1. 简述
callbacks中文含义为回调。该模块主要是一些回调函数,即在模型训练的某个时刻执行该回调函数。如early stopping,模型训练过程中,发现n次效果都不再提升,即停止训练。
2. EarlyStopping
早停,第一章简述已经提过,其参数如下:
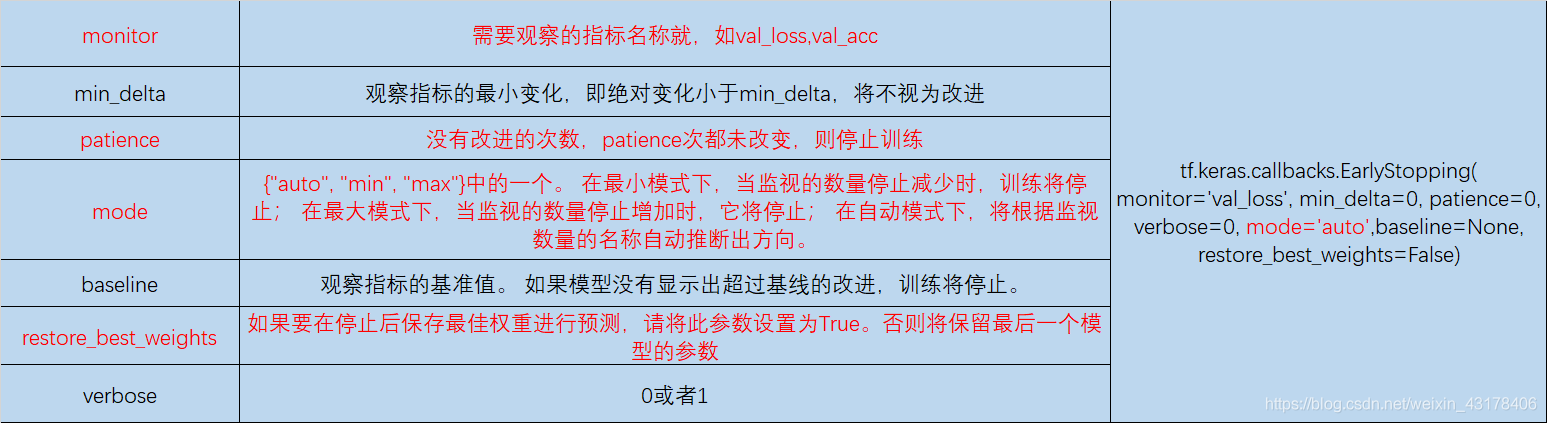
案例:
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])
model.compile(tf.keras.optimizers.SGD(), loss='mse')
history = model.fit(np.arange(100).reshape(5, 20), np.zeros(5),
epochs=10, batch_size=1, callbacks=[callback],
verbose=0)
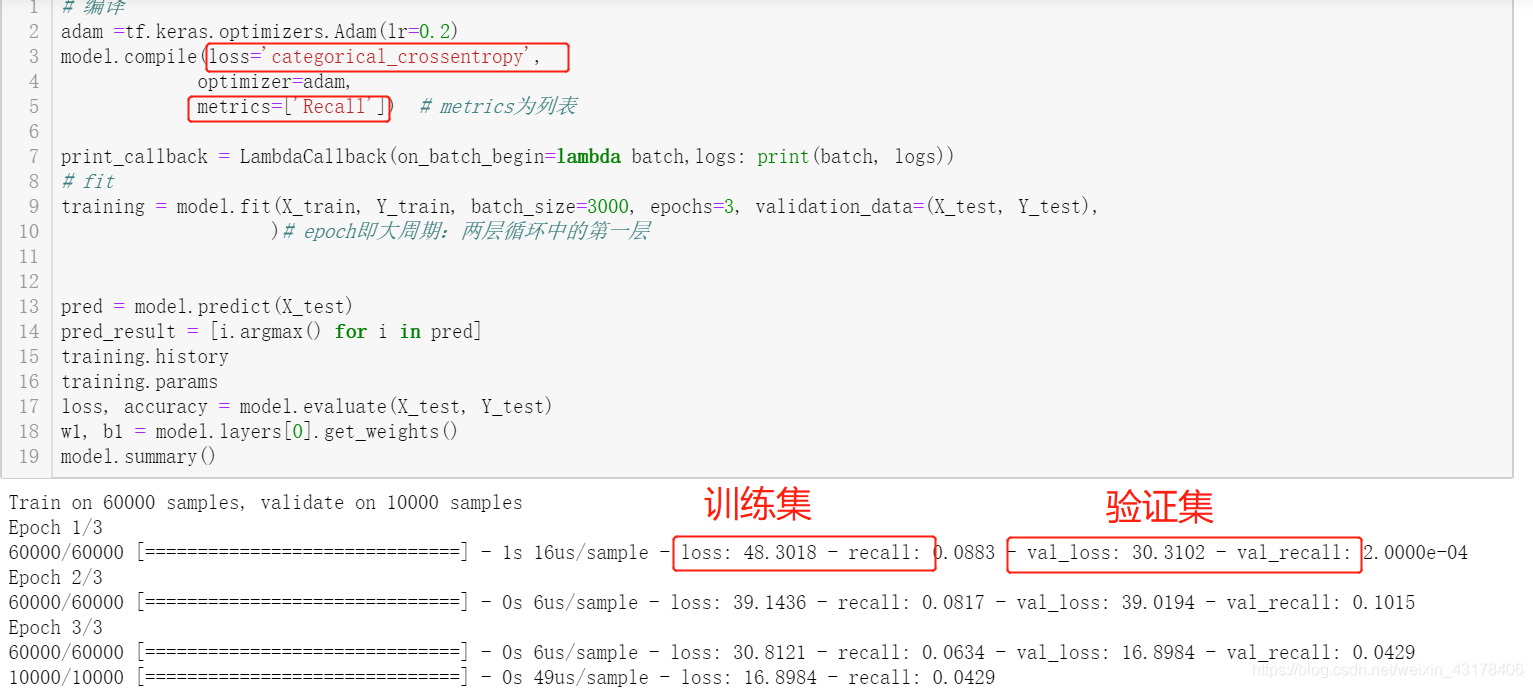
备注:这里的monitor是被观察指标,这个指标都有哪些取值,可参照第6章LambdaCallback:它是由每个epoch中的最后一个进度条决定的,最后一个进度条显示了训练集和验证集的loss(compile中的loss)及metrics(compile中的metrics),monitor可选择其中任何一个:
3. ModelCheckpoint
在模型训练的时候,我们需要保存模型,ModelCheckpoint即确定保存模型的时刻及保存符合某条件的模型。

注意上述参数中,只有save_freq为"epoch"时,filepath才能写成"model_{epoch:02d}-{val_acc:.2f}.hdf5"或者weight.{epoch:02d}-{val_acc:.2f}.hdf5等形式。
案例:
EPOCHS = 10
checkpoint_filepath = '/tmp/model.h5'
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=True,
monitor='val_acc',
mode='max',
save_best_only=True)
# Model weights are saved at the end of every epoch, if it's the best seen
# so far.
model.fit(epochs=EPOCHS, callbacks=[model_checkpoint_callback])
# The model weights (that are considered the best) are loaded into the model.
model.load_weights(checkpoint_filepath)
4. History
该回调函数,自动应用于每个keras模型的fit方法
如第二章讲述EarlyStopping时的案例。直接history=model.fit(…),也不需要from tensorflow.keras.callbacks import History。history记录了训练过程中的结果,如每个epoch的train_loss/train_acc/val_loss/val_acc等。
5. LearningRateSchedule
该函数为动态调整学习率(每个epoch的初始学习率不同),其默认表达如下:
tf.keras.callbacks.LearningRateScheduler(
schedule, verbose=0
)
可以看到一个重要参数schedule,该参数为自定义函数,输入为epoch,输入为浮点型的学习率。通过以下案例说明:
def scheduler(epoch):
if epoch < 10:
return 0.001
else:
return 0.001 * tf.math.exp(0.1 * (10 - epoch))
callback = tf.keras.callbacks.LearningRateScheduler(scheduler)
model.fit(data, labels, epochs=100, callbacks=[callback],
validation_data=(val_data, val_labels))
以下为实际当中的一个例子
def schedule(epoch_idx):
if epoch_idx < 10:
return 0.1 / 10 * (epoch_idx+1)
else:
t = (epoch_idx - 10) * math.pi / 90
return 1/2 * (1 + math.cos(t)) * 0.1
scheduler = LearningRateScheduler(schedule=schedule)
model = bi_lstm_attention(max_len, max_cnt, embed_size, embedding_matrix) # 模型实例化
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=0.0, momentum=0.9, decay=0.0,
nesterov=False),
metrics=['accuracy']) # 使用了学习率调整,sgd的lr可设置为0
history = model.fit(X_train, X_train_label,
validation_data=(X_val, X_val_label),
epochs=100, batch_size=64,
shuffle=True,
callbacks=[early_stopping, scheduler],
)
学习率调整的方法,见博客:https://www.cnblogs.com/xym4869/p/11654611.html,keras中的具体实现后续补充
6. LambdaCallback
其结构如下:
tf.keras.callbacks.LambdaCallback(
on_epoch_begin=None, on_epoch_end=None, on_batch_begin=None,
on_batch_end=None,
on_train_begin=None, on_train_end=None, **kwargs
)
每一个参数都是一个lambda的函数,lambda函数必须有两个参数或一个参数,具体要求如下:

举例:
print_callback = LambdaCallback(on_batch_begin=lambda batch,logs: print(batch, logs),
on_batch_end=lambda batch, logs:print('=', batch, logs)
)
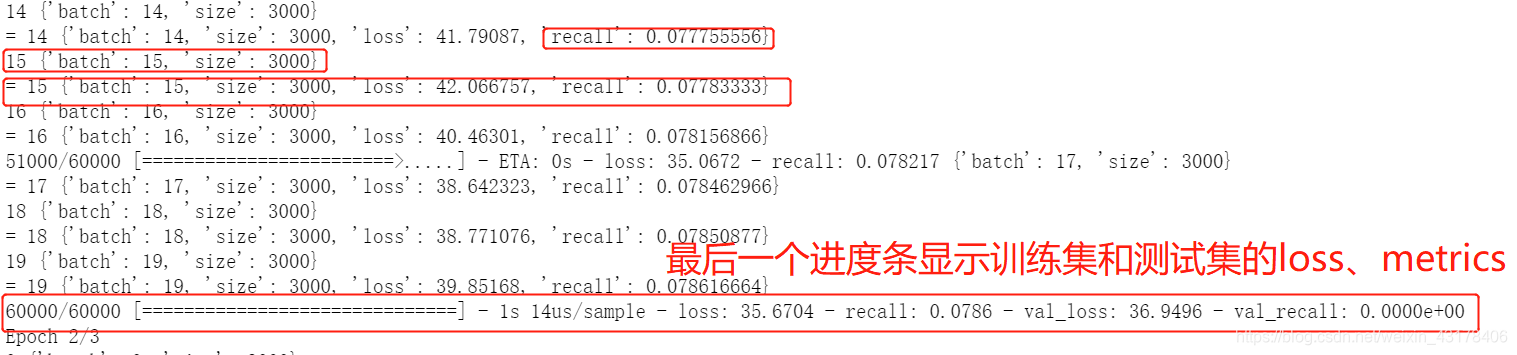
on_batch_begin表示在每个batch的开始,on_batch_end表示在每个batch的结尾。其某案例结果如下所示:

上图中进度条显示的是loss和acc,其中loss由compile的loss决定,acc由compile的metrics决定,如果 metrics=[‘Recall’],则结果如下图:
官网另一个例子如下:
# Stream the epoch loss to a file in JSON format. The file content
# is not well-formed JSON but rather has a JSON object per line.
import json
json_log = open('loss_log.json', mode='wt', buffering=1)
json_logging_callback = LambdaCallback(
on_epoch_end=lambda epoch, logs: json_log.write(
json.dumps({'epoch': epoch, 'loss': logs['loss']}) + '\n'), # 每个epoch结束后将epoch、loss写入文件
on_train_end=lambda logs: json_log.close() # 训练结束后关闭句柄
)