功能介绍:在给定的文本文件之中统计出每个单词出现的次数
实现流程分析
- 输入数据:test.txt

- 期望输出数据:
monkey 2
pandas 1
tiger 2
owl 1
cat 1
dog 3 - 按照MapReduce编程规范编写程序
- Mapper
- 将MapTask传给我们的文本内容转为String
- 将String切分为单独的单词
- 将每个单词输出KV对<单词,1>
- Reducer
- 汇总每个key(也就是每个单词)的个数
- 输出每个key的总次数
- Driver
- 获取配置信息,获取Job对象实例
- 指定本程序的jar包所在的本地路径
- 关联Mapper/Reducer业务类
- 指定Mapper输出数据的kv类型
- 指定最终输出的数据的kv类型
- 指定job的输入原始文件所在目录
- 指定job的输出结果所在目录
- 提交作业
- Mapper
具体实现
-
环境准备
1.1 创建一个maven工程。
1.2 加入如下依赖:<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> </dependencies>1.3 编写log4j的配置文件log4j.properties
### direct log messages to stdout ### log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n log4j.rootLogger=debug, stdout -
编写程序
2.1 编写Mapper类package org.hadoop.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; // map阶段 public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1.从文件读取一行 eg: monkey monkey String line = value.toString(); // 2.切割字符串 String[] words = line.split(" "); // 3.循环写出 for (String word:words){ // monkey k.set(word); // 写出 context.write(k,v); } } }2.2 编写Reducer类
package org.hadoop.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 佛祖保佑 永无BUG **/ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //<monkey,1> <monkey,1> int sum = 0; // 1.对输入数据累加求和 for (IntWritable value : values) { sum += value.get(); } IntWritable v = new IntWritable(); v.set(sum); // 2.写出 <monkey,2> context.write(key,v); } }2.3 编写Driver类
package org.hadoop.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 佛祖保佑 永无BUG **/ public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); // 1.获取job对象 Job job = Job.getInstance(conf); // 2.设置jar存放路径(位置) job.setJarByClass(WordCountDriver.class); // 3.关联Map和Reduce类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 4.设置Map阶段输出数据的key&value类型 job.setMapOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 5.设置最终数据输出的key&value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6.设置文本的数据输入路径和结果的输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); // 7.提交job boolean res = job.waitForCompletion(true); System.out.println(res); } }2.4 测试运行
运行时传入2个参数,第一个是输入文件路径,第二个是结果输出文件路径:
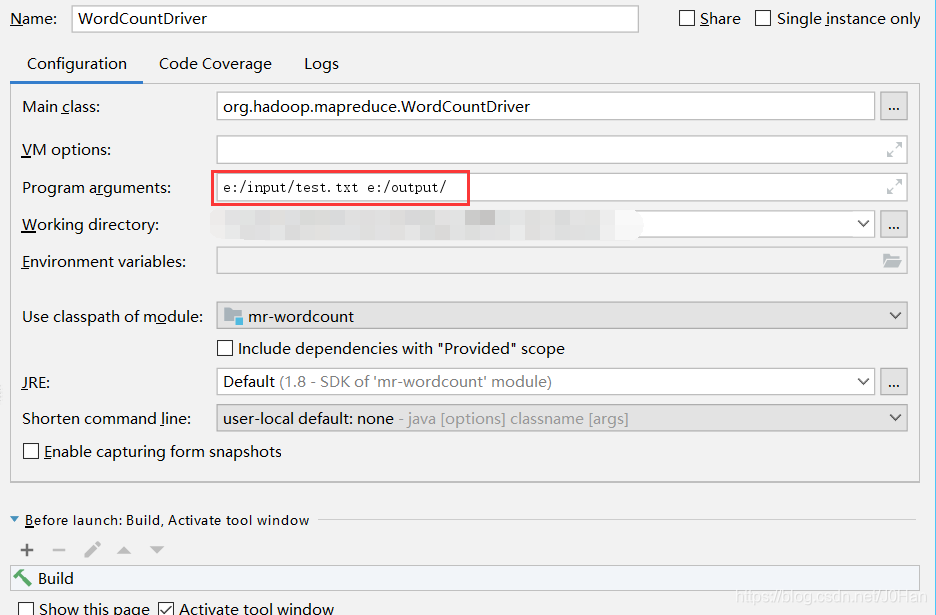
运行成功截图:

进入output文件夹:

打开最后一个part-r-00000文件:
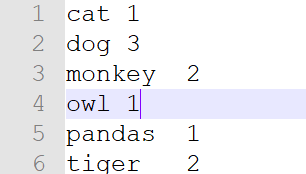
可以看到程序统计出来的结果与预期的结果相同。