mysql 安装
1 mysql安装包 ,强烈不建议安装 mysql8 版本 ,mysql没有6和7版本,上个版本是 mysql v5.7
2 解压到c盘 找到路径
3 配置mysql的bin的目录到系统变量path
4 修改配置文件defautl,ini
basedir = C:\Program Files\mysql-5.7.14\bin
datadir = C:\Program Files\mysql-5.7.14\bin\data
5 找到mysql安装目录,将其配置文件my.default.ini改名为my.ini,并且将my.ini移至bin目录下
6 cmd命令进入bin目录
mysqld -install // 注册mysql 服务
mysqld -initialize // 启动,建立data目录
net start mysql // 启动mysql服务
7.在安装mysql5.7版本时,经常会遇到mysql -u root -p直接回车登陆不上的情况,原因在于5.7版本在安装时自动给了一个随机密码,mysql/data*.err,找到密码,登录后,修改
set password for root@localhost = password('123');
8 启动mysq v8 cmd输入services.msc 找到mysql80 然后启动
mac mysql 登录
默认安装完之后,是无法登录的,执行以下步骤就可。
cd /usr/local/mysql/bin/
sudo ./mysqld_safe --skip-grant-tables
// 然后新开一个ternimal
cd /usr/local/mysql/bin/
./mysql
flush privileges;
set password for 'root@localhost'= password('123456');
数据库连接池(connection pool)
1. 用数据库连接池技术,解决了资源的频繁分配﹑释放所造成的问题
2. 数据库连接池就是为数据库连接建立一个“缓冲池”,预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接
事务
数据库事务是构成单一逻辑工作单元的操作集合,事务使系统能够更方便的进行故障恢复以及并发控制,从而保证数据库状态的一致性
BEGIN TRANSACTION //事务开始
SQL1 ~~~
SQL2 ~~~
COMMIT/ROLLBACK //事务提交或回滚
1.数据库事务可以包含一个或多个数据库操作,但这些操作构成一个逻辑上的整体
2.构成逻辑整体的这些数据库操作,要么全部执行成功,要么全部不执行,数据库总能保持一致性状态
3.数据库出现故障以及并发事务存在的情况下依然成立
事务的特性
1.原子性(Atomicity):事务中的所有操作作为一个整体像原子一样不可分割,要么全部成功,要么全部失败。
一致性(Consistency):事务的执行结果必须使数据库从一个一致性状态到另一个一致性状态。一致性状态是指:1.系统的状态满足数据的完整性约束(主码,参照完整性,check约束等) 2.系统的状态反应数据库本应描述的现实世界的真实状态,比如转账前后两个账户的金额总和应该保持不变。
3.隔离性(Isolation):并发执行的事务不会相互影响,其对数据库的影响和它们串行执行时一样。比如多个用户同时往一个账户转账,最后账户的结果应该和他们按先后次序转账的结果一样。
4.持久性(Durability):事务一旦提交,其对数据库的更新就是持久的。任何事务或系统故障都不会导致数据丢
数据库系统是通过并发控制技术和日志恢复技术来避免对数据一致性的破坏(事务的并发执行,事务故障或系统故障)
事务的分类
显示事务:用BEGIN TRANSACTION明确指定事务的开始,这是最常用的事务类型
隐性事务:通过设置SET IMPLICIT_TRANSACTIONS ON 语句,将隐性事务模式设置为打开,下一个语句自动启动一个新事务。当该事务完成时,再下一个 T-SQL 语句又将启动一个新事务
自动提交事务:这是 SQL Server 的默认模式,它将每条单独的 T-SQL 语句视为一个事务,如果成功执行,则自动提交;如果错误,则自动回滚
事务sql代码
BEGIN TRANSACTION
/*--定义变量,用于累计事务执行过程中的错误--*/
DECLARE @errorSum INT
SET @errorSum=0 --初始化为0,即无错误
/*--转账:张三的账户少1000元,李四的账户多1000元*/
UPDATE bank SET currentMoney=currentMoney-1000
WHERE customerName='张三'
SET @errorSum=@errorSum+@@error
UPDATE bank SET currentMoney=currentMoney+1000
WHERE customerName='李四'
SET @errorSum=@errorSum+@@error --累计是否有错误
IF @errorSum<>0 --如果有错误
BEGIN
print '交易失败,回滚事务'
ROLLBACK TRANSACTION
END
ELSE
BEGIN
print '交易成功,提交事务,写入硬盘,永久的保存'
COMMIT TRANSACTION
END
GO
print '查看转账事务后的余额'
SELECT * FROM bank
索引
索引优化应该是对查询性能优化最有效的手段,因为索引大大减少了服务器需要扫描的数据量
mysql只能高效地使用索引的最左前缀列
mysql中索引是在存储引擎层而不是服务器层实现的
索引可以帮助服务器避免排序和临时表
索引可以将随机I/O变成顺序I/O
视图
视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上,使用视图的好处:
1.起到权限控制作用,只给可以看的数据
2.提升性能,防止多表join查询
3.灵活,表和视图的映射,更加灵活
// 查询表会显示视图
SHOW tables
// 创建视图
create view view1 as select * from people;
// 删除视图
DROP VIEW IF EXISTS v_students_info;
存储过程
存储过程是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它,特点有:
1.执行速度更快
2.允许模块化程序设计
3.提高系统安全性
4.减少网络流通量
优点有:
1.将重复性很高的一些操作,封装到一个存储过程中,简化了对这些SQL的调用
2.批量处理:SQL+循环,减少流量,也就是跑批
3.统一接口,确保数据的安全
MySQL 5.0 版本开始支持存储过程,相对于oracle数据库来说,MySQL的存储过程相对功能较弱,使用较少
java连接mysql
1.在maven中加入包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>
2.代码
ublic class MysqlTest {
// MySQL 8.0 以下版本 - JDBC 驱动名及数据库 URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://localhost:3306/hua";
static final String USER = "root";
static final String PASS = "123";
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Connection connect = null;
Statement stmt = null;
Class.forName(JDBC_DRIVER);
System.out.println("连接数据库~~~");
connect = DriverManager.getConnection(DB_URL,USER,PASS);
// 执行查询
System.out.println(" 实例化Statement对象...");
stmt = connect.createStatement();
String sql;
sql = "SELECT id, name FROM people";
ResultSet rs = stmt.executeQuery(sql);
// 展开结果集数据库
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
// 输出数据
System.out.println("id=" + id + "&name=" + name);
}
// 完成后关闭
rs.close();
stmt.close();
connect.close();
}
}
查看端口号
mysql -u root -p
SHOW global variables like 'port';
数据类型
1 整数 在 MySQL 中支持的 5 个主要整数类型是 TINYINT,SMALLINT,MEDIUMINT,INT 和 BIGINT,可以加unsigned,最大值翻倍
int(3) // 1999显示1999 12显示 012
2 小数 FLOAT(7,3) 规定显示的值不会超过 7 位数字
FLOAT、DOUBLE 和 DECIMAL ,
3 int(3)、int(4)、int(8) 在磁盘bai上都是占用 4 btyes 的存储空间。说白了,除了显示给用户的方式有点不同外,int(M) 跟 int 数据类型是相同的。
数据库操作
// 查看数据库
SHOW databases;
SHOW schemas;
//创建数据库
create schema hua;
create database hua;
// 使用数据库
use hua;
//删除数据库
DROP database hua;
//查看数据库信息
SHOW create database hua;
显示当前数据库中所有表的名称
SHOW tables;//显示当前数据库的所有的表
SHOW tables from database_name;//显示某个数据库的所有的表
表的操作
//显示多少表
SHOW tables;
//创建表
create table huahua1(
id int auto_increment,
name varchar(25)
)
//修改表名
ALTER table huahua1 rename hua1;
//修改表的引擎
ALTER table engine InnoDB;
//查看表的结构
desc hua1;
// 看表的所有列
SHOW columns from table_name from database_name;
SHOW columns from database_name.table_name;
//修改表的列,可以添加约束
ALTER table hua1 modify id int(10);
// 改变列的位置
ALTER table hua1 modify sex int(1) after name;
// 修改列的名称
ALTER table hau1 change salary sal float;
// 添加新的列
ALTER table hua1 add sex int(0) default 0;
// 指定位置的字段,有first
ALTER table hua1 add hobby varchar(20) after sal;
//删除字段
ALTER table hua1 drop hobby;
ALTER table hua1 drop column hobby;
SELECT
SELECT name from cup; //查1行
SELECT name,age from cup; //查2行
SELECT * from cup; //查所有行
------ ------ ------ ------ ------ ------ ------ ------
@限制查询返回的数量
SELECT * from cup limit 2; //只要前两条
SELECT * from cup limit 2 offset 1 ; //从第1条开始取2条
------ ------ ------ ------ ------ ------ ------ ------
@条件判断
SELECT * from cup where id = 1;
SELECT * from cup where id > 1;
SELECT * from cup where id >= 1;
SELECT * from cup where id < 1;
------ ------ ------ ------ ------ ------ ------ ------
@范围筛选
// id 1,2,3都可以
SELECT * from cup where id in (1,2,3);
// id 不是1,2,3都可以
SELECT * from cup where id not in (1,2,3);
// id 大于1,2,3 的所有,就是大于全部才可以
SELECT * from cup where id > all (1,2,3);
SELECT * from cup where id >= all (SELECT id from cup);
// id 大于1,2,3中的1个就可以和下边一句是一样的 some和any一样用
SELECT * from cup where id > some (1,2,3);
SELECT * from cup where id > 1 or id > 2 or id > 3;
------ ------ ------ ------ ------ ------ ------ ------
@合并结果 union会删除重复的数据,union all不会删除重复的
// cup1和cup2的字段必须一样,如果不一样就合并一样的
SELECT * from cup1 union SELECT * from cup2;
@模糊查询
SELECT name from cup where name LIKE "hua%"; // hua开头的
SELECT name from cup where name LIKE "%hua%"; // 中间有hua的
@排序 order by
select * from user1 order by age;
------ ------ ------ ------ ------ ------ ------ ------
@计算
// 查询最高工资
select max(money) from user2;
// 查询最低工资
select min(money) from user2;
// 查询平均工资
select avg(money) from user2;
------ ------ ------ ------ ------ ------ ------ ------
@分组 分组一般配合计算
// 按年龄分组的工资
select age, AVG(money) from user2 group by age;
// 每个年龄段的最高工资
select age, MAX(money) from user2 group by age;
// 每个年龄段有多少人
select age, count(*) from user2 group by age;
@统计 查看表中年龄范围
select count(*) from user1 where age > 17 and age < 30;
约束
主键约束 primary key 非空且唯一
create table huahua1(
id int(11) primary key,
name varchar(25)
)
// 添加唯一约束
alter table student add unique(card_id);
// 增主键约束
ALTER table cup add primary key(id);
ALTER table cup drop primary key;
// 添加外键对应的列要是主键
alter table student add foreign key (card_id) references student_card(id);
// 可以多个值做成主键
primary key(name,deptid)
Mysql添加外键 !!
CREATE TABLE teacher(
t_id INT PRIMARY KEY AUTO_INCREMENT,
t_name VARCHAR(20)
);
CREATE TABLE class(
c_id INT PRIMARY KEY AUTO_INCREMENT,
c_name VARCHAR(20),
teacher_id INT
);
ALTER TABLE class ADD CONSTRAINT fk_teacher_id FOREIGN KEY (teacher_id) REFERENCES teacher(t_id);
JOIN 用法
大致分为内连接,外连接,右连接,左连接,自然连接
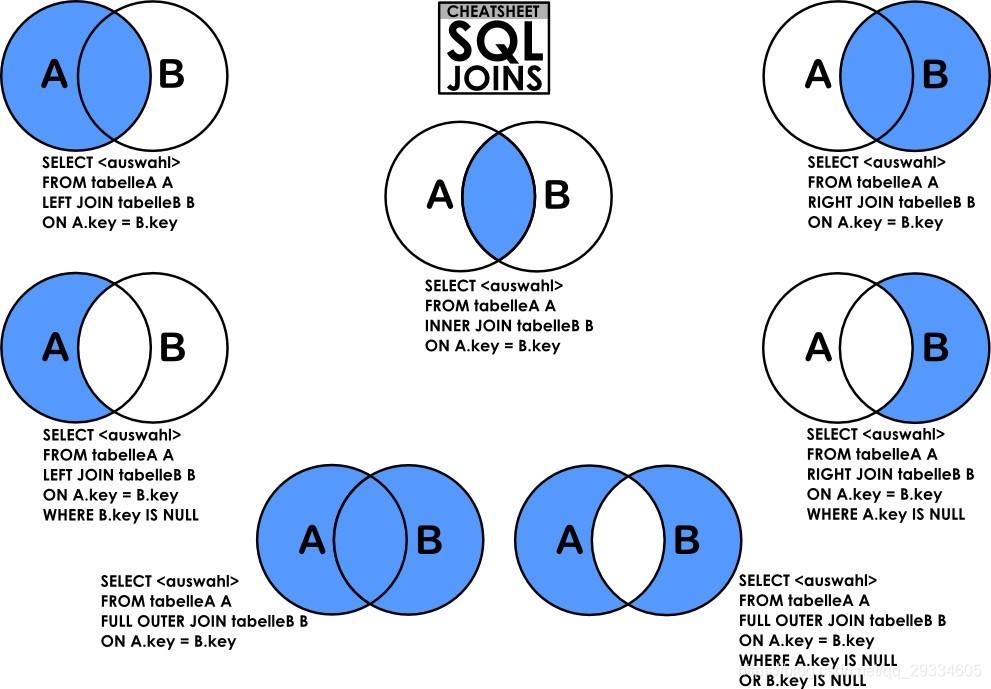
其它相关
SHOW grants; // 查看权限
SHOW index from table; //查看索引
SHOW engines; // 显示安装以后可用的存储引擎和默认引擎。
参考资料
(https://www.cnblogs.com/takumicx/p/9998844.html)
(https://www.cnblogs.com/beili/p/9140019.html)