Hadoop HA集群的搭建
序言
准备五台虚拟机
| hostname | IP |
|---|---|
| master1 | 192.168. 2.66 |
| master2 | 192.168.2.67 |
| slave1 | 192.168.2.68 |
| slave2 | 192.168.2.69 |
| slave3 | 192.168.2.70 |
说明一下:用的什么用户安装hadoop,那这个用户就是hadoop的超级用户,本人直接用的root用户,如果朋友们想用其他的用户也可以自行创建
1、JDK的安装
搭建Hadoop HA,那么我们就先从安装JDK开始,如果朋友们没有资源,文章后面会有资源链接
1.1用xftp将jdk上传到master1当中,并解压jdk
解压命令为:
tar -zxvf jdk-8u191-linux-x64.tar.gz
我这里安装的路径是/usr/Software/Java/jdk1.8.0_191
1.2编辑环境变量
vi /etc/profile
具体参照:
2、环境变量的配置
1.3检查jdk环境变量是否配置成功
在终端输入
java
或者
java -version
有结果则说明成功
2、环境变量的配置
#Hadoop
export HADOOP_HOME=/usr/Software/Hadoop/hadoop-2.7.3
#Java
export JAVA_HOME=/usr/Software/Java/jdk1.8.0_191
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
#Zookeeper
export ZOOKEEPER_HOME=/usr/Software/ZooKeeper/zookeeper-3.4.13
export PATH=${
JAVA_HOME}/bin:${
HADOOP_HOME}/bin:${
HADOOP_HOME}/sbin:${
ZOOKEEPER_HOME}/bin:$PATH
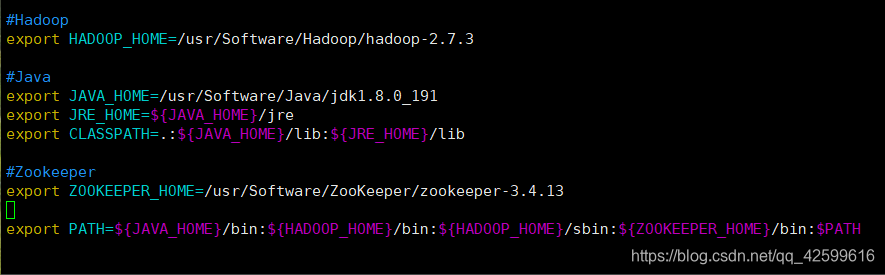
配置完环境变量后需初始化
source profile
3、映射主机名与IP地址
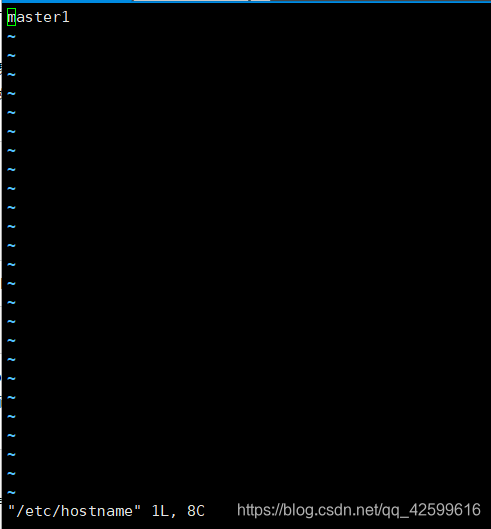
3.1修改主机名(其它四台虚拟机也是要修改为对应的hostname)
vi /etc/hostname
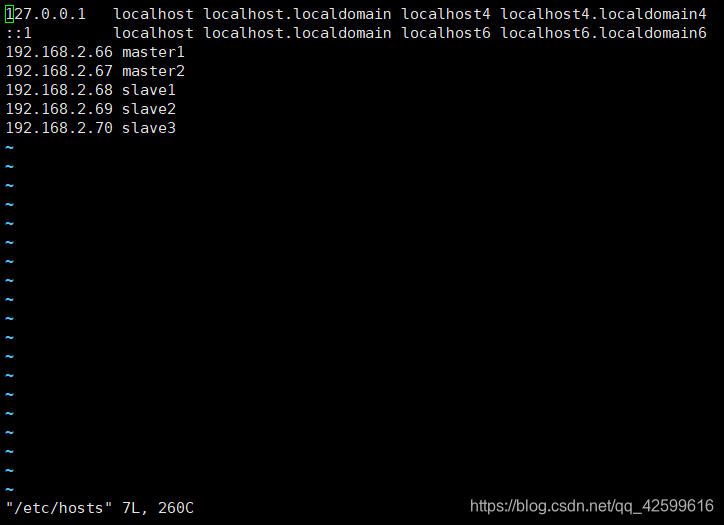
3.2修改hosts文件(每台虚拟机都要配置)
vi /etc/hosts
3.3ping主机名
ping主机名检测是否映射成功
ping master2
ping slave1
...
4、分发配置信息到各个虚拟机
将上面配置好的jdk文件的信息分发到各个虚拟机
for ip in {
1..3}; do scp -r /usr/Software root@slave${
ip}:/usr/ ; done
for ip in {
1..3}; do scp -r /etc/profile root@slave${
ip}:/etc/ ; done
......
5、配置SSH无秘钥连接
5.1生成秘钥
在虚拟机上,生成公钥、私钥(每一台虚拟机都要,为了实现各个虚拟机之间免密码登录)
像这种多个虚拟机都需要进行的操作,可以直接用XShell的一个功能来实现: 工具–>发送键输入到所有会话
ssh-keygen -t rsa -P ''
输入该命令需要让你填写保存的路径,一般默认为
/root/.ssh/id_rsa
在.ssh目录下会生成id_rsa(私钥) ,id_rsa.pub(公钥)
authorized_keys(存放远程免密码登录的公钥)
5.2将虚拟机的公钥信息导入master1的authorized_keys中
cat .ssh/id_rsa.pub >> .ssh/authorized_keys // 先将本机的公钥信息导入
for ip in {
1..3}; do cat root@slave${
ip}:/root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys ; done
cat root@master2:/root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
5.3将配置好的authorized_keys分发到各个虚拟机
for ip in {
1..3}; do scp /root/.ssh/authorized_keys root@slave${
ip}:/root/.ssh/ ; done
scp /root/.ssh/authorized_keys root@master2:/root/.ssh/
6、同步虚拟机的时间
每台虚拟机上都需要同步时间
任选一个服务器时间同步即可
ntpdate 0.asia.pool.ntp.org
ntpdate 1.asia.pool.ntp.org
ntpdate 2.asia.pool.ntp.org
ntpdate 3.asia.pool.ntp.org
7、安装zookeeper(安装在slave结点)
7.1用Xftp工具上传到slave1中
7.2解压 tar -zxvf zookeeper-3.4.13.tar.gz
我安装的路径为: /usr/Software/ZooKeeper/zookeeper-3.4.13
7.3修改文件
进入安装的zookeeper的conf目录下将 zoo_sample.cfg 修改为 zoo.cfg,执行命令:mv zoo_sample.cfg zoo.cfg
并且修改该文件,如下
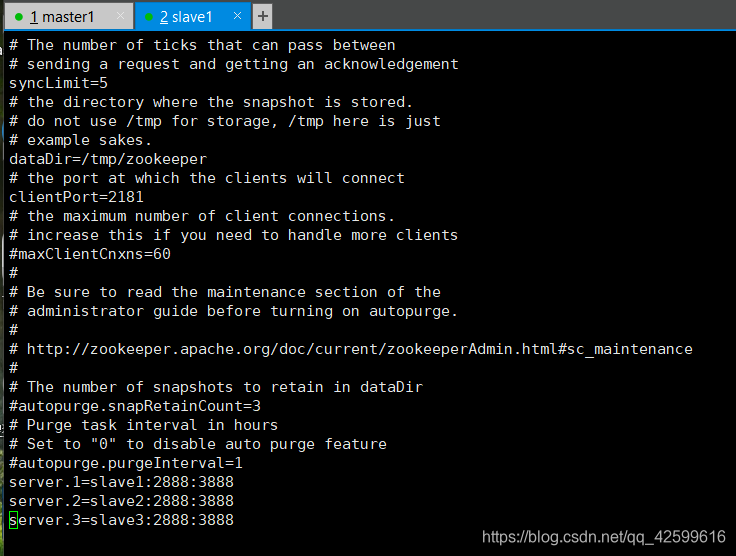
7.4将配置好的zookeeper分发到其它的slave节点
for ip in 2 3; do scp -r /usr/Software/ZooKeeper root@slave${
ip}:/usr/Software/ ; done
注意7.3步骤的dataDir的路径,需要在/tmp/下创建zookeeper目录,并在 zookeeper目录下创建文件myid,slave2,slave3也是一样,内容为分别为1 2 3(注意:文件里面别留空格或者换行)
7.5可以验证一下zookeeper是否安装成功
在slave虚拟机上启动zookeeper
zkServer.sh start //前提是已经在profile加上环境变量
jps
如果显示有QuorumPeerMain进程,则说明配置成功
8、安装Hadoop
前面说过了,这里再说一下,用什么用户安装hadoop,那么这个用户就是hadoop的超级用户,其他用户进行操作是有限制的
8.1解压安装包
先安装在master1上,后面可以通过scp命令拷贝到其他主机
我这装的是hadoop-2.7.3版本,3.0版本以上的有些默认端口号好像改变了
解压路径为:/usr/Software/Hadoop/hadoop-2.7.3
解压命令:
tar -zxvf hadoop-2.7.3.tar.gz
8.2修改配置文件
这步是最为关键的,需要修改的文件有5个
core-site.xml
hdfs-site.xml
mapred-site.xml
(如果没有这个文件,将该目录下名称为mapred-site.xml.template改名为mapred-site.xml)
yarn-site.xml
slaves
直接上代码
8.2.1修改core_site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/Software/Hadoop/hadoop-2.7.3/tmp</value>
</property>
<!--指定可以在任何IP访问-->
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<!--指定所有用户可以访问-->
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
8.2.2修改hdfs-site.xml
<configuration>
<property>
<name>dfs.block.size</name>
<value>67108864</value>
</property>
<!--指定hdfs的nameservice为master,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>master</value>
</property>
<!-- master下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.master</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.master.nn1</name>
<value>master1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.master.nn1</name>
<value>master1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.master.nn2</name>
<value>master2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.master.nn2</name>
<value>master2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/master</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.master</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免密码登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/Software/Hadoop/hadoop-2.7.3/journal</value>
</property>
<!--指定支持高可用自动切换机制-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定namenode名称空间的存储地址-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/Software/Hadoop/hadoop-2.7.3/name</value>
</property>
<!--指定datanode数据存储地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/Software/Hadoop/hadoop-2.7.3/data</value>
</property>
<!--指定数据冗余份数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定可以通过web访问hdfs目录-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--保证数据恢复 -->
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
8.2.3修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
</configuration>
8.2.4修改yarn-site.xml
<configuration>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--在HDFS上聚合的日志最长保留多少秒。3天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>259200</value>
</property>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--开启resource manager HA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置resource manager -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<!--在master1上配置rm1,在master2上需要改为rm2-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>master-yarn</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master1:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master1:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master1:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master1:23142</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>master2:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>master2:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>master2:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>master2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>master2:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/Software/Hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/Software/Hadoop/yarn/logs</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
</configuration>
有个地方一定要注意:将文件拷贝到master2后这个地方要改
<!--在master1上配置rm1,在master2上需要改为rm2-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
8.2.5修改slaves
提醒一下:hadoop3.0以后slaves更名为workers,
slaves是namenode节点识别datanode节点位置的一个文件。
在文件中加上这三个节点信息
slave1
slave2
slave3
8.2.6将hadoop文件分发到各个节点
for ip in 1 2 3; do scp -r /usr/Software/Hadoop root@slave${
ip}:/usr/Software/ ; done
scp -r /usr/Software/Hadoop root@master2:/usr/Software/
9、初始化集群
9.1启动zookeeper
用XShell的工具同时将slave(1,2,3)节点的zookeeper启动
zkServer.sh start
9.2初始化master1
hdfs zkfc -formatZK
9.3启动journalnode
在slave节点上同时启动
hadoop-daemon.sh start journalnode
9.4格式化master1的namenode
hadoop namenode -format
9.5在master1中启动namenode
hadoop-daemon.sh start namenode
9.6在master2中启动下面命令
// 把备namenode节点的目录格式化并把元数据从主namenode节点拷贝过来,并且这个命令不会把journalnode目录再格式化了
hdfs namenode -bootstrapStandby
// 启动备用的namenode
hadoop-daemon.sh start namenode
9.7开启zkfc
//两个namenode节点都要开启
// 为了观测namenode是否处于工作状态
hadoop-daemon.sh start zkfc
9.8启动datanode
hadoop-daemons.sh start datanode //在slave上启动
hadoop-daemons.sh start datanode //在master1中启动
hadoop-daemon.sh start datanode //也可以在slave上一个个启动
9.9启动yarn
start-yarn.sh // 两个namenode上都要启动
9.10查看状态
进入虚拟机中的网页,输入
http://master1:50070
http://master1:8188
有信息说明配置成功
10、启动集群
第二次启动不需要再进行初始化了,按照下面的步骤来即可
启动zookeeper
zkServer.sh start
启动journalnode
hadoop-daemon.sh start journalnode
启动主namenode
hadoop-daemon.sh start namenode
启动备用namenode
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
启动zkfc
hadoop-daemon.sh start zkfc
启动datanode
hadoop-daemons.sh start datanode
启动yarn
start-yarn.sh
再说明一个问题,如果能够启动datanode,但是jps中没有显示,那么可以尝试一下这个解决方案:
解决方法是删除datanode结点的current目录下的文件,重启datanode的时候会重新生成该文件。
11、hadoop资源
链接地址:hadoop资源,各种安装包
结尾
终于是写到结尾了,希望能够帮助到朋友们。如果文章有写的不对,欢迎大佬来指正,毕竟对知识的了解从修改bug中获得到的会更加深入。