简介: 学习计算引擎(MapReduce,Hive,Spark,Flink)等,wordcount案例都会是我们接触的要第一个Demo
下面就Spark学习的wordcount案例进行一个详解如下图:
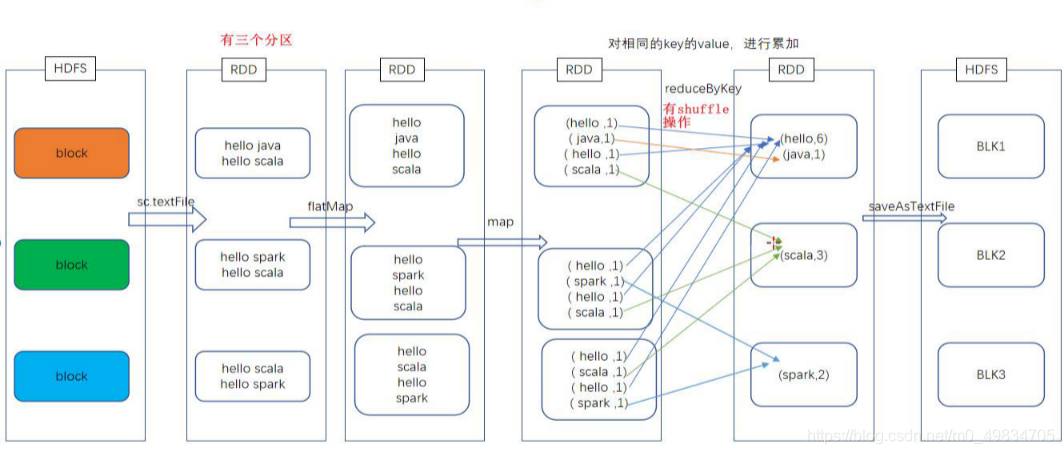
代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/11 0011 22:04
* @version 1.0 第一个Spark代码 基于Scala的wordcount案例 var 变量 val常量
*/
/**
* DESC: 当前任务的撰写流程写出来 这个是写代码的思维逻辑
*
* 1-首先创建SparkContext上下文对象,通过SparkContext对象获取计算资源(CPU + 内存)
* 2-使用SparkContext读取本地文件
* 3-使用FlatMap进行比扁平化转换
* 4-使用map算子进行转换
* 5-使用reduceByKey的算子进行聚合
* 6-使用collect转换为Array在使用foreach打印
* 7-(可选)可以完成数据结果的写入HDFS或者本地文件系统
*/
object WordCount01 {
def main(args: Array[String]): Unit = {
//1-首先创建SparkContext对象,通过SparkContext对象获取对应计算资源
//SparkConf必须制定的是AppName(WebUI中查看具体的名称)和Master
val conf: SparkConf = new SparkConf().setAppName("SparWordCount").setMaster("local[4]") //本地开启4个线程
val sc = new SparkContext(conf) //launching with ./bin/spark-submit
sc.setLogLevel("WARN") //设置日志级别
//2.使用SparkContext读取本地文件
val fileRDD: RDD[String] = sc.textFile("data/input/words.txt")
//3-使用FlatMap进行比扁平化转换 \\s+ 代表制表符 包括空格 换行 tab等
val flatMapRDD: RDD[(String)] = fileRDD.flatMap(_.split("\\s+"))
// 4-使用map算子进行转换 每一个单词与1组成一个键值对 例如: (hello,1)
val mapRDD: RDD[(String,Int)] = flatMapRDD.map((_, 1))
//5-使用reduceByKey的算子进行聚合
val reduceRDD: RDD[(String,Int)] = mapRDD.reduceByKey(_ + _)
//6-使用collect转换为Array在使用foreach打印
reduceRDD.collect().foreach(println)
//7-(可选)可以完成数据结果的写入HDFS或本地文件系统
Thread.sleep(100*1000) //我自己设置的休眠 方便4040端口看任务
sc.stop()
}