OpenAI最新成果:AI弥合语言和图像鸿沟的一次突破
本文作者:林檎

在《逻辑与哲学论》(Tractatus Logico-Philosophicus) 一书中,伟大的哲学家维特根斯坦提出了这样的一种理论 ——Picture Theory of Meaning。
这个理论指出,如果可以在现实世界中对语言陈述进行定义或图示,那么这些语言陈述才是有意义的。即,有实在意思的句子,必须能反映成图像。而可用语言表达的事物和只能用非语言方式表达的事物之间,将存在着不可逾越的鸿沟。
维特根斯坦说,人走不出图画,因为人的语言就相当于图画。
OpenAI 最近发布的一项最新成果 DALL-E,是对维特根斯坦这个理论的一个很好演示。
DALL-E 都生成了什么?
GPT-3 表明,大型神经网络可以执行各种文本生成任务。图像 GPT 表明,同样类型的神经网络也可以用来生成高保真度的图像。
基于这两个发现,OpenAI 开发出了 DALL-E,直观展示了如何通过语言来操纵视觉概念。
DALL-E 名字来自西班牙超现实主义画家萨尔瓦多・达利(Salvador Dali)和皮克斯动画的 WALL・E,DALL-E 可以视为是 OpenAI 去年推出的语言模型 GPT-3 的图像版,它拥有 120 亿参数,经过训练后可以重新生成图像,而且是以与文本或图像提示一致的方式生成任何现有图像。OpenAI 自己的官方博客展示了非常多有趣的案例。
下面的示例,显示的是输入 “舒适的企鹅” 的结果。舒适,其实是一个有点抽象的概念,DALL-E 如何 “理解” 这个提示?答案出现了不少毛绒企鹅玩具。

不过,做好心理准备,一些不合常理的搭配,可能会有突破你舒适度的结果。
比如下面这个提示,由 “由豪猪制成的、具有豪猪纹理的立方体”,便产生某些观感比较令人不安的结果。这里突出的是结果的多样性。
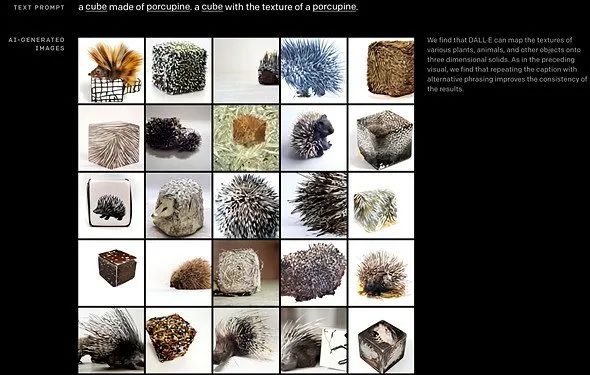
“我们发现 DALL-E 具有多种功能,包括创建动物和对象的拟人化版本,以合理的方式组合无关概念,渲染文本并将变换应用于现有图像。” OpenAI 在博客中如此写道。
OpenAI 介绍道,与 GPT-3 一样,DALL-E 是一个 transformer 语言模型,它同时接收文本和图像作为一个单一数据流,其中包含 256 个文本、1024 个图像共 1280 个 tokens。DALL-E 对 text tokens 使用标准的因果掩码,对行、列或卷积注意力模式的 image tokens 使用稀疏注意力,具体取决于每一层的情况。
在训练过程中,图像被预处理为 256x256 分辨率。类似于 VQVAE,通过使用离散 VAE,每个图像都被压缩到 32x32 网格的离散码,而之后使用连续松弛进行预训练,避免了对显式代码本、EMA 损失或死代码复活(dead code revival)等技巧的需求,并且可以扩展。
有关 DALL-E 的体系结构以及 OpenAI 如何对该程序进行训练的更多详细信息,仍然等待未来发表的具体论文。
DALL-E 的几大能力
多次将文本转换成图像的实验之后,OpenAI 总结出 DALL-E 所具有的的多项能力:
1、控制属性:OpenAI 测试了 DALL-E 修改目标物体的能力,包括修改相应的属性以及出现的次数。
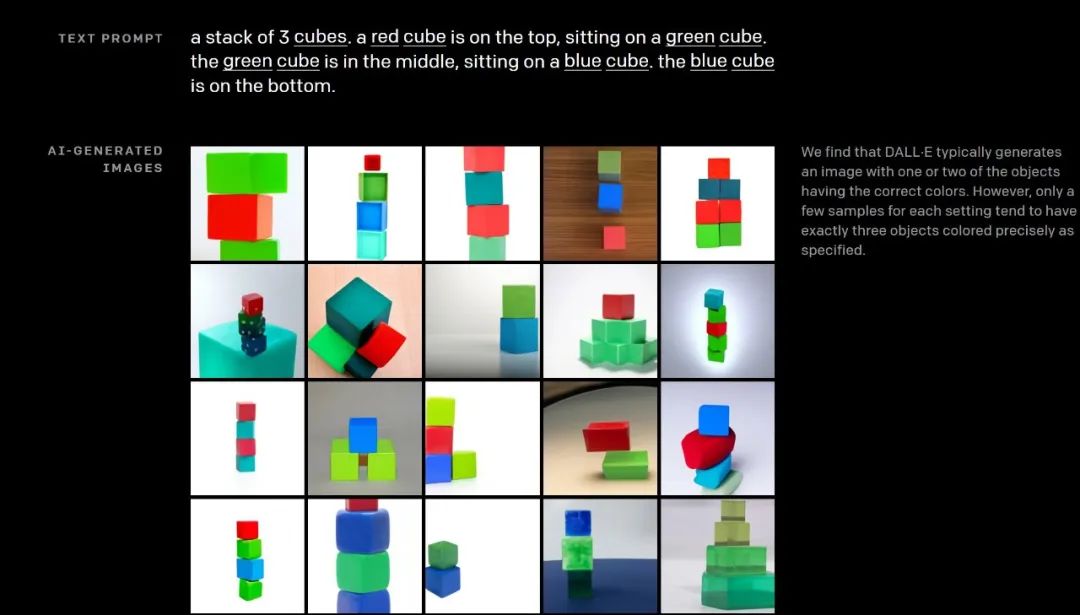
2、绘制多个目标:同时控制多个目标物体、彼此的属性和空间关系。例如,一堆三维立方体:红色的立方体在绿色立方体的顶部。绿色立方体在中间。蓝色立方体在底部。
3、可视化透视与三维:控制场景的视点和渲染场景的 3D 样式。
4、可视化内部和外部结构:运用横截面视角绘制内部结构和用宏观图像绘制外部结构。例如,核桃的横截面。

5、推断上下文细节:例如,日出时坐在田野上的水豚,根据水豚的方位,可能需要画一个阴影,但该细节未明确提及。

6、组合不相关的概念:结合完全不同的 idea,合成不存在的物体。例如,鳄梨型扶手椅。

7、动物插图:主要体现艺术插画能力。例如:一个专业、高质量的恋爱波霸珍珠奶茶表情符号

8、零样本视觉推理:仅根据提示来执行多种任务,而无需任何额外训练。
9、掌握地理知识:结合地理知识(似乎体现了一定的固有印象)进行生成。例如,中国美食的图片。

10、掌握时间知识:检验其随时间变化的概念的知识。例如,20 年代起发明的电话的照片。

事实上,DALL-E 本身并不是什么全新的尝试,但是从 OpenAI 给出的演示来看,它运行起来效果相当不错,大部分情况下都能比较好地处理各种输入,在给定提示下产生合理的结果。因而引发了大范围的关注。
尤其是将不相关的概念(其中有些事物根本不可能在现实世界中存在)相组合的这项能力,充满了维特根斯坦 Picture Theory of Meaning 的意味。
例如下列这个提示,“竖琴状的蜗牛”。相信很多人看到这个描述的时候,第一反应根本想象不出这会是怎样的一个存在。但 DALL-E 给出了它的想象。

DALL-E 展现出的这些能力固然有趣,那么,它会有怎样的商业价值吗?
已经有大量网友表示,希望能够购买到范例中演示的牛油果椅子。再或许,DALL-E 生成的图片,会截断类似 “视觉 XX” 这样的图片网站的财路(just kidding)?在博客中,OpenAI 团队展现的两个应用案例,分别是服装设计、室内设计。虽然并未明确这是他们所构想的商业用途,但看起来并不遥远。毕竟,2021 年,维特根斯坦近一个世纪前的想法,已经 “活生生” 在我们面前上演。
Reference:
https://openai.com/blog/dall-e/
公众号:数据实战派
转载请后台联系小编~