
1.概述
本文章会记录在当当网的开源框架 ElasticJob的学习案例
2.任务调度框架 Quartz
在ElasticJob中,底层分封装了Quartz,所以我们先来看下Quartz的相关知识
2.1 cron表达式简介
创建作业任务时间触发器(类似于公交⻋出⻋时间表)
cron表达式由七个位置组成,空格分隔
-
1、Seconds(秒) 0~59
-
2、Minutes(分) 0~59
-
3、Hours(⼩时) 0~23
-
4、Day of Month(天)1~31,注意有的⽉份不⾜31天
-
5、Month(⽉) 0~11,或者
JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC -
6、Day of Week(周) 1~7,1=SUN或者 SUN,MON,TUE,WEB,THU,FRI,SAT
-
7、Year(年)1970~2099 可选项
示例:
* 0 0 11 * * ? 每天的11点触发执⾏⼀次
* 0 30 10 1 * ? 每⽉1号上午10点半触发执⾏⼀次
2.2 配置pom文件
<dependencies>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
</dependencies>
2.3 主体代码
public class QuartzMain {
//创建一个调度器
public static Scheduler createScheduler() throws SchedulerException {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
return scheduler;
}
//创建一个任务详情
public static JobDetail createJob(){
JobBuilder jobBuilder = JobBuilder.newJob(DemoJob.class);
jobBuilder.withIdentity("jobName","myJob");
JobDetail jobDetail = jobBuilder.build();
return jobDetail;
}
//创建一个触发器
public static Trigger createTrigger(){
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName", "myTrigger")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("*/2 * * * * ?"))
.build();
return trigger;
}
//执行主体内容
public static void main(String[] args) throws SchedulerException {
Scheduler scheduler = QuartzMain.createScheduler();
JobDetail job = QuartzMain.createJob();
Trigger trigger = QuartzMain.createTrigger();
scheduler.scheduleJob(job,trigger);
scheduler.start();
}
}
演示效果如下,没两秒钟打印输出任务
我是一个定时任务
我是一个定时任务
我是一个定时任务
3.分布式调度框架Elastic-Job
3.1 简介
Elastic-Job 是当当⽹开源的⼀个分布式调度解决⽅案,基于Quartz⼆次开发的,由两个相互独⽴的⼦项⽬Elastic-Job-Lite和Elastic-Job-Cloud组成
Elastic-Job-Lite 轻量级⽆中⼼化解决⽅案,使⽤Jar包的形式提供分布式任务的协调服务
Elastic-Job-Cloud 需要结合Mesos以及Docker在云环境下使⽤。
3.2 主要功能
-
【分布式调度协调】 在分布式环境中,任务能够按指定的调度策略执⾏,并且能够避免同⼀任务多实例重复执⾏
-
【丰富的调度策略】基于成熟的定时任务作业框架Quartz cron表达式执⾏定时任务
-
【弹性扩容缩容】 当集群中增加某⼀个实例,它应当也能够被选举并执⾏任务;当集群减少⼀个实例
时,它所执⾏的任务能被转移到别的实例来执⾏。
-
【失效转移】某实例在任务执⾏失败后,会被转移到其他实例执⾏
-
【错过执⾏作业重触发】 若因某种原因导致作业错过执⾏,⾃动记录错过执⾏的作业,并在上次作业
完成后⾃动触发。
-
【⽀持并⾏调度】 ⽀持任务分⽚,任务分⽚是指将⼀个任务分为多个⼩任务项在多个实例同时执⾏。
-
【作业分⽚⼀致性】 当任务被分⽚后,保证同⼀分⽚在分布式环境中仅⼀个执⾏实例。
3.3 开始使用 Elastic-Job
Elastic-Job依赖于Zookeeper进⾏分布式协调,所以需要安装Zookeeper软件
3.3.1 安装Zookeeper
-
先从官方文件下载一个镜像文mirrors.tuna.tsinghua.edu.cn/apache/zook…
-
对压缩包进行解压 tar -zxvf zookeeper-3.4.14.tar.gz
-
进入conf目录 cp zoo_sample.cfg zoo.cfg
-
进入bin 目录,启动zk服务器
./zkServer.sh start --启动
./zkServer.sh stop --关闭
./zkServer.sh status --关闭
启动服务
[root@localhost bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看状态
[root@localhost bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: standalone
3.3.2 zookeeper可视化工具
网络下载地址添加链接描述
解压之后进入到build目录
使用java -jar 启动可视化工具
java -jar .\zookeeper-dev-ZooInspector.jar
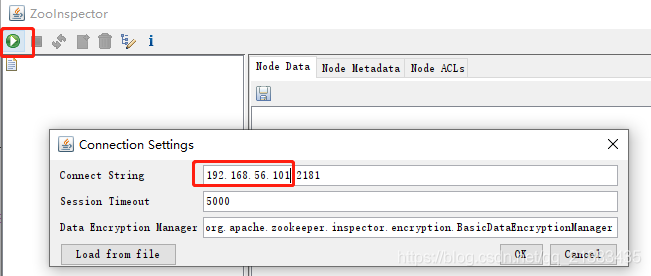
输入ip和端口号,端口号默认为2181
3.4 数据库建表语句
这里打算做一个同步业务,把resume中的用户 归档到 resume_bak中
-- ----------------------------
-- Table structure for resume
-- ----------------------------
DROP TABLE IF EXISTS `resume`;
CREATE TABLE `resume` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`sex` varchar(255) DEFAULT NULL,
`phone` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`education` varchar(255) DEFAULT NULL,
`state` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for resume_bak
-- ----------------------------
DROP TABLE IF EXISTS `resume_bak`;
CREATE TABLE `resume_bak` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`sex` varchar(255) DEFAULT NULL,
`phone` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`education` varchar(255) DEFAULT NULL,
`state` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS = 1;
3.5 主体代码
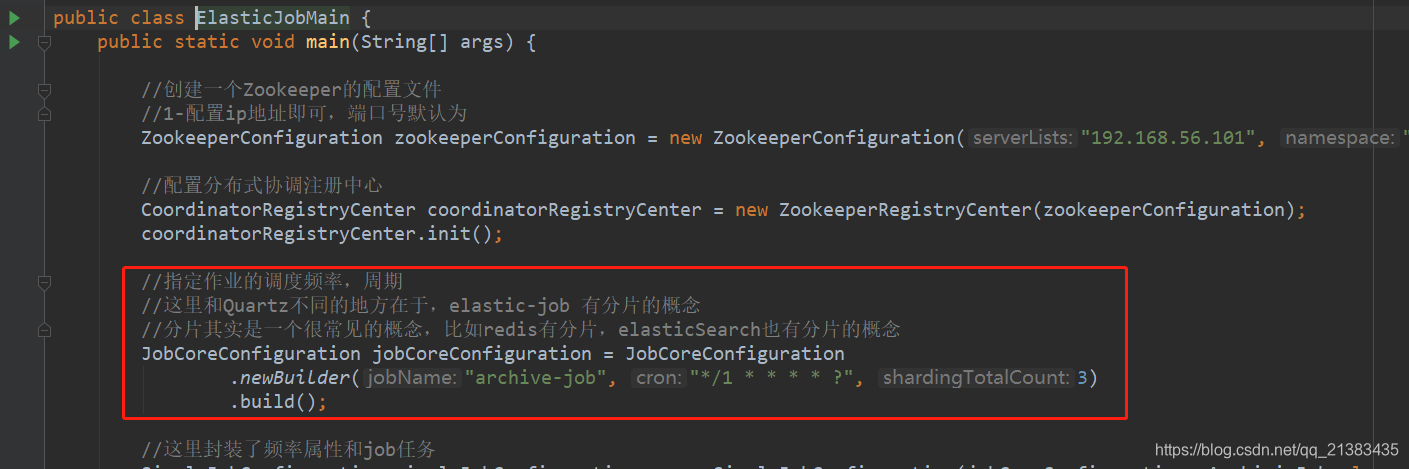
当前的主体代码主要功能是:创建配置,协调配置中心,调度计划,分片等,这里我们仅仅配置了一个分片
public class ElasticJobMain {
public static void main(String[] args) {
//1、创建一个Zookeeper的配置文件
//配置ip地址即可,端口号默认为
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration("192.168.56.101", "myjob-name");
//2、配置分布式协调注册中心
CoordinatorRegistryCenter coordinatorRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
coordinatorRegistryCenter.init();
//3、指定作业的调度频率,周期
//这里和Quartz不同的地方在于,elastic-job 有分片的概念
//分片其实是一个很常见的概念,比如redis有分片,elasticSearch也有分片的概念
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("archive-job", "*/1 * * * * ?", 1)
.build();
//4、这里封装了频率属性和job任务
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, ArchivieJob.class.getName());
//5、再次把simple配置 封装成 LiteJob配置
LiteJobConfiguration jobConfiguration = LiteJobConfiguration
.newBuilder(simpleJobConfiguration)
.overwrite(true)
.build();
/**
* 这里可以看到,同样是Configuration,在设计的时候,不是一股脑的把所有的信息放一起
* 而是分解成不同的 configuration,有处理频率的配置,有赋值job任务的配置,有轻量级配置
* 然后他们之间使用组合的形式,进行一层一层的封装 每个类保持独立
*/
//6、创建任务调度器,
//需要 协同注册中心
//需要 轻量级的job配置
JobScheduler jobScheduler = new JobScheduler(coordinatorRegistryCenter, jobConfiguration);
jobScheduler.init();
}
}
配置具体任务
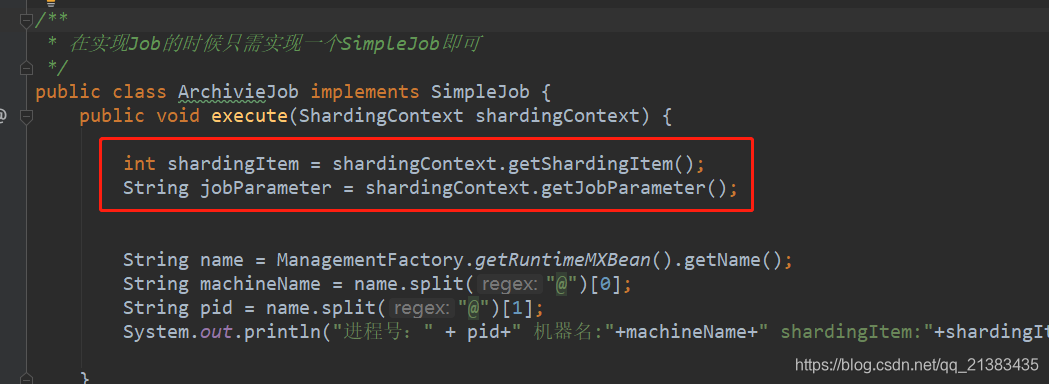
/**
* 在实现Job的时候只需实现一个SimpleJob即可
*/
public class ArchivieJob implements SimpleJob {
public void execute(ShardingContext shardingContext) {
int shardingItem = shardingContext.getShardingItem();
String jobParameter = shardingContext.getJobParameter();
String name = ManagementFactory.getRuntimeMXBean().getName();
String machineName = name.split("@")[0];
String pid = name.split("@")[1];
System.out.println("进程号:" + pid+" 机器名:"+machineName+" shardingItem:"+shardingItem +" jobParameter:"+jobParameter);
}
}
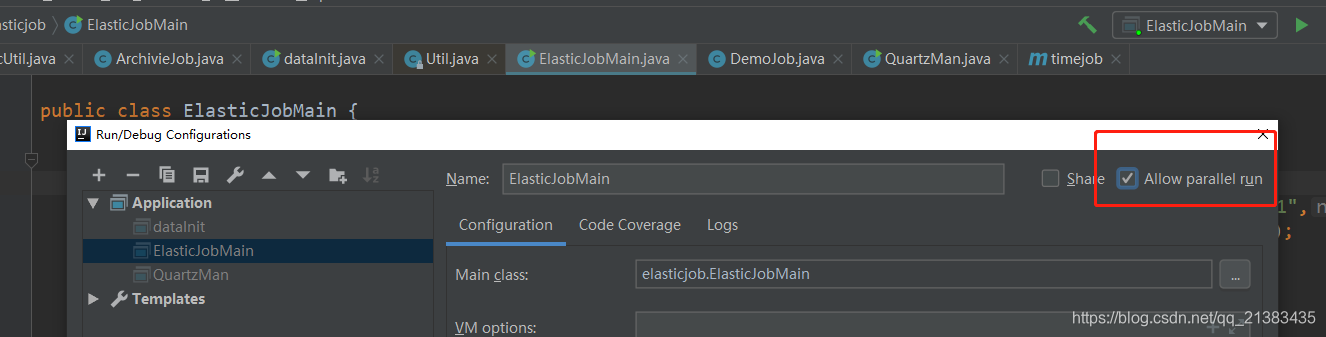
3.6 IDEA支持同时启动多个main运行实例
IDEA默认不支持同时启动多个main方法,这里需要配置一下,允许并行运行程序
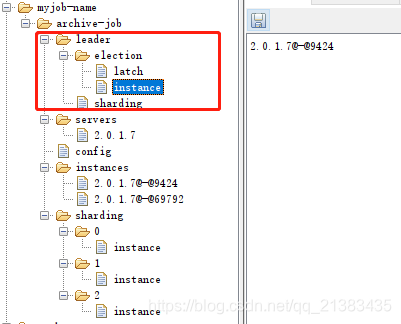
3.7 观看zookeeper中的节点值
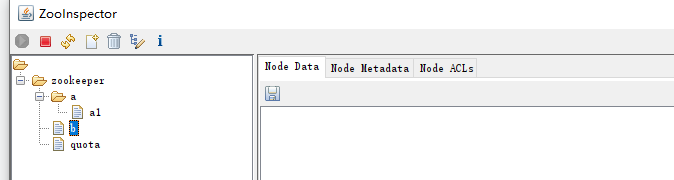
可以看到在可视化工具中有几个节点需要关注一下
instances 此节点说明当前当前只有一台机器连接了
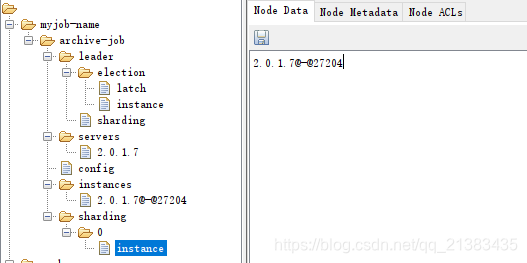
可以看到控制台打印输出的时候,也说明了当前端口号是27204
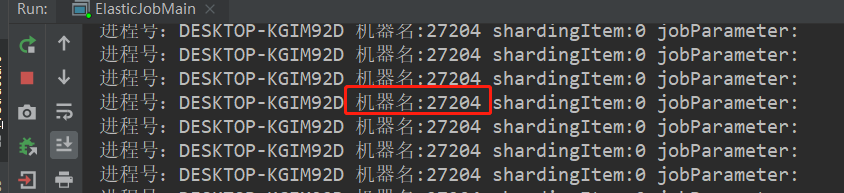
只要再次运行一个控制台程序,就会在instances中,有增加了一台机器。此时,我们把关注点放在sharding上,可以发现当前任务仅仅只有一个分片-0,而且这个实例就是 27204。
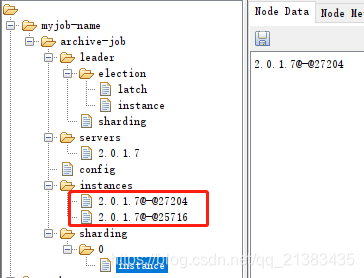
此时我们尝试增加一下分片,然后再看看分片的情况,此时设置为3,并且只跑一个实例
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("archive-job", "*/1 * * * * ?", 3)
.build();
可以看到,分片增加了三个,并且分片中每个实例都是9424
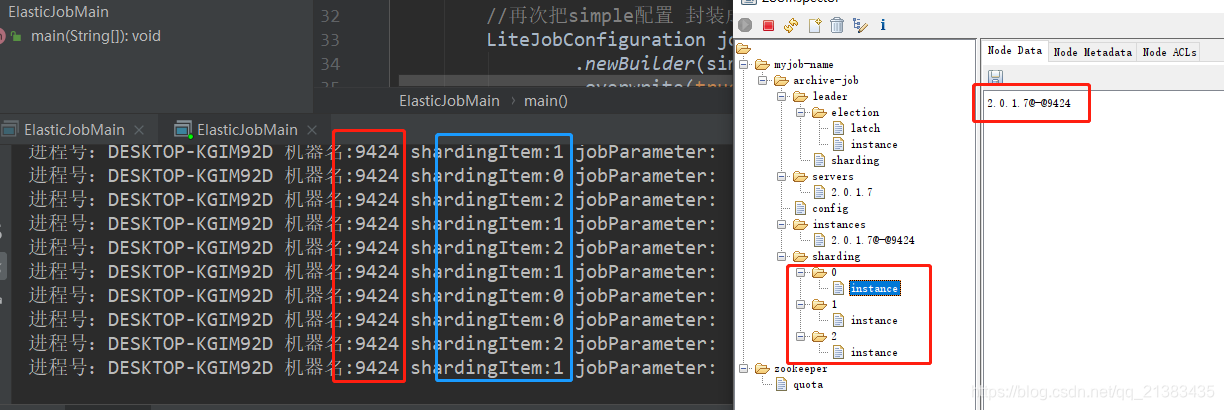
3.8 Leader节点选举机制
刚刚我们观察到的增加分片,启动多个实例,观察客户端工具,背后的实质就是他们的选举机制,原理如下:
- 每个Elastic-job作为Zookeeper的客户端,它来操作zookeeper的znode
- 多个实例同时去创建 /leader节点
- /leader节点只能创建一个,后创建的会失败,创建成功的实例会被选为leader节点,执⾏任务
4 轻量级去中心化
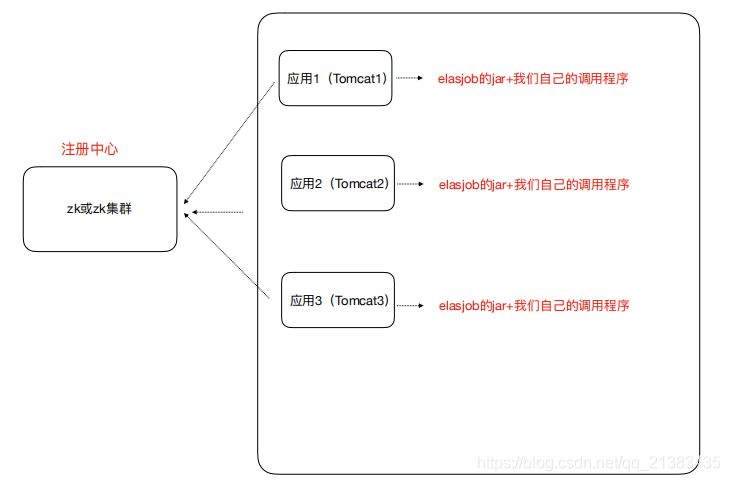
4.1 去中⼼化
- 执行节点对等,每套程序都是一样的
- 定时调度自触发,不需要调度中心进行调配
- 服务自发现(通过注册中心的服务发现)
- 主节点非固定
4.2 轻量级
- 所有的文件都打包在一个Jar文件中
- 仅仅需要依赖zookeeper服务
4.3 架构框图
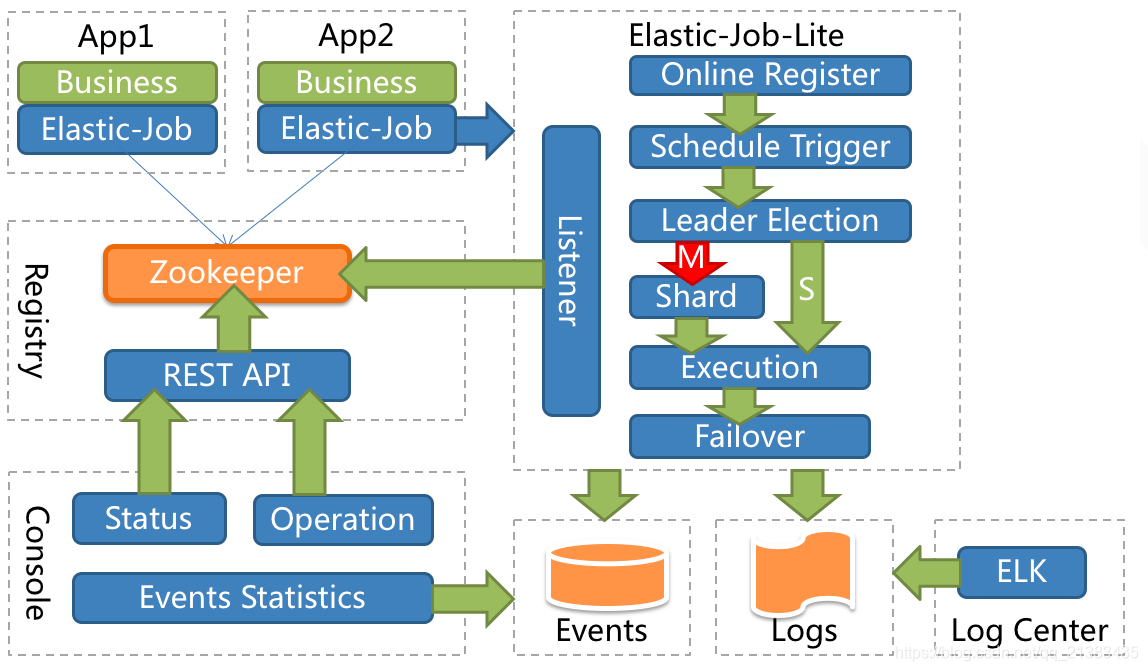
这个接口包含了主要的功能
/**
* 作业内部服务门面服务.
*
* @author zhangliang
*/
public interface JobFacade {
/**
* 读取作业配置.
*
* @param fromCache 是否从缓存中读取
* @return 作业配置
*/
JobRootConfiguration loadJobRootConfiguration(boolean fromCache);
/**
* 检查作业执行环境.
*
* @throws JobExecutionEnvironmentException 作业执行环境异常
*/
void checkJobExecutionEnvironment() throws JobExecutionEnvironmentException;
/**
* 如果需要失效转移, 则执行作业失效转移.
*/
void failoverIfNecessary();
/**
* 注册作业启动信息.
*
* @param shardingContexts 分片上下文
*/
void registerJobBegin(ShardingContexts shardingContexts);
/**
* 注册作业完成信息.
*
* @param shardingContexts 分片上下文
*/
void registerJobCompleted(ShardingContexts shardingContexts);
/**
* 获取当前作业服务器的分片上下文.
*
* @return 分片上下文
*/
ShardingContexts getShardingContexts();
/**
* 设置任务被错过执行的标记.
*
* @param shardingItems 需要设置错过执行的任务分片项
* @return 是否满足misfire条件
*/
boolean misfireIfRunning(Collection<Integer> shardingItems);
/**
* 清除任务被错过执行的标记.
*
* @param shardingItems 需要清除错过执行的任务分片项
*/
void clearMisfire(Collection<Integer> shardingItems);
/**
* 判断作业是否需要执行错过的任务.
*
* @param shardingItems 任务分片项集合
* @return 作业是否需要执行错过的任务
*/
boolean isExecuteMisfired(Collection<Integer> shardingItems);
/**
* 判断作业是否符合继续运行的条件.
*
* <p>如果作业停止或需要重分片或非流式处理则作业将不会继续运行.</p>
*
* @return 作业是否符合继续运行的条件
*/
boolean isEligibleForJobRunning();
/**判断是否需要重分片.
*
* @return 是否需要重分片
*/
boolean isNeedSharding();
/**
* 作业执行前的执行的方法.
*
* @param shardingContexts 分片上下文
*/
void beforeJobExecuted(ShardingContexts shardingContexts);
/**
* 作业执行后的执行的方法.
*
* @param shardingContexts 分片上下文
*/
void afterJobExecuted(ShardingContexts shardingContexts);
/**
* 发布执行事件.
*
* @param jobExecutionEvent 作业执行事件
*/
void postJobExecutionEvent(JobExecutionEvent jobExecutionEvent);
/**
* 发布作业状态追踪事件.
*
* @param taskId 作业Id
* @param state 作业执行状态
* @param message 作业执行消息
*/
void postJobStatusTraceEvent(String taskId, JobStatusTraceEvent.State state, String message);
}
Elastic job主要的功能有支持弹性扩容,通过Zookepper集中管理和监控job,支持失效转移等
4.4 任务分片
⼀个⼤的⾮常耗时的作业Job,⽐如:⼀次要处理⼀亿的数据,那这⼀亿的数据存储在数据库中,如果
⽤⼀个作业节点处理⼀亿数据要很久,在互联⽹领域是不太能接受的,互联⽹领域更希望机器的增加去
横向扩展处理能⼒。所以,ElasticJob可以把作业分为多个的task(每⼀个task就是⼀个任务分⽚),每
⼀个task交给具体的⼀个机器实例去处理(⼀个机器实例是可以处理多个task的),但是具体每个task
执⾏什么逻辑由我们⾃⼰来指定。
配置使用分片
获取分片的信息
分片策略
系统中,有一个作业分片策略类:JobShardingStrategy,并且有三个子类

public interface JobShardingStrategy {
/**
* 作业分片.
* @param jobInstances 所有参与分片的单元列表
* @param jobName 作业名称
* @param shardingTotalCount 分片总数
* @return 分片结果
*/
Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount);
}
AverageAllocationJobShardingStrategy 基于平均分配算法的分片策略.
* 如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
* 如:
* 1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
* 2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
* 3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
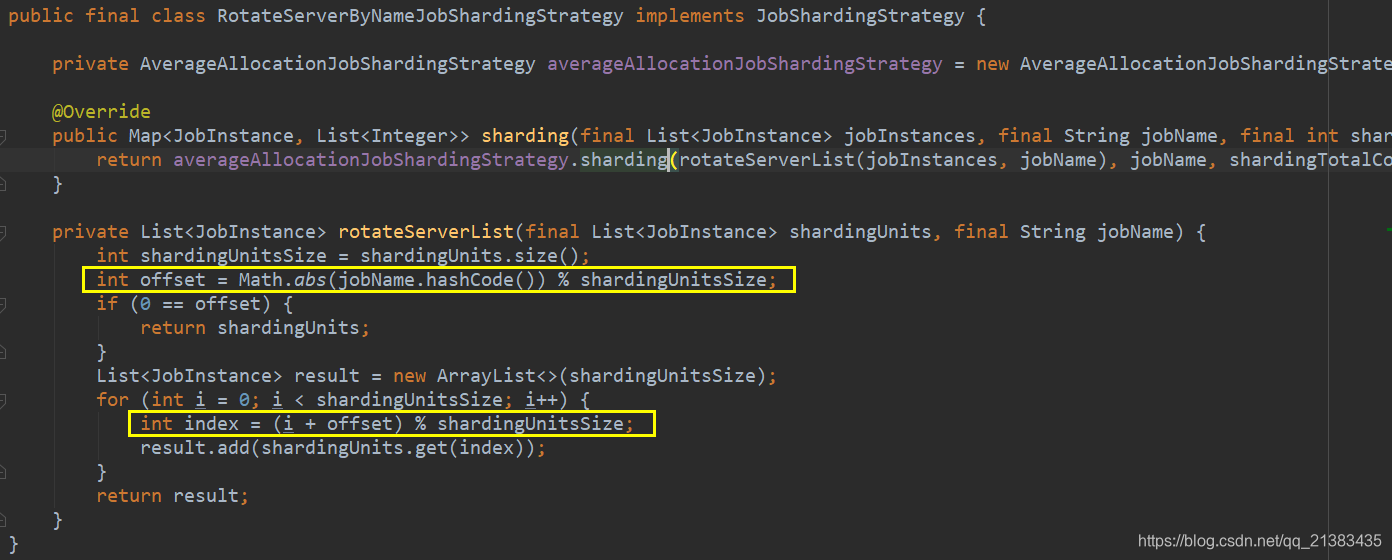
RotateServerByNameJobShardingStrategy 根据作业名的哈希值对服务器列表进行轮转的分片策略.
后续查看原文。。。