目录
Sharding-JDBC简介
ShardingSphere-JDBC 定位为轻量级的分布式数据库中间件解决方案,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

功能特性:
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
- 分布式治理
- 柔性事务
- 标准化事务接口
搭建mysql主从数据库
可参考之前的文章,《【mycat系列一】基于 Docker 搭建 MySQL 主从复制的详细教程》搭建一主两从的mysql,当然你也可以不使用docker,使用多台linux搭建,详细信息如下:
| 数据库类型 | 数据库 | docker容器中IP | 宿主机IP(对外IP) |
|---|---|---|---|
| 主:mysql-master | test | 172.17.0.2:3306 | 192.168.239.128:3307 |
| 从:mysql-slave1 | test | 172.17.0.3:3306 | 192.168.239.128:3308 |
| 从:mysql-slave2 | test | 172.17.0.4:3306 | 192.168.239.128:3309 |

配置好主从后,在主库创建一个新的数据库test,可使用Navicat等第三方客户端工具,或者命令行脚本都可以,SQL脚本如下:
USE `test`;
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT '' COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1307873057269878786 DEFAULT CHARSET=utf8 COMMENT='用户表';Navicat效果如下:

Springboot应用搭建
本文,将整合 SpringBoot + Mybatis-plus + Druid + Sharding-JDBC + MySQL,具体如下:

pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0.M1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.1.2</version>
</dependency>application.properties配置
# 服务端口
server.port=8080
# mysql-plus 配置
mybatis-plus.mapper-locations=classpath:/mapper/*.xml
mybatis-plus.type-aliases-package=com.stwen.shardingjdbc.entity
spring.main.allow-bean-definition-overriding=true
# sharding-jdbc 配置主从
sharding.jdbc.dataSource.names=master,slave1,slave2
# sharding-jdbc 主数据库
sharding.jdbc.dataSource.master.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.dataSource.master.driverClassName=com.mysql.jdbc.Driver
sharding.jdbc.dataSource.master.url=jdbc:mysql://192.168.239.128:3307/test?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
sharding.jdbc.dataSource.master.username=root
sharding.jdbc.dataSource.master.password=123456
sharding.jdbc.dataSource.master.maxPoolSize=20
# sharding-jdbc 从数据库一
sharding.jdbc.dataSource.slave1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.dataSource.slave1.driverClassName=com.mysql.jdbc.Driver
sharding.jdbc.dataSource.slave1.url=jdbc:mysql://192.168.239.128:3308/test?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.dataSource.slave1.username=root
sharding.jdbc.dataSource.slave1.password=123456
sharding.jdbc.dataSource.slave1.maxPoolSize=20
# sharding-jdbc 从数据库二
sharding.jdbc.dataSource.slave2.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.dataSource.slave2.driverClassName=com.mysql.jdbc.Driver
sharding.jdbc.dataSource.slave2.url=jdbc:mysql://192.168.239.128:3309/test?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.dataSource.slave2.username=root
sharding.jdbc.dataSource.slave2.password=123456
sharding.jdbc.dataSource.slave2.maxPoolSize=20
# 配置从库选择策略,提供轮询与随机,这里选择用轮询,random-随机
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
# 配置主从读写分离
sharding.jdbc.config.masterslave.name=master-slave
sharding.jdbc.config.masterslave.master-data-source-name=master
sharding.jdbc.config.masterslave.slave-data-source-names=slave1,slave2
# 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志
sharding.jdbc.props.sql.show=true
配置参数说明:
- mybatis-plus.mapper-locations : XXXmapper.xml 映射文件的路径
- mybatis-plus.type-aliases-package :实体类包名
- sharding.jdbc.dataSource.names:配置的是数据库的名称,就是上面搭建的多个数据源的名称
- sharding.jdbc.dataSource:配置多个数据源
其他的详细参数就不一一解释了,简单看一下就明白。
其中,spring.main.allow-bean-definition-overriding=true 是防止报如下错误而添加的:

在Springboot启动类,增加配置,mybatis的dao接口包扫描,如下
测试
编写测试类,增加两个接口:新增、查询列表
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private IUserService userService;
@PutMapping("/save")
public Object save() {
User user = new User();
user.setName("新增");
return userService.save(user);
}
@GetMapping("/list")
public Object list() {
// 强制路由主库
//HintManager.getInstance().setMasterRouteOnly();
return userService.list();
}
}启动应用,访问接口:localhost:8080/user/save ,可以查看数据,发现新增了一条数据

再访问列表查询接口:localhost:8080/user/list

开启日志(非必须)
(非必须)开启sql语句的日志,生产环境不建议开启,这里只是为了验证是否达到读写分离的效果。
查看日志目录,并开启sql语句的日志:
mysql> show variables like '%general_log%';
mysql> set global general_log=on;
注:
- 分别连接进入到上面配置的3个数据库中,执行上述命令,开启sql日志记录(无需重启,即可生效)。
- 当重启Mysql ,上述开启日志配置将失效。

3个数据库都设置之后,再次访问两个测试接口,再来查看sql日志:
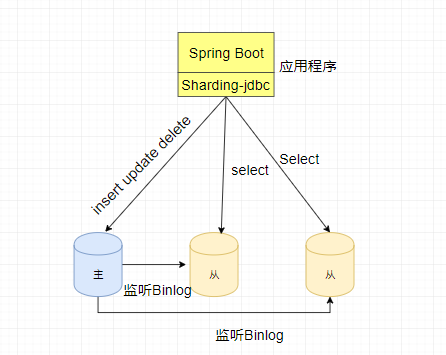
如下,在mysql-master 容器中,查看sql日志,可以看到插入的sql在主数据库执行

如下,查看mysql-slave2的sql日志,读取列表数据在从数据库执行,说明我们配置的读写分离是成功的。

主从同步延迟问题
读写分离架构中经常出现,那就是读延迟的问题如何解决?
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,也就是说数据还没复制到从节点,你就已经去从节点读取了,肯定读不到。mysql5.7 的主从复制是多线程了,意味着速度会变快,但是不一定能保证百分百马上读取到,这个问题我们可以有两种方式解决:
(1)业务层面妥协,是否操作完之后马上要进行读取
(2)对于操作完马上要读出来的,且业务上不能妥协的,我们可以对于这类的读取直接走主库,当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,可以让用户在使用的时候指定要不要走主库进行读取。在读取前使用下面的方式进行设置就可以了:
@GetMapping("/list")
public Object list() {
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
return userService.list();
}查看主库配置的sql日志,会看到打印如下,说明读操作强制走的主库:
SELECT id,name FROM t_user●阿里巴巴为什么能抗住90秒100亿?--服务端高并发分布式架构演进之路
●SpringCloud电商秒杀微服务-Redisson分布式锁方案
查看更多好文,进入公众号--撩我--往期精彩
一只 有深度 有灵魂 的公众号0.0