强化学习四元组< S, A, P, R >

这是一个跟时间相关的序列决策问题:
- 在 t-1 时刻,我看到了熊对我招手,那么我下意识的动作即输出的动作是马上逃跑
- 那么在t时刻,熊看到我在跑,就认为发现了猎物,便会发动攻击,这时如果选择装死
- 那么在 t+1 时刻,熊可能会选择离开,这时我们再选择逃跑,那么大概率就能逃跑成功
将这个序列转化为一棵树,那么它就是一个典型的Markov决策过程:

总结为一句话:就是在S的条件下,以概率分布P选择A,而获得奖励R。
由此,我们可以知道影响我们决策的就是R的大小,而R的大小是又由之前的一系列A累计决定的。那么,我们在决策时,就不能只顾及眼前的R,而应该是顾及系列的A所产生的R。所以我们引入了折扣因子γ,来平衡眼前的R和长远的R:
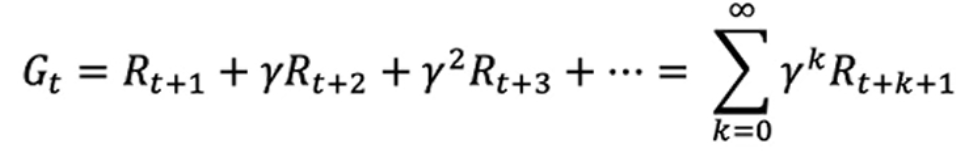
于是,我们可以根据每一个状态S下对应A的R来作为决策到此动作的概率画出一张表格:

训练一段时间后,我们就可以根据这个表找到最优的策略:

扫描二维码关注公众号,回复:
12039934 查看本文章

Sarsa
Sarsa全称是state-action-reward-state'-action',目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
Sarsa在训练中为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。
Q-learning
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。Q-learning跟Sarsa不一样的地方是更新Q表格的方式。Sarsa是on-policy的更新方式,先做出动作再更新。Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。
总结来说,sarsa是在选取下个状态的动作时,是依据分布概率来决定;而Q-learing则是在下个状态中选取收益最大的动作。
因此,sarsa更加保守,而Q-learing则更容易找到最优解。
Agent的定义
Agent是和环境environment交互的主体。predict()方法:输入观察值observation(或者说状态state),输出动作值sample()方法:再predict()方法基础上使用ε-greedy增加探索learn()方法:输入训练数据,完成一轮Q表格的更新
代码详解
import gym
import time
import numpy as np
class QLearningAgent(object):
def __init__(self, obs_n, act_n, learning_rate=0.01, gamma=0.9, e_greed=0.1):
self.act_n = act_n # 动作维度,有几个动作可选
self.lr = learning_rate # 学习率
self.gamma = gamma # reward的衰减率
self.epsilon = e_greed # 按一定概率随机选动作
self.Q = np.zeros((obs_n, act_n))
# 根据输入观察值,采样输出的动作值,带探索
def sample(self, obs):
######################################################################
######################################################################
#
# 1. 请完成sample函数功能
#
######################################################################
######################################################################
if np.random.uniform(0,1) < (1.0 -self.epsilon):
action = self.predict(obs)
else:
action = np.random.choice(self.act_n)
return action
# 根据输入观察值,预测输出的动作值
def predict(self, obs):
######################################################################
######################################################################
#
# 2. 请完成predict函数功能
#
######################################################################
######################################################################
Q_list = self.Q[obs,:]
maxQ = np.max(Q_list)
action_list = np.where(Q_list == maxQ)[0]
action = np.random.choice(action_list)
return action
# 学习方法,也就是更新Q-table的方法
def learn(self, obs, action, reward, next_obs, done):
""" off-policy
obs: 交互前的obs, s_t
action: 本次交互选择的action, a_t
reward: 本次动作获得的奖励r
next_obs: 本次交互后的obs, s_t+1
done: episode是否结束
"""
######################################################################
######################################################################
#
# 3. 请完成learn函数功能(Q-learning)
#与sarsa不同学习时,采用off-learning策略
######################################################################
######################################################################
predict_Q = self.Q[obs,action]
if done:
target_Q = reward
else:
target_Q = reward+self.gamma*np.max(self.Q[next_obs,:])
#更新下一步时,选择奖励最大的action
#target_Q = reward + self.gamma * self.Q[next_obs, next_action]
# Sarsa更新下一步后,再根据下一步的情况来跟新Q
self.Q[obs,action] += self.lr*(target_Q - predict_Q)
# 保存Q表格数据到文件
def save(self):
npy_file = './q_table.npy'
np.save(npy_file, self.Q)
print(npy_file + ' saved.')
# 从文件中读取数据到Q表格中
def restore(self, npy_file='./q_table.npy'):
self.Q = np.load(npy_file)
print(npy_file + ' loaded.')实验结果对比
sarsa

可见乌龟为了防止掉下悬崖,会远远的避开它,到迫不得以时才冒险向出口靠近。
q-learning

直接冒着风险迅速地向出口靠近。