表示线的类,它由两个点组成,有一个实例方法计算线的长度,代码如下:
public class Line {
private Point start;
private Point end;
public Line(Point start, Point end){
this.start= start;
this.end = end;
}
public double length(){
return start.distance(end);
}
}
Line 由两个 Point 组成,在创建 Line 时这两个 Point 是必须的,所以只有一个构造方法,且需传递这两个点,length 方法计算线的长度,它调用了 Point 计算距离的方法获取线的长度。可以看出,在设计线时,我们考虑的层次是点,而不考虑点的内部细节。每个类封装其内部细节,对外提供高层次的功能,使其他类在更高层次上考虑和解决问题,是程序设计的一种基本思维方式。
使用这个类的代码如下所示:
public static void main(String[] args) {
Point start = new Point(2,3);
Point end = new Point(3,4);
Line line = new Line(start, end);
System.out.println(line.length());
}
这个也很简单。我们再说明一下内存布局,line 的两个实例成员都是引用类型,引用实际的 point,整体内存布局大概如图 3-1 所示。
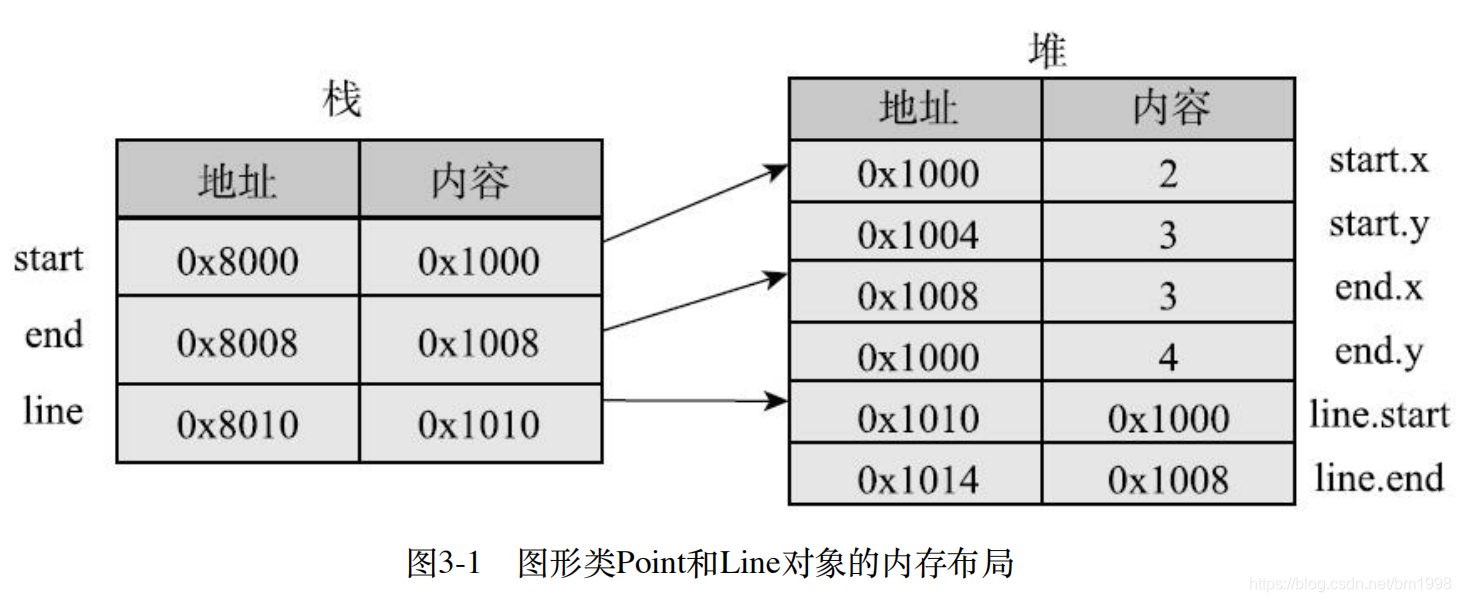
start, end, line 三个引用型变量分配在栈中,保存的是实际内容的地址,实际内容保存在堆中,line 的两个实例变量还是引用,同样保存的是实际内容的地址。
3.2.3 用类描述电商概念
接下来,我们用类来描述一下电商系统中的一些基本概念,电商系统中最基本的有产品、用户和订单:
- 产品:有产品唯一 Id、名称、描述、图片、价格等属性。
- 用户:有用户名、密码等属性。
- 订单:有订单号、下单用户、选购产品列表及数量、下单时间、收货人、收货地址、联系电话、订单状态等属性。
当然,实际情况可能非常复杂,这是一个非常简化的描述。
这是产品类 Product 的代码:
public class Product {
//唯一id
private String id;
//产品名称
private String name;
//产品图片链接
private String pictureUrl;
//产品描述
private String description;
//产品价格
private double price;
}
我们省略了类的构造方法,以及属性的 getter/setter 方法,下面大部分示例代码也都会省略。
这是用户类 User 的代码:
public class User {
private String name;
private String password;
}
一个订单可能会有多个产品,每个产品可能有不同的数量,我们用订单条目 OrderItem 这个类来描述单个产品及选购的数量,代码如下所示:
public class OrderItem {
//购买产品
private Product product;
//购买数量
private int quantity;
public OrderItem(Product product, int quantity) {
this.product = product;
this.quantity = quantity;
}
public double computePrice(){
return product.getPrice()*quantity;
}
}
OrderItem 引用了产品类 Product,我们定义了一个构造方法,以及计算该订单条目价格的方法。
下面是订单类 Order 的代码:
public class Order {
//订单号
private String id;
//购买用户
private User user;
//购买产品列表及数量
private OrderItem[] items;
//下单时间
private Date createtime;
//收货人
private String receiver;
//收货地址
private String address;
//联系电话
private String phone;
//订单状态
private String status;
public double computeTotalPrice(){
double totalPrice = 0;
if(items!=null){
for(OrderItem item : items){
totalPrice+=item.computePrice();
}
}
return totalPrice;
}
}
Order 类引用了用户类 User,以及一个订单条目的数组 orderItems,它定义了一个计算总价的方法。这里用一个 String 类表示状态 status,更合适的应该是枚举类型,枚举我们后续文章再介绍。
以上类定义是非常简化的了,但是大概演示了将现实概念映射为类以及类组合的过程,这个过程大概就是,想想现实问题有哪些概念,这些概念有哪些属性,哪些行为,概念之间有什么关系,然后定义类、定义属性、定义方法、定义类之间的关系,大概如此。概念的属性和行为可能是非常多的,但定义的类只需要包括那些与现实问题相关的就行了。
3.2.4 用类描述人之间的血缘关系
上面介绍的图形类和电商类只会引用别的类,但一个类定义中还可以引用它自己。比如我们要描述人以及人之间的血缘关系,我们用类 Person 表示一个人,它的实例成员包括其父亲、母亲、和孩子,这些成员也都是 Person 类型。
下面是代码:
public class Person {
//姓名
private String name;
//父亲
private Person father;
//母亲
private Person mother;
//孩子数组
private Person[] children;
public Person(String name) {
this.name = name;
}
}
这里同样省略了 setter/getter 方法。对初学者,初看起来,这是比较难以理解的,有点类似于函数调用中的递归调用,这里面的关键点是,实例变量不需要一开始都有值。我们来看下如何使用。
public static void main(String[] args){
Person laoma = new Person("老马");
Person xiaoma = new Person("小马");
xiaoma.setFather(laoma);
laoma.setChildren(new Person[]{
xiaoma});
System.out.println(xiaoma.getFather().getName());
}
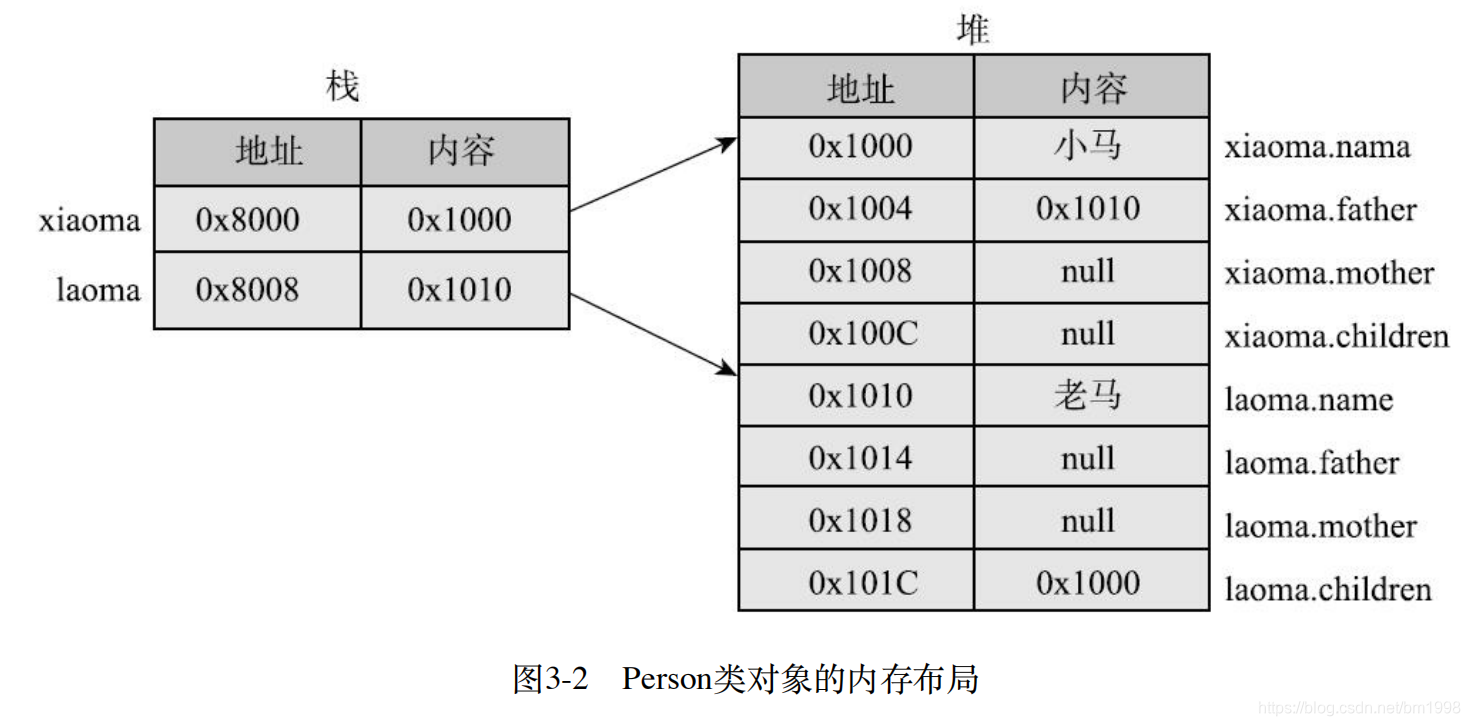
这段代码先创建了老马(laoma),然后创建了小马(xiaoma),接着调用 xiaoma 的 setFather 方法和 laoma 的 setChildren 方法设置了父子关系。内存中的布局大概如图 3-2 所示。
3.2.5 目录和文件
接下来,我们介绍两个类 MyFile 和 MyFolder,分别表示文件管理中的两个概念,文件和文件夹。文件和文件夹都有名称、创建时间、父文件夹,根文件夹没有父文件夹,文件夹还有子文件列表和子文件夹列表。
下面是文件类 MyFile 的代码:
public class MyFile {
//文件名称
private String name;
//创建时间
private Date createtime;
//文件大小
private int size;
//上级目录
private MyFolder parent;
//其他方法 ....
public int getSize() {
return size;
}
}
下面是 MyFolder 的代码:
public class MyFolder {
//文件夹名称
private String name;
//创建时间
private Date createtime;
//上级文件夹
private MyFolder parent;
//包含的文件
private MyFile[] files;
//包含的子文件夹
private MyFolder[] subFolders;
public int totalSize(){
int totalSize = 0;
if(files!=null){
for(MyFile file : files){
totalSize+=file.getSize();
}
}
if(subFolders!=null){
for(MyFolder folder : subFolders){
totalSize+=folder.totalSize();
}
}
return totalSize;
}
//其他方法...
}
MyFile 和 MyFolder,我们都省略了构造方法、settter/getter 方法,以及关于父子关系维护的代码,主要演示实例变量间的组合关系。两个类之间可以互相引用,MyFile 引用了 MyFolder,而 MyFolder 也引用了 MyFile,这个是没有问题的。因为正如之前所说,这些属性不需要一开始就设置,也不是必须设置的。另外,演示了一个递归方法 totalSize(),返回当前文件夹下所有文件的大小,这是使用递归函数的一个很好的场景。
3.2.6 一些说明
类中定义哪些变量,哪些方法是与要解决的问题密切相关的,本节中并没有特别强调问题是什么,定义的属性和方法主要用于演示基本概念,实际应用中应该根据具体问题进行调整。
类中实例变量的类型可以是当前定义的类型,两个类之间可以互相引用,这些初听起来可能难以理解,但现实世界就是这样的,创建对象的时候这些值不需要一开始都有,也可以没有,所以是没有问题的。
类之间的组合关系,在 Java 中实现的都是引用,但在逻辑关系上,有两种明显不同的关系,一种是包含,另一种就是单纯引用。比如说,在订单类 Order 中,Order 与 User 的关系就是单纯引用,User 是独立存在的,而 Order 与 OrderItem 的关系就是包含,OrderItem 总是从属于某一个 Order。
3.2.7 小结
对初学编程的人来说,不清楚如何用程序概念表示现实问题,本节通过一些简化的例子来解释,如何将现实中的概念映射为程序中的类。
分解现实问题中涉及的概念,以及概念间的关系,将概念表示为多个类,通过类之间的组合,来表达更为复杂的概念以及概念间的关系,是计算机程序的一种基本思维方式。
3.3 代码的组织机制
使用任何语言进行编程都有一个类似的问题,那就是如何组织代码,具体来说,如何避免命名冲突?如何合理组织各种源文件?如何使用第三方库?各种代码和依赖库如何编译连接为一个完整的程序?
本节就来讨论 Java 中的解决机制,具体包括包、jar 包、程序的编译与连接等。
3.3.1 包的概念
使用任何语言进行编程都有一个相同的问题,就是命名冲突。程序一般不全是一个人写的,会调用系统提供的代码、第三方库中的代码、项目中其他人写的代码等,不同的人就不同的目的可能定义同样的类名/接口名,Java 中解决这个问题的方法就是包。
即使代码都是一个人写的,将很多个关系不太大的类和接口都放在一起,也不便于理解和维护,Java 中组织类和接口的方式也是包。
包是一个比较容易理解的概念,类似于电脑中的文件夹,正如我们在电脑中管理文件,文件放在文件夹中一样,类和接口放在包中,为便于组织,文件夹一般是一个层次结构,包也类似。
包有包名,这个名称以号(.)分隔表示层次结构。比如说,我们之前常用的 String 类,就位于包 java.lang 下,其中 java 是上层包名, lang 是下层包名,带完整包名的类名称为其完全限定名,比如 String 类的完全限定名为 java.lang.String。Java API 中所有的类和接口都位于包 java 或 javax 下,java 是标准包,javax 是扩展包。
接下来,我们讨论包的细节,从声明类所在的包开始。
3.3.1.1 声明类所在的包
语法
我们之前定义类的时候没有定义其所在的包,默认情况下,类位于默认包下,使用默认包是不建议的,文章中使用默认包只是简单起见。
定义类的时候,应该先使用关键字 package,声明其包名,如下所示:
package shuo.laoma;
public class Hello {
//类的定义
}
以上声明类 Hello 的包名为 shuo.laoma,包声明语句应该位于源代码的最前面,前面不能有注释外的其他语句。
包名和文件目录结构必须匹配,如果源文件的根目录为 E:\src\,则上面的 Hello 类对应的文件 Hello.java,其全路径就应该是 E:\src\shuo\laoma\Hello.java。如果不匹配,Java 会提示编译错误。
命名冲突
为避免命名冲突,Java 中命名包名的一个惯例是使用域名作为前缀。因为域名是唯一的,一般按照域名的反序来定义包名,比如,域名是:apache.org,包名就以 org.apache 开头。
没有域名的,也没关系,使用一个其他代码不太会用的包名即可,比如本文使用的 “shuo.laoma”,表示"老马说编程"中的例子。
如果代码需要公开给其他人用,最好有一个域名以确保唯一性,如果只是内部使用,则确保内部没有其他代码使用该包名即可。
组织代码
除了避免命名冲突,包也是一种方便组织代码的机制。一般而言,同一个项目下的所有代码,都有一个相同的包前缀,这个前缀是唯一的,不会与其他代码重名,在项目内部,根据不同目的再细分为子包,子包可能又会分为子包,形成层次结构,内部实现一般位于比较底层的包。
包可以方便模块化开发,不同功能可以位于不同包内,不同开发人员负责不同的包。包也可以方便封装,供外部使用的类可以放在包的上层,而内部的实现细节则可以放在比较底层的子包内。
3.3.1.2 通过包实用类
同一个包下的类之间互相引用是不需要包名的,可以直接使用。但如果类不在同一个包内,则必须要知道其所在的包,使用有两种方式,一种是通过类的完全限定名,另外一种是将用到的类引入到当前类。
只有一个例外,java.lang 包下的类可以直接使用,不需要引入,也不需要使用完全限定名,比如 String 类,System 类,其他包内的类则不行。
比如说,使用 Arrays 类中的 sort 方法,通过完全限定名,可以这样使用:
int[] arr = new int[]{
1,4,2,3};
java.util.Arrays.sort(arr);
System.out.println(java.util.Arrays.toString(arr));
显然,这样比较繁琐,另外一种就是将该类引入到当前类,引入的关键字是 import,import 需要放在 package 定义之后,类定义之前,如下所示:
package shuo.laoma;
import java.util.Arrays;
public class Hello {
public static void main(String[] args) {
int[] arr = new int[]{
1,4,2,3};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
import 时,可以一次将某个包下的所有类引入,语法是使用 .* 。
比如,将 java.util 包下的所有类引入,语法是:
import java.util.*
需要注意的是,这个引入不能递归,它只会引入 java.util 包下的直接类,而不会引入 java.util 下嵌套包内的类,比如,不会引入包 java.util.zip 下面的类。试图嵌套引入的形式也是无效的,如
import java.util.*.*
在一个类内,对其他类的引用必须是唯一确定的,不能有重名的类,如果有,则通过 import 只能引入其中的一个类,其他同名的类则必须要使用完全限定名。
引入类是一个比较繁琐的工作,不过,大多数 Java 开发环境都提供工具自动做这件事,比如,在 Eclipse 中,通过菜单 “Source->Organize Imports” 或对应的快捷键 ctrl+shift+O 就可以自动管理引入类。
3.3.1.3 包范围可见性
前面章节我们介绍过,对于类、变量和方法,都可以有一个可见性修饰符,public/private/protected,而上节,我们提到可以不写修饰符。如果什么修饰符都不写,它的可见性范围就是同一个包内,同一个包内的其他类可以访问,而其他包内的类则不可以访问。
需要说明的是,同一个包指的是同一个直接包,子包下的类并不能访问。比如说,类 shuo.laoma.Hello 和 shuo.laoma.inner.Test,其所在的包 shuo.laoma 和 shuo.laoma.inner 是两个完全独立的包,并没有逻辑上的联系,Hello 类和 Test 类不能互相访问对方的包可见性方法和属性。
另外,需要说明的是 protected 修饰符,protected 可见性包括包可见性,也就是说,声明为 protected,不仅表明子类可以访问,还表明同一个包内的其他类可以访问,即使这些类不是子类也可以。
总结来说,可见性范围从小到大是:
private < 默认(包) < protected < public
3.3.2 jar 包
为方便使用第三方代码,也为了方便我们写的代码给其他人使用,各种程序语言大多有打包的概念,打包的一般不是源代码,而是编译后的代码,打包将多个编译后的文件打包为一个文件,方便其他程序调用。
在 Java 中,编译后的一个或多个包的 Java class 文件可以打包为一个文件,Java 中打包命令为 jar,打包后的文件后缀为 .jar,一般称之为 jar 包。
可以使用如下方式打包,首先到编译后的 java class 文件根目录,然后运行如下命令打包:
jar -cvf <包名>.jar <最上层包名>
比如,对前面介绍的类打包,如果 Hello.class 位于 E:\bin\shuo\laoma\Hello.class,则可以到目录 E:\bin 下,然后运行:
jar -cvf hello.jar shuo
hello.jar 就是 jar 包,jar 包其实就是一个压缩文件,可以使用解压缩工具打开。
Java 类库、第三方类库都是以 jar 包形式提供的。如何使用 jar 包呢?将其加入到类路径(classpath)中即可。
类路径是什么呢?我们下面来看。
3.3.3 程序的编译与连接
从 Java 源代码到运行的程序,有编译和连接两个步骤。编译是将源代码文件变成一种字节码,后缀是 .class 的文件,这个工作一般是由 javac 这个命令完成的。连接是在运行时动态执行的,.class 文件不能直接运行,运行的是 Java 虚拟机,虚拟机听起来比较抽象,执行的就是 java 这个命令,这个命令解析 .class 文件,转换为机器能识别的二进制代码,然后运行,所谓连接就是根据引用到的类加载相应的字节码并执行。
Java 编译和运行时,都需要以参数指定一个 classpath,即类路径。类路径可以有多个,对于直接的 class 文件,路径是 class 文件的根目录,对于 jar 包,路径是 jar 包的完整名称(包括路径和 jar 包名),在 Windows 系统中,多个路径用分号分隔,在其他系统中,以冒号分隔。
在 Java 源代码编译时,Java 编译器会确定引用的每个类的完全限定名,确定的方式是根据 import 语句和 classpath。如果 import 的是完全限定类名,则可以直接比较并确定。如果是模糊导入(import 带 .* ),则根据 classpath 找对应父包,再在父包下寻找是否有对应的类。如果多个模糊导入的包下都有同样的类名,则 Java 会提示编译错误,此时应该明确指定 import 哪个类。
Java 运行时,会根据类的完全限定名寻找并加载类。寻找的方式就是在类路径中寻找,如果是 class 文件的根目录,则直接查看是否有对应的子目录及文件,如果是 jar 文件,则首先在内存中解压文件,然后再查看是否有对应的类。
总结来说,import 是编译时概念,用于确定完全限定名,在运行时,只根据完全限定名寻找并加载类,编译和运行时都依赖类路径,类路径中的 jar 文件会被解压缩用于寻找和加载类。
3.3.4 小结
本节介绍了 Java 中代码组织的机制,包和 jar 包,以及程序的编译和连接。将类和接口放在合适的具有层次结构的包内,避免命名冲突,代码可以更为清晰,便于实现封装和模块化开发,通过 jar 包使用第三方代码,将自身代码打包为 jar 包供其他程序使用,这些都是解决复杂问题所必需的。