vlog-4
模型估计与选择
经验误差与过拟合

留出法
数据集三七分,七分训练集,三分测试集

交叉验证法
K折交叉验证法——简单来说就是把数据集分为k分,然后进行排列组合挑选,比如5折,就是取其中一份作为测试集,剩下部分作为训练集。能取5次。将测试结果平均值返回

自助法
又返回的采集m次数据,每个数据被采集的概率是1/m,当m趋向无穷大,有些样本始终采集不到的概率就是 1/e。

思考:既然有些部分数据集采取不到,那怎么将它们作为测试集呢?
性能度量
下图一个是连续情况,另一个是离散情况

错误率与精度
顾名思义,一个是离散,一个是连续情况

查准率查全率和F1
举例,数据集5条狗,5只猫。我们模型分类
狗类:[狗1 狗2 狗3 猫1 猫2]
猫类:[猫3 猫4 猫2 狗4 狗5]。
TP就是狗类中的真正是狗的=3,FP就是狗类中的假狗-猫1猫2=2
FN就是猫类中的真正是狗的=3,FP就是猫类中的假猫-狗4狗5=2

此处讲解
此处我们默认在没查之前全是真确的,随着查的增多,也就是查全率增大,开始产生错误,查准率也就随之下降。
B曲线包含C曲线,就是A的查准率基本上都大于B的查准率
A曲线更B曲线比较,就是用斜率为1看。A的查准率一直到查全率大约0.9都大于B,所以A模型更好,所以只要判断平衡点大于,那么就整体都大于


一个零界点,我们假定有判定是否为狗,概率为[o.1 o.5 0.7 1],
我们取大于等于0.1的全判定为狗,p1
大于等于0.5的全为狗,p2
以此类推

ROC与AUC

本人也没搞懂鸭
代价敏感错误率与代价曲线

函数f(x)!=y枚举数据集中所有数据,判断是否是真正例,如果是cost01=1,如果不是cost01=0。以此统计出所有错误的/样本总数=错误率

假设检验
挑选出所有反的就等于选出所有正的
我们模型错误率是 ϵ \epsilon ϵ,数据集反例率是 ϵ ^ \widehat{\epsilon} ϵ 。那么反例总数有 ϵ ^ ∗ m \widehat{\epsilon}*m ϵ ∗m。不难用二项分布得出
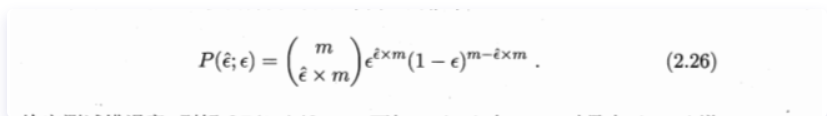
数据是离散的,就是将条形图加起来求最小错误率

偏差与方差

个人理解噪声就是离群点,就是数据[1.1 1 0.9 10000],显然 10000是错误的数据,然后我们拟合数据时候采用了 10000,加大泛化误差

推导公式如下
