数据表可以按照键(merge函数)来连接,也可以使用轴来合并(concat函数)
单键连接
语法格式如下为:pandas.merge(left,right,how="" on=key) on参数可以选择连接的键值。
can其中how参数可以选择连接方式与SQL语句的连接内涵相同,可选值有一下几个:
| 参数 | SQL等效 | 描述 |
|---|---|---|
left |
LEFT OUTER JOIN |
合并后显示左侧对象的所有行 |
right |
RIGHTOUTER JOIN |
合并后显示右侧对象的所有行 |
outer |
FULL OUTER JOIN |
合并后显示所有行 |
inner |
INNER OUTER JOIN |
合并后显示共有的行 |
import pandas as pd
df_price = pd.DataFrame(
{
'Date': pd.date_range('2019-1-1', periods=4),
'AdjClose': [24.42, 25.00, 25.25, 25.64]})
df_volume = pd.DataFrame(
{
'Date': pd.date_range('2019-1-2',periods=5),
'Volume' : [56081400, 99455500, 83028700, 100234000, 73829000]
})
数据展示

左连接、右连接
# 左连接
pd.merge(df_price,df_volume,how='left',on='Date')
# 右连接
pd.merge(df_price,df_volume,how='right',on='Date')

内连接、外连接
# 内连接
pd.merge(df_price,df_volume,how='inner',on='Date')
# 外连接
pd.merge(df_price,df_volume,how='outer',on='Date')

多键连接
在这里为df_price、df_volume新增一列来演示多键连接,具体数据结构如下:

# 使用键的联合
pd.merge(df_price,df_volume,how="outer",on=['Date','words'])
运行结果如下

这里为了显示效果使用outer进行合并,发现两个数据在没有的地方会用NaN填充,并且个数也是两个DataFrame的累加。
合并
Numpy 数组可相互连接,用 np.concat;同理,Series 也可相互连接,DataFrame 也可相互连接,用 pd.concat。使用concat内含axis参数,默认是axis=0(按照行进行合并)。里面的join参数可以使用上面的连接值,使用方法与上述一致。
合并Series
代码演示:
import pandas as pd
# 创建三个Series
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd','e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
数据结构如下所示

基础使用
# 默认进行行合并
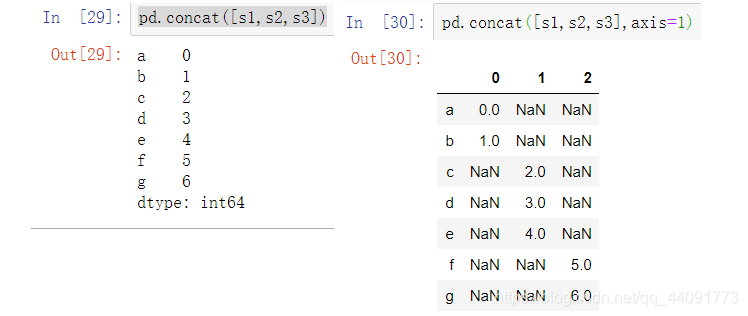
pd.concat([s1,s2,s3])
# 使用列合并
pd.concat([s1,s2,s3],axis=1)
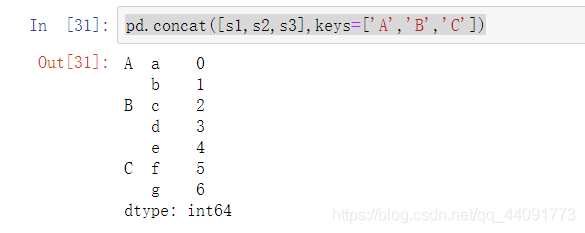
赋予三个Keys创造多层Series
pd.concat([s1,s2,s3],keys=['A','B','C'])
合并DataFrame
合并DataFrame与合并Seres基本相同
扫描二维码关注公众号,回复:
12205343 查看本文章

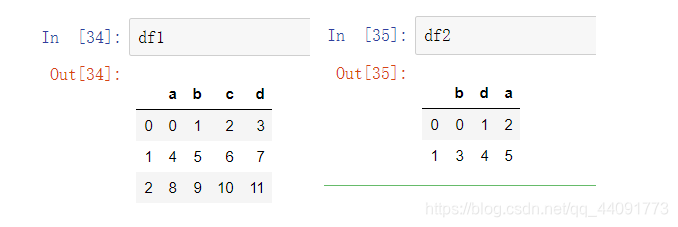
import pandas as pd
import numpy as np
df1 = pd.DataFrame( np.arange(12).reshape(3,4), columns=['a','b','c','d'])
df2 = pd.DataFrame( np.arange(6).reshape(2,3), columns=['b','d','a'])
数据结构如下所示
pd.concat([df1,df2],axis=0)
# 放弃原本的index
pd.concat([df1,df2],axis=0,ignore_index=True)
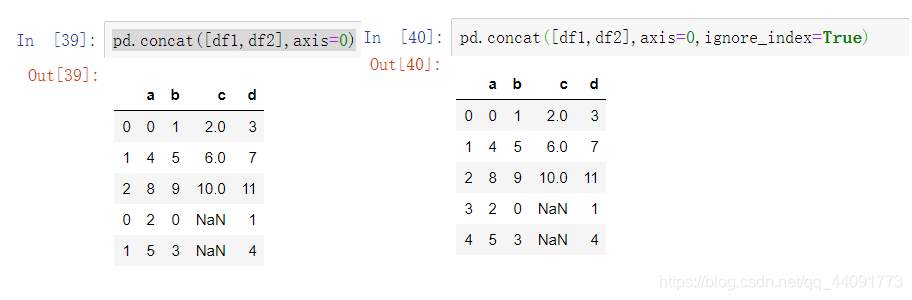
可以发现按照行进行合并的时候,当两个DataFrame的index相同的时候,会进行重复显示,如果inedx不重要的话,可以使用ignore_index从新创建索引。
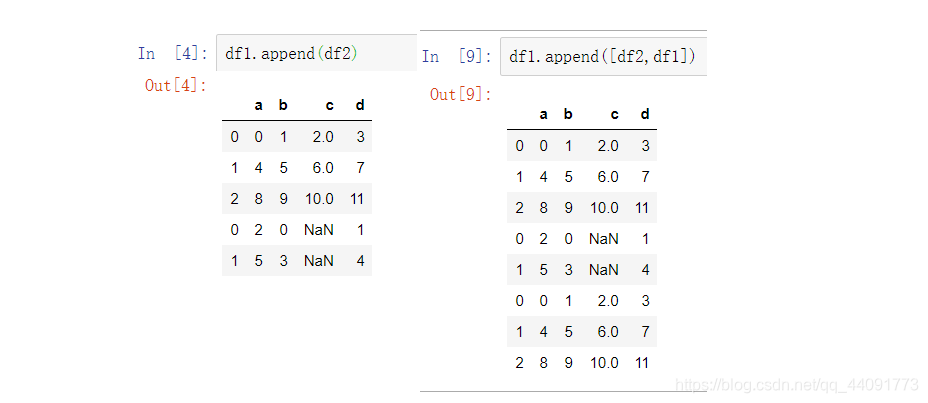
使用附加合并
合并的一个有用的快捷方式是在Series和DataFrame实例的append方法。这些方法实际上早于concat()方法。 它们沿axis=0连接,即索引。
df1.append(df2)
df1.append([df2,df1])