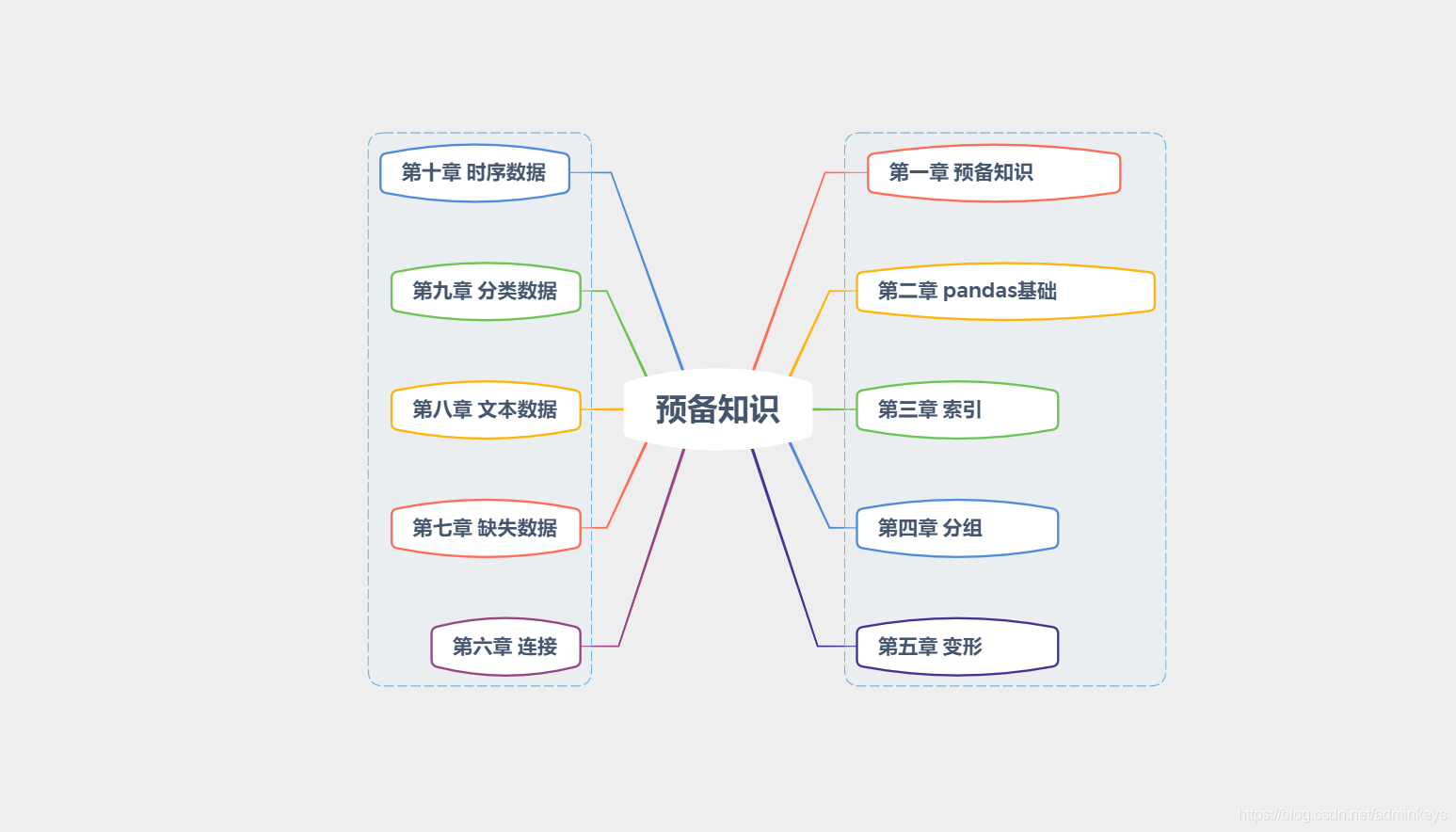
二、pandas基础
学习大纲:
目录

补充:
简单介绍一下pandas:(以下来源百度百科)
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。
理解:
pandas就和excel类似,它使用表(也就是 dataframe),能在数据上做各种变换,但还有其他很多功能,比如读取csv,excel,txt文件等等。
上次用到了爬虫做可视化分析,所以读取csv文件
import pandas as pd
import numpy as np
df = pd.read_csv("/Python/京东/羽绒服.csv")
df.sample(10)Pandas 适用于处理以下类型的数据:
与 SQL 或 Excel 表类似的,含异构列的表格数据;
有序和无序(非固定频率)的时间序列数据;
带行列标签的矩阵数据,包括同构或异构型数据;
任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas的优势
处理浮点与非浮点数据里的缺失数据,表示为 NaN;
大小可变:插入或删除 DataFrame 等多维对象的列;
自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在Series、DataFrame 计算时自动与数据对齐;
强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
直观地合并(merge)、**连接(join)**数据集;
灵活地重塑(reshape)、**透视(pivot)**数据集;
轴支持结构化标签:一个刻度支持多个标签;
成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存 / 加载数据;
时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
Pandas 速度很快。Pandas 的很多底层算法都用 Cython 优化过。然而,为了保持通用性,必然要牺牲一些性能,如果专注某一功能,完全可以开发出比 Pandas 更快的专用工具。
Pandas 是 statsmodels 的依赖项,因此,Pandas 也是 Python 中统计计算生态系统的重要组成部分。
Pandas 已广泛应用于金融领域。
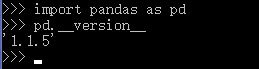
在这里确保pandas的版本在不小于1.1.0,我的版本是1.1.5符合条件
一、文件的读取和写入
1.1 文件读取
接下来,我们下载数据集,进行一个实战操作:读取csv、txt、xlsx文件

注意:
这里有一些常用的公共参数,
header=None表示第一行不作为列名,index_col表示把某一列或几列作为索引,索引的内容将会在第三章进行详述,usecols表示读取列的集合,默认读取所有的列,parse_dates表示需要转化为时间的列,关于时间序列的有关内容将在第十章讲解,nrows表示读取的数据行数。上面这些参数在上述的三个函数里都可以使用。
实例:


注意:
在读取
txt文件时,经常遇到分隔符非空格的情况,
read_table有一个分割参数sep,它使得用户可以自定义分割符号,进行txt数据的读取。例如,下面的读取的表以||||为分割:
pd.read_table('../data/my_table_special_sep.txt')
效果不佳,我们可以使用
sep,同时需要指定引擎为python
pd.read_table('../data/my_table_special_sep.txt', sep=' \|\|\|\| ', engine='python')
1.1.1 【WARNING】sep是正则参数
- 在使用
read_table的时候需要注意,参数sep中使用的是正则表达式- 因此需要对
|进行转义变成\|,否则无法读取到正确的结果。
1.2 数据写入
一般在数据写入中,最常用的操作是把
index设置为False,特别当索引没有特殊意义的时候,这样的行为能把索引在保存的时候去除。
df_csv.to_csv('../data/my_csv_saved.csv', index=False)
df_excel.to_excel('../data/my_excel_saved.xlsx', index=False)
pandas中没有定义to_table函数,但是to_csv可以保存为txt文件,并且允许自定义分隔符,常用制表符\t分割:
df_txt.to_csv('../data/my_txt_saved.txt', sep='\t', index=False)如果想要把表格快速转换为
markdown和latex语言,可以使用to_markdown和to_latex函数,此处需要安装tabulate包。
两种办法:
- print(df_csv.to_markdown()) #转化为markdown
- print(df_csv.to_latex()) #转化为latex
二、基本数据结构
pandas中具有两种基本的数据存储结构,存储一维values的Series和存储二维values的DataFrame,在这两种结构上定义了很多的属性和方法。
2.1 Series
Series一般由四个部分组成,分别是- 序列的值
data、索引index、存储类型dtype、序列的名字name。- 其中,索引也可以指定它的名字,默认为空。
- 对于这些属性,可以通过 . 的方式来获取
- s.values
- s.index
- s.dtype
- s.name
- 利用
.shape可以获取序列的长度 :s.shape- 索引是
pandas中最重要的概念之一,它将在第三章中被详细地讨论。如果想要取出单个索引对应的值,可以通过[index_item]可以取出。
注意:
object类型
object代表了一种混合类型,正如上面的例子中存储了整数、字符串以及Python的字典数据结构。- 目前
pandas把纯字符串序列也默认认为是一种object类型的序列,但它也可以用string类型存储。
2.2 DataFrame
DataFrame在Series的基础上增加了列索引,一个数据框可以由二维的data与行列索引来构造- 更多的时候会采用从列索引名到数据的映射来构造数据框,同时再加上行索引
- 由于这种映射关系,在
DataFrame中可以用[col_name]与[col_list]来取出相应的列与由多个列组成的表,结果分别为Series和DataFrame- 通过
.T可以把DataFrame进行转置- 与
Series类似,在数据框中同样可以取出相应的属性
三、常用基本函数
3.1 汇总函数
head, tail函数分别表示返回表或者序列的前n行和后n行,其中n默认为5info, describe分别返回表的信息概况和表中数值列对应的主要统计量info, describe只能实现较少信息的展示,如果想要对一份数据集进行全面且有效的观察,特别是在列较多的情况下,推荐使用pandas-profiling包
3.2 特征统计函数
- 在
Series和DataFrame上定义了许多统计函数,最常见的是sum, mean, median, var, std, max, minquantile, count, idxmax这三个函数,它们分别返回的是分位数、非缺失值个数、最大值对应的索引- 上面这些所有的函数,由于操作后返回的是标量,所以又称为聚合函数,它们有一个公共参数
axis,默认为0代表逐列聚合,如果设置为1则表示逐行聚合
3.3 唯一值函数
- 对序列使用
unique和nunique可以分别得到其唯一值组成的列表和唯一值的个数value_counts可以得到唯一值和其对应出现的频数- 如果想要观察多个列组合的唯一值,可以使用
drop_duplicates。其中的关键参数是keep,默认值first表示每个组合保留第一次出现的所在行,last表示保留最后一次出现的所在行,False表示把所有重复组合所在的行剔除- 此外,
duplicated和drop_duplicates的功能类似,但前者返回了是否为唯一值的布尔列表,其keep参数与后者一致。其返回的序列,把重复元素设为True,否则为False。drop_duplicates等价于把duplicated为True的对应行剔除
3.4 替换函数
- 一般而言,替换操作是针对某一个列进行的,因此下面的例子都以
Series举例。pandas中的替换函数可以归纳为三类:映射替换、逻辑替换、数值替换。- 在
replace中,可以通过字典构造,或者传入两个列表来进行替换- 另外,
replace还有一种特殊的方向替换,指定method参数为ffill则为用前面一个最近的未被替换的值进行替换,bfill则使用后面最近的未被替换的值进行替换。- 正则替换请使用
str.replace,虽然对于replace而言可以使用正则替换,但是当前版本下对于string类型的正则替换还存在bug,因此如有此需求,请选择str.replace进行替换操作- 逻辑替换包括了
where和mask,这两个函数是完全对称的:where函数在传入条件为False的对应行进行替换,而mask在传入条件为True的对应行进行替换,当不指定替换值时,替换为缺失值。
注意:
- 传入的条件只需是与被调用的
Series索引一致的布尔序列即可- 数值替换包含了
round, abs, clip方法,它们分别表示取整、取绝对值和截断
3.5 排序函数
排序共有两种方式,其一为值排序,其二为索引排序,对应的函数是sort_values和sort_index。
- 对身高进行排序,默认参数
ascending=True为升序- 在排序中,进场遇到多列排序的问题,比如在体重相同的情况下,对身高进行排序,并且保持身高降序排列,体重升序排列
- 索引排序的用法和值排序完全一致,只不过元素的值在索引中,此时需要指定索引层的名字或者层号,用参数
level表示。另外,需要注意的是字符串的排列顺序由字母顺序决定。
3.6 apply方法
apply方法常用于DataFrame的行迭代或者列迭代,它的axis含义与统计聚合函数一致,apply的参数往往是一个以序列为输入的函数。
- 可以利用
lambda表达式使得书写简洁- 若指定
axis=1,那么每次传入函数的就是行元素组成的Series,其结果与之前的逐行均值结果一致- 谨慎使用
apply,apply的自由度很高,但这是以性能为代价的。一般而言,使用pandas的内置函数处理和apply来处理同一个任务,其速度会相差较多,因此只有在确实存在自定义需求的情境下才考虑使用apply。
四、窗口对象
pandas中有3类窗口,分别是滑动窗口rolling、扩张窗口expanding以及指数加权窗口ewm。
4.1 滑窗对象
- 要使用滑窗函数,就必须先要对一个序列使用
.rolling得到滑窗对象,其最重要的参数为窗口大小window。- 在得到了滑窗对象后,能够使用相应的聚合函数进行计算,需要注意的是窗口包含当前行所在的元素
shift, diff, pct_change是一组类滑窗函数,它们的公共参数为periods=n,默认为1,分别表示取向前第n个元素的值、与向前第n个元素做差(与Numpy中不同,后者表示n阶差分)、与向前第n个元素相比计算增长率
4.2 扩张窗口
- 扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。
- 具体地说,设序列为a1, a2, a3, a4,则其每个位置对应的窗口即[a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]
放一张楠楠画的图,方便理解:

五、练习
Ex1:口袋妖怪数据集
现有一份口袋妖怪的数据集,下面进行一些背景说明:
#代表全国图鉴编号,不同行存在相同数字则表示为该妖怪的不同状态妖怪具有单属性和双属性两种,对于单属性的妖怪,
Type 2为缺失值
Total, HP, Attack, Defense, Sp. Atk, Sp. Def, Speed分别代表种族值、体力、物攻、防御、特攻、特防、速度,其中种族值为后6项之和



df_demo=df.drop_duplicates(['#'])
print(df_demo['Type 1'].nunique())
print(df['Type 1'].value_counts().sort_values(ascending=False).head(3).index)
print(df_demo.drop_duplicates(['Type 1','Type 2']).shape[0])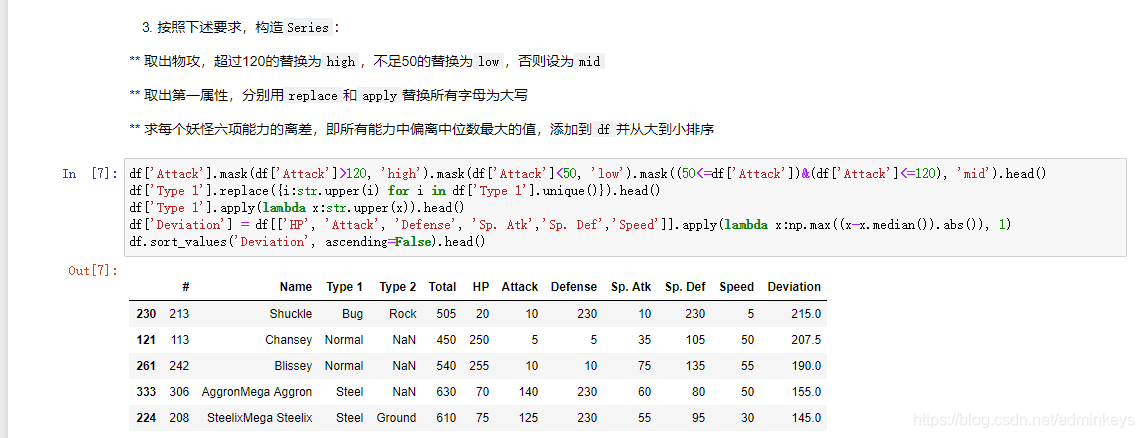
Ex2:指数加权窗口

请用
expanding窗口实现:
np.random.seed(0)
s = pd.Series(np.random.randint(-1,2,30).cumsum())
s.ewm(alpha=0.2).mean().head()
def ewm_func(x, alpha=0.2):
win = (1-alpha)**np.arange(x.shape[0])[::-1]
res = (win*x).sum()/win.sum()
return res
s.expanding().apply(ewm_func).head()
作为滑动窗口的
ewm窗口从第1问中可以看到,
ewm作为一种扩张窗口的特例,只能从序列的第一个元素开始加权。现在希望给定一个限制窗口
n,只对包含自身最近的n个窗口进行滑动加权平滑。请根据滑窗函数,给出新的wi与yt的更新公式,并通过rolling窗口实现这一功能。

学习心得:
因为近期接学习ML触到数据科学,所以开始了对numpy和pandas的学习,当然实战项目需求也是十分严格的,打牢基础才能为下一步继续学习数据科学提供动力,但是这个题是有点难,不会写,先去吃个饭,等会回来再看这个。