1 概念
1. 索引具有两个功能:
(1) 强制实施 "主键约束" 和 "唯一性约束"
(2) 提高性能
2. 提示:
(1) 对于使用 where 子句的 select、update、delete 或 merge 语句而言,
索引可以起到辅助作用
(2) 但对于 insert 而言,索引会降低处理速度。
原因:每次在表中插入一行时,必须在表的每个索引中插入一个新键。
2 索引类型
2.1 B-Tree 索引
1. B-Tree 索引(B 代表 "平衡(balanced)") 是一种树结构 -- 不是 "二叉树" 哦
2. 树的 '根节点' 指向 '第二级别' 的多个节点,'第二级别' 的节点又指向 '第三级别' 的多个节点,以此类推。
3. B-Tree 索引是 Oracle 默认的索引类型
B-Tree 索引适用场景:
1. 列的基数很大(不同值的个数很多)
2. 一般认为,如果查询要检索 "低于" 2%~4% 的行,'B-Tree 索引' 合适,
如果查询要检测 "高于" 2%~4% 的行,则 '全表扫描' 更快
原理图示:读取数据块过程演示
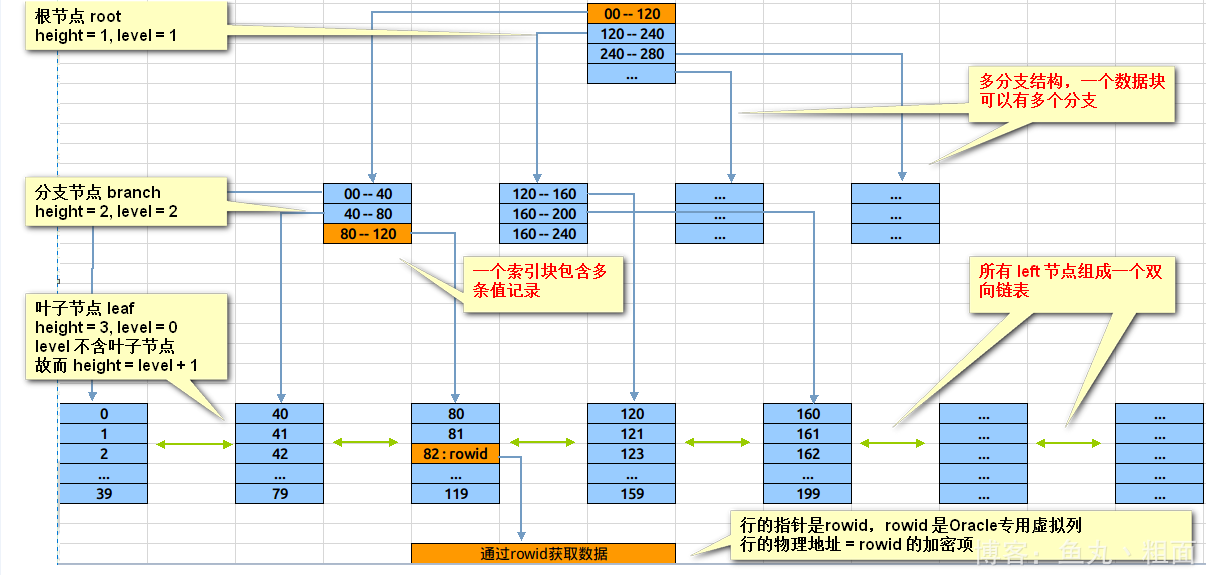 案例分析:定位数值 82 的过程
案例分析:定位数值 82 的过程
- 读取 root 节点,判断 82 在 0-120 之间,走左边分支
- 读取左边 branch 节点,判断 82 在80-120 之间,走右边分支
- 读取右边 leat 节点,在该节点中找到数据 82 及对应的 rowid
- 使用 rowid 去物理表中读取记录数据库块(如果是 count 或 仅 select rowid,则不需要本次读取)
上述案例中:
1、在整个索引定位过程中,数据块的读取只有 3 次。既三次I/O后定位到rowid。
2、在整个扩张过程中,B-Tree 自身总能保持平衡,Leaf 节点的深度能一直保持一致。(故而为“平衡树”)
2.2 位图索引(bitmap)
适用场景:
1. 列的基数很小(不同值的个数少)
2. 列用于布尔代数运算(and、or、not)
原理图示:
| 姓名(Name) | 性别(Gender) | 身份证(ID_Card) | 婚姻状况(Marital) |
|---|---|---|---|
| n1 | 男 | 421… | 未婚 |
| n2 | 女 | 422… | 已婚 |
| n3 | 女 | 421… | 未婚 |
| n4 | 男 | 422… | 离婚 |
| n5 | 女 | 422… | 未婚 |
| 。。。 | 。。。 | 。。。 | 。。。 |
案例分析:现有以下查询
SELECT * FROM table t WHERE t.Gender = "女" AND t.Marital = "未婚";
全表扫描 FULL 和 B-Tree 索引 的使用情况分析:
1. 不适用索引
(1) 不使用索引时,数据库只能一行行扫描所有记录,然后判断该记录是否满足查询条件
(2) 一般情况下,当取出来的数据超过表 2%~4% 时,比较合适
2. B-Tree 索引
(1) 对于 "性别(Gender)",可取值的范围只有 '男','女',并且男和女可能各站该表的 '50%' 的数据,
这时添加 'B-Tree 索引' 还是需要取出一半的数据, 因此完全没有必要。
(2) 相反,如果某个字段的取值 "范围很广,几乎没有重复",比如 "身份证号",使用 'B-Tree 索引' 比较合适
(3) 事实上,当取出来的数据超过表 2%~4% 时,即使添加了 'B-Tree 索引',
Oracle 也不一定会使用 'B-Tree 索引',很可能 Oracle 解析器认为 '全表扫描' 更加好
位图索引原理:
- 如果在 性别(Gender) 列上建立了
位图索引,对于 性别(Gender) 这个列,针对每行的rowid(rowid可以理解为每行的物理位置),位图索引形成两个向量, - 男:10010, 女:01101
- 其中 1:表示男,0:表示女。
| Rowid | 1 | 2 | 3 | 4 | 5 | … |
|---|---|---|---|---|---|---|
| 男 | 1 | 0 | 0 | 1 | 0 | … |
| 女 | 0 | 1 | 1 | 0 | 1 | … |
同理:婚姻状况(Marital) 的 位图索引如下
| Rowid | 1 | 2 | 3 | 4 | 5 | … |
|---|---|---|---|---|---|---|
| 已婚 | 0 | 1 | 0 | 0 | 0 | … |
| 未婚 | 1 | 0 | 1 | 0 | 1 | … |
| 离婚 | 0 | 0 | 0 | 1 | 0 | … |
位图检索过程: (与运算,全 1 得 1)
| Rowid | 1 | 2 | 3 |
4 | 5 |
… |
|---|---|---|---|---|---|---|
| 女 | 0 | 1 | 1 |
0 | 1 |
… |
| and | … | |||||
| 未婚 | 1 | 0 | 1 |
0 | 1 |
… |
| 结果 | 0 | 0 | 1 |
0 | 1 |
… |
3 语法
数据准备:(提示:主键 自带 ‘唯一约束 unique’ 索引:不允许插入重复值 )
CREATE TABLE odsdata.student_info (
student_no VARCHAR2(10),
NAME VARCHAR2(30),
sex VARCHAR2(2),
age NUMBER(3)
);
ALTER TABLE odsdata.student_info ADD CONSTRAINT fk_student_info_student_no PRIMARY KEY(student_no);
查询约束信息:
SELECT t.*
FROM all_constraints t -- dba_constraints
WHERE t.owner = 'ODSDATA'
AND t.table_name = 'STUDENT_INFO';
3.1 创建索引
语法:
create [unique | bitmap] index [schema.] 索引名
on [schema.] 表名 (列名1, .., 列名N);
-- 创建一般索引(B-Tree 索引)
CREATE INDEX odsdata.idx_student_info_name ON odsdata.student_info (name);
-- 创建位图索引
CREATE BITMAP INDEX odsdata.bidx_student_info_sex ON odsdata.student_info (sex);
3.2 删除索引
drop index [schema.] 索引名;
DROP INDEX odsdata.idx_student_info_name;
3.3 修改索引
-- 修改索引名称 idx_student_info_name -> idx_student_info_new_name
ALTER INDEX odsdata.idx_student_info_name RENAME TO odsdata.idx_student_info_new_name;
-- 修改索引为无效
ALTER INDEX odsdata.idx_student_info_name UNUSABLE;
-- 重建索引
ALTER INDEX odsdata.idx_student_info_name REBUILD [ONLINE];
3.4 查询索引
SELECT t.*
FROM dba_indexes t -- all_indexes, user_indexes
WHERE t.owner = 'ODSDATA'
AND t.table_name = 'STUDENT_INFO';
4 扩展
如何查询索引中的信息,比如 height?
> ANALYZE INDEX odsdata.idx_student_info_name VALIDATE STRUCTURE;
>
> SELECT t.* FROM index_stats t;