1.设一棵二叉树的先序序列:A B D F C E G H,中序序列: B F D A G E H C。
(1)画出这棵二叉树
(2)画出这棵二叉树的后序线索树
(3)将这棵二叉树转换成对应的树或森林

用按层次顺序遍历二叉树的方法,统计树中度为1的结点数目


求下列算法的时间复杂度
s=0;
for i=0; i<n; i++)
for(j=0; j<n; j++)
s+=B[i][j];
sum=s;
答案:O(n2)
解释:语句s+=B[i][j];的执行次数为n2。
在n个结点的顺序表中,算法的时间复杂度是O(1)的操作是( A )。
A.访问第i个结点(1≤i≤n)和求第i个结点的直接前驱(2≤i≤n)
B.在第i个结点后插入一个新结点(1≤i≤n)
C.删除第i个结点(1≤i≤n)
D.将n个结点从小到大排序
解析:选项A中的读取结点操作通过数组下标直接定位
在一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数( )。
A.8
B.63.5
C.63
D.7
知识点:线性表的插入算法分析 n=127, 移动次数 n/2=63.5
算法设计题:
设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B和C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)
void Decompose(LinkList &A,LinkList &B,LinkList &C )
{
B=A;
B->next= NULL; ∥B表初始化
C=new LNode;∥为C申请结点空间
C->next=NULL; ∥C初始化为空表
p=A->next; ∥p为工作指针
while(p!= NULL)
{
r=p->next; ∥暂存p的后继
if(p->data<0)
{
p->next=B->next; B->next=p; }
∥将小于0的结点链入B表,前插法
else {
p->next=C->next; C->next=p; }
∥将大于等于0的结点链入C表,前插法
p=r;∥p指向新的待处理结点
}}
若一个栈以向量V[1…n]存储,初始栈顶指针top设为n+1,则元素x进栈的正确操作是( )。
A.top++; V[top]=x;
B.V[top]=x; top++;
C.top–; V[top]=x;
D.V[top]=x; top–;
解析:初始栈顶指针top为n+1,说明元素从数组向量的高端地址进栈,元素x进栈时top指针先下移变为n( top–),之后将元素x存储在V[n]
假设以带头结点的循环链表表示队列,并且只设一个指针指向队尾元素结点(注意:不设头指针),试编写相应的置空队列,判断队列是否为空,入队和出队等算法



假装是分割线
设计一个算法,将链表中所有结点的链接方向“原地”逆转,即要求利用原表的存储空间,换句话说,要求算法的空间复杂度为O(1)。


设二叉树中有n2个度为2个结点,n1个度为1的结点,n0个度为0的结点,则有
这个超级重要
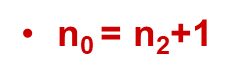
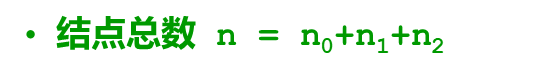
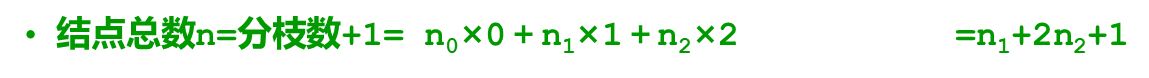
满二叉树:
结点总数 n=2k-1
完全二叉树
前k-1层是满的,第k层可以不满,但第k层结点集中在左侧
完全二叉树

非完全二叉树

将完全二叉树自上而下,自左向右地编号,
树根的编号为1。对于编号为i的结点X有:
若i=1,则X是根;若i>1, 则X的双亲的编号为i/2;
若X有左孩子,则X左孩子的编号为2i;
若X有右孩子,则X右孩子的编号为2i+1;
若i为奇数且i>1,则X的左兄弟为i-1;
若i为偶数且i<n,则X的右兄弟为i+1;


若一棵二叉树的前序(先序)遍历序列为a,e,b,d,c,后序遍历序列为b,c,d,e,a,则根结点的孩子结点是()
A.只有e
B.e,b
C.e,c
D.无法确定
解析:根据前序遍历可知根结点是a且e为a的孩子结点,当两个结点的前序序列为XY且后序序列为YX时,可知X是Y的祖先。b,c,d的祖先是e,所以根结点的孩子只有e
对二叉树的结点从1开始进行连续编号,要求每个结点的编号大于其左、右孩子的编号,同一结点的左右孩子中,其左孩子的编号小于其右孩子的编号,可采用()遍历实现编号
A.先序 B.中序 C.后序 D.从根开始层次遍历
一棵非空的二叉树的先序遍历序列与后序遍历序列正好相反,则该二叉树一定满足( )
A.所有的结点均无左孩子 B.所有的结点均无右孩子 C.==只有一个叶子结点 == D.是任意一棵二叉树。
例:某系统在通讯时,只出现C,A,S,T,B五种字符,其出现频率依次为2,4,2,3,3,试设计Huffman编码。


假装是分割线2
数组Q[n]用来表示一个循环队列,f为当前队列头元素的前一位置,r为队尾元素的位置,假定队列中元素的个数小于n,计算队列中元素个数的公式为:( D )
A r-f
B (n+f-r)%n
C n+r-f
D (n+r-f)%n
解析:循环队列:r-f差值为负数时,加上n,然后对n求余
设有一个递归算法如下:
int fact (int n)
{
if(n<=0) return 1;
else return n*fact(n-1);
}
则计算函数fact(n)需要调用该函数的次数为( A )
A. n+1 B. n-1 C. n D. n+2
在数学上有一个著名的“阿克曼(Ackermann)函数”,该函数定义如下:
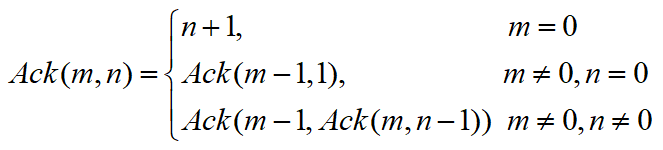
(1)写出Ack(m,n)的递归算法
int Ack(int m, int n)
//Ack函数的递归算法
{
If(m==0)
return n+1;
else if (m!=0 && n==0)
return Ack(m-1, 1);
Else
return Ack(m-1,Ack(m,m-1));
}
(2)写出计算Ack(m,n)的非递归算法
int Ack(int m, int n)
//Ack函数的递归算法
{
for(j=0;j<n;j++)
akm[0][j] = j+1;//得到Ack(0,n)的值
for(i=0;i<m;i++)
{
akm[i][0] = akm[i-1][1];
for(j=1;j<n;j++)
akm[i][j] = akm[i-1][akm[i][j-1]];
}
return akm[m][n];
}
从数据结构中,从逻辑上可以把数据结构分成( )和( )
A.动态结构和静态结构 B.紧凑结构和非紧凑结构
C.线性结构和非线性结构 D.内部结构和外部结构
知识点:数据的逻辑结构
顺序存储结构中数据元素之间的逻辑关系是由(存储位置)表示
链式存储结构中数据元素之间的逻辑关系是由(指针)表示
抽象数据类型的三个组成部分分别为:(数据对象), (数据关系) 和 (基本操作 )
求下列算法的时间复杂度
x=90; y=100;
while(y>0)
if(x>100)
{
x=x-10;y--;}
else x++;
答案:O(1)
知识点:算法的时间复杂度
求下列算法的时间复杂度
s=0;
for i=0; i<n; i++)
for(j=0; j<n; j++)
s+=B[i][j];
sum=s;
答案:O(n2)
解释:语句s+=B[i][j];的执行次数为n2。
某算法的语句执行频度为(3n+nlog2n+n2+8),其时间复杂度表示( )
A.O(n)B.O(nlog2n)C.O(n2) D.O(log2n)
解析:

对应一个头指针为head的带头结点的单链表,判断该表为空表的条件是
A.head= =NULL;
B.head->next= =NULL;
C.head->next= =head;
D.head!=NULL;
设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用( )最节省时间
A.单链表
B.单循环链表
C.带尾指针的单循环链表
D.带头结点的双循环链表
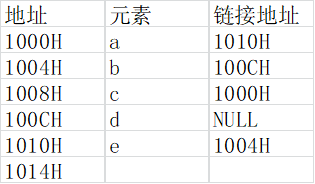
已知表头元素为c的单链表在内存中的存储状态如下图所示。现将f存放于1014H处并插入到单链表中,若f在逻辑上位于a和e之间,则a,e,f的“链接地址”依次是
A.1010H,1014H,1004H
B.1010H,1004H,1014H
C.1014H,1010H,1004H
D.1014H,1004H,1010H
设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B和C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)
void Decompose(LinkList &A,LinkList &B,LinkList &C )
{
B=A;
B->next= NULL; ∥B表初始化
C=new LNode;∥为C申请结点空间
C->next=NULL; ∥C初始化为空表
p=A->next; ∥p为工作指针
while(p!= NULL)
{
r=p->next; ∥暂存p的后继
if(p->data<0)
{
p->next=B->next; B->next=p; }
∥将小于0的结点链入B表,前插法
else {
p->next=C->next; C->next=p; }
∥将大于等于0的结点链入C表,前插法
p=r;∥p指向新的待处理结点
}}