用jupyter完成
import pandas as pd
data = pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'])
data

data = pd.read_excel(r'C:\Users\acer\Desktop\666.xlsx')
data.head(5) #展示的是表中数据的前五行
data.tail(5)#查看最后五行
data = pd.read_excel(r'C:\Users\acer\Desktop\物料信息导出.xlsx',encoding='gbk',dtype={
'物料代码':str})#把某一列的值改为某种格式
data.dtypes#查看每一列是什么数据格式
pd.__version__#查看pandas是哪个版本的
data = pd.read_excel(r'C:\Users\acer\Desktop\物料信息导出.xlsx',encoding='gbk',dtype={
'物料代码':str},nrows=10)#展示表里的前十列数据
data = pd.read_excel(r'C:\Users\acer\Desktop\物料信息导出.xlsx',encoding='gbk',dtype={
'物料代码':str},nrows=10,na_value=70)#缺失值标为70
data
必须要在地址前面加上r’,才能成功导入,表示的是即保持字符原始值的意思
series
1.创建序列
#第一种
series1=pd.Series([1.1,2.5,3.6],index=['a','b','c'])
#第二种
series2=pd.Series(np.array([1.1,2.5,3.6]),index=['a','b','c'])
#基于字典创建
series3=pd.Series({
'北京':2.8,'上海':3.01,'广东':8.99})
结果:


2.series常见的属性
通过pandas.Series来创建Series数据结构:pandas.Series(data,index,dtype,name)。
data可以为列表,array或者dict。 index表示索引,必须与数据同长度,name代表对象的名称
| values | 返回Series对象所有元素 |  |
| index | 返回索引 |  |
| dtypes | 返回数据类型 |  |
| shape | 返回series数据形状 | 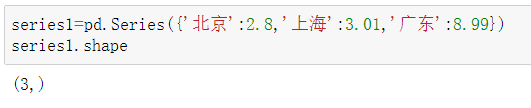 |
| ndim | 返回对象的维度 |  |
| size | 返回对象的个数 | 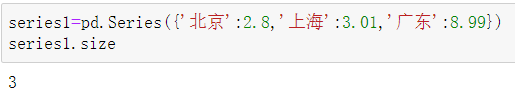 |
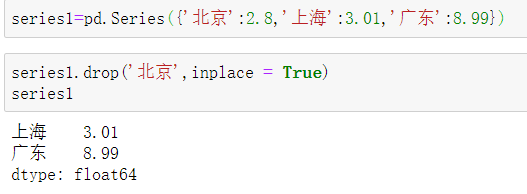
series1.drop('北京',inplace=Ture)#不创建新的对象,直接对原始对象进行修改
DataFrame
通过pandas.DataFrame来创建DataFrame数据结构。
pandas. DataFrame(data,index,dtype,columns)
上述参数中,data可以为列表,array或者dict。
上述参数中,index表示行索引,columns代表列名或者列标签
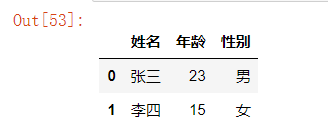
list1=[['张三',23,'男'],['李四',15,'女']]
list1
df1 = pd.DataFrame(list1,columns = ['姓名','年龄','性别'])
df1
2.向DataFrame传递字典的结构
df1=pd.DataFrame({
'姓名':['张三','李四','王五','五六'],'年龄':[23,25,26,28],'性别':['男','女','男','女']})
df1
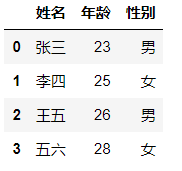
3.通过数组结构来创建
array=np.array(list1)
array
df3=pd.DataFrame(array,columns = ['姓名','年龄','性别'],index=['a','b'])
#index的个数要和数据的个数一样
df3
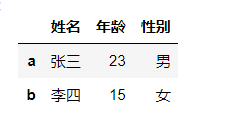
df2.coluans.tolist() 表示由哪几列组成