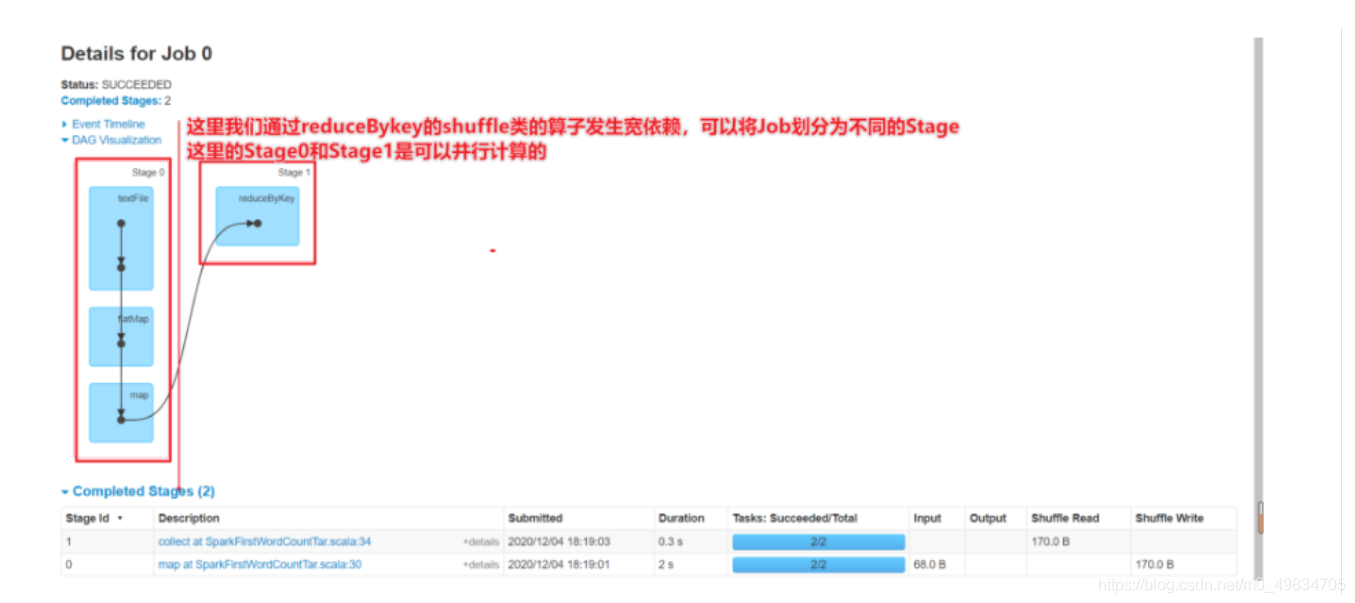
- 1-什么是依赖关系(血缘关系)
- 通过构建依赖关系可以实现RDD的容错
- 子RDD依赖于父RDD
- 2-为什么需要依赖关系
- 因为Spark是基于RDD的并行计算框架
- RDD不可变 可分区 可并行计算的集合
- 通过划分为宽依赖和窄依赖可以在窄依赖过程中实现RDD分区的并行计算
- 但是在宽依赖的部分需要从上一个RDD的不同分区拉取数据,在Shuffle阶段无法实现并行计算
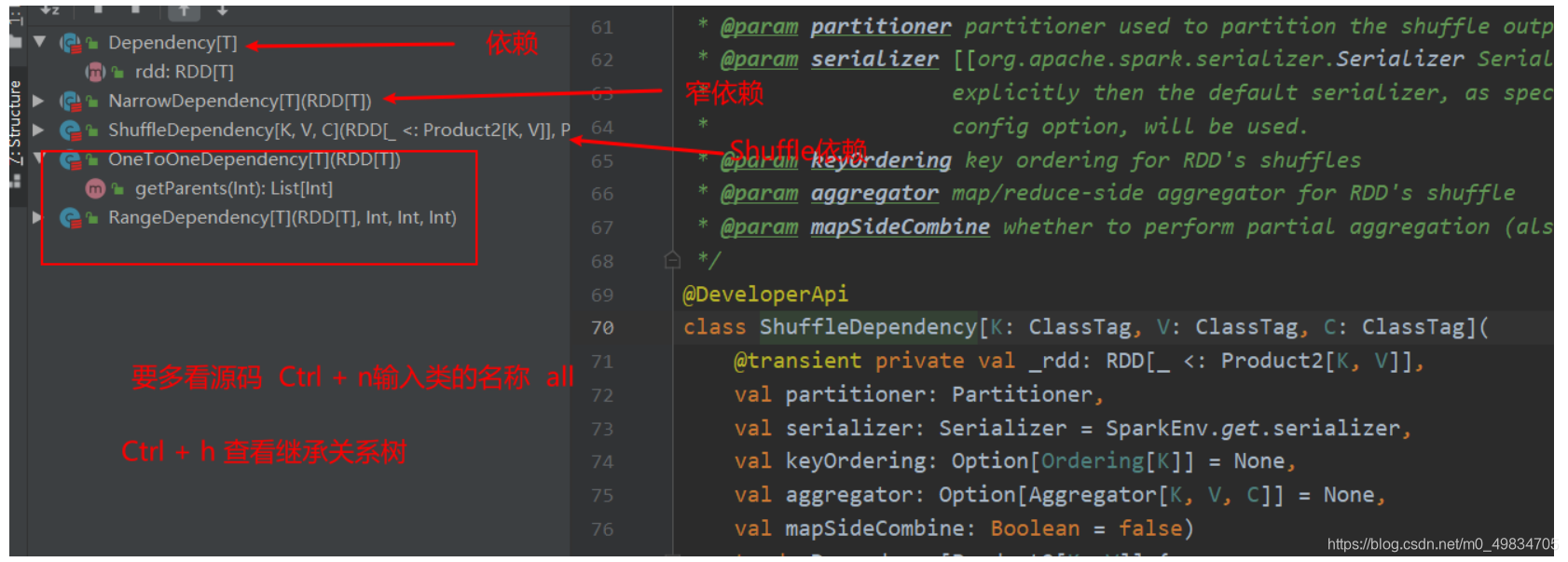
- 3-依赖关系有几种?
- 窄依赖:NarrowDependency
- 宽依赖:ShuffleDependency
- 4-如何判断一个依赖是窄依赖还是宽依赖?
- 通过一个父RDD跟一个子RDD对应,窄依赖
- 通过一个父RDD跟多个子RDD对应,宽依赖
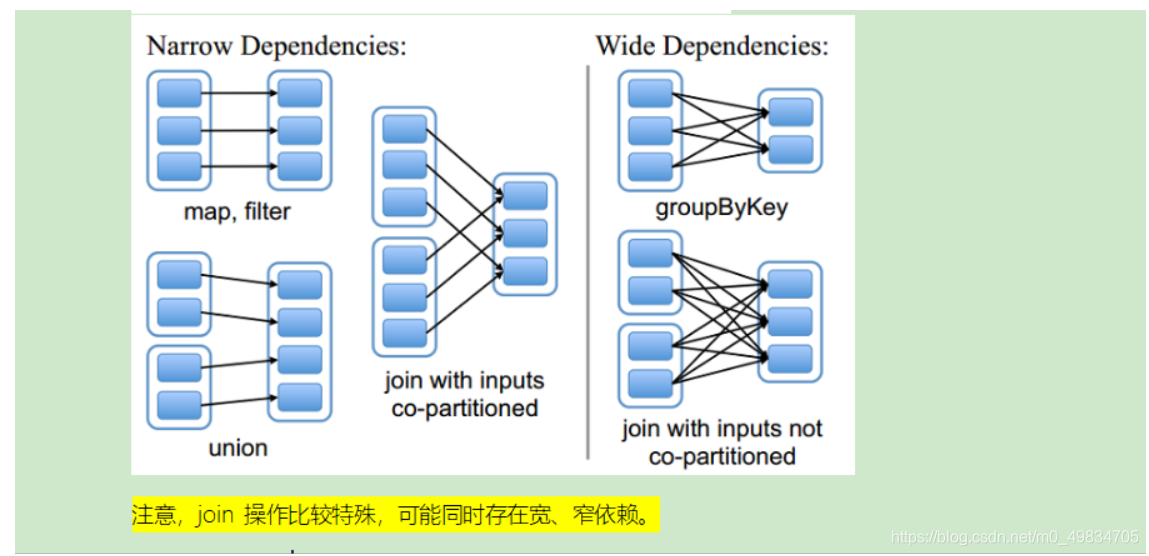
这里有一个面试题: 子RDD的一个分区依赖多个父RDD是宽依赖还是窄依赖?
1) 不能确定,也就是宽窄依赖的划分依据是父RDD的一个分区是否被子RDD的多个分区所依赖,是,就是宽依赖,或者从shuffle的角度去判断,有shuffle就是宽依赖,如Join
5-Spark设计依赖关系目的是什么?
- 为了能够Spark并行计算,是划分Stage的依据
- 为了构建血缘关系进行RDD的容错,一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可