决策树与随机森林
决策树是一个类似于流程图的树结构(类似二叉树),支持非线性运算。
一、一种决策树示例
如何判断如何决策?
方法之一:信息熵的方法
条件熵:在固定条件下,信息的不确定程度
信息熵:信息的不确定程度
信息增益:信息熵的变化量
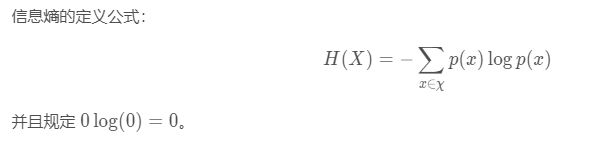
信息熵示例:抛硬币
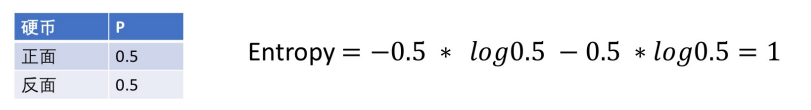
如何做决策?信息熵、条件熵、信息增益的关系。

例如预测是否打高尔夫的例子,
先计算各条件与是否打高尔夫之间的相关性,对影响决策的因素的关系进行简单可视化。
然后计算各类因素与是否打高尔夫球之间的信息熵。
然后通过计算在各条件下的其他因素信息熵,找出条件信息熵最大的选项作为该条件下的正确选项。
直到划分完成,形成一个完整的决策树。
决策树的缺点之一就是过拟合问题,在上述例子中,所有的数据皆有用,从建模样例数据看,分类十分准确,却往往与现实有差别,因此容易产生过拟合问题,变成为了答题而答题。
从而也容易因为样例数据的些许变化,导致整棵树的巨大变化。且不适用于数据类型分布不均匀的情况。
二、随机森林
随机森林是一种集成学习方法。用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。

随机森林是一个最近比较火的算法,它有很多的优点:
- 在数据集上表现良好,两个随机性(数据采样随机和投票随机)的引入,使得随机森林不容易陷入过拟合,具有很好的抗噪声能力
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
- 在创建随机森林的时候,对generlization error使用的是无偏估计
- 训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
- 实现比较简单
随机森林与决策树差别不大,多了一个多树构建和投票的过程。
多树构建:随机森林的每一棵决策树之间是没有关联的;每一棵树的构建都是按照决策树构建的方式进行的。
投票过程:加权平均等。
K-means:
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心,不断重复直到所有的点都作为中心点完成过计算。
K-Means聚类是一种常用于将数据集自动划分为K个组的方法,它属于无监督学习算法。
业务用途
这是一种通用算法,可用于任何类型的分组。部分使用案例如下:
- 行为细分:按购买历史记录细分,按应用程序、网站或者购买平台上的活动细分。
- 库存分类:按照销售活动分组存货(准备库存)。
- 传感器测量:检测运动传感器中的活动类型,并分组图像。
- 检测机器人或异常:从机器人中分离出有效地活动组。
k - means聚类算法:
- 步骤1:选择集群的数量K。
- 步骤2:随机选择K个点,作为质心。(不一定要从你的数据集中选择)
- 步骤3:将每个数据点分配到-> 构成K簇的最近的质心。
- 步骤4:计算并重新放置每个集群的新质心。
- 步骤5:将每个数据点重新分配到最近的质心。如果有任何重置发生,转到步骤4,否则转到FIN。