前言
C语言博大精深,我在把谭浩强那本《c语言程序设计》看完后发现碰到开源程序仍有看不懂的东西,所以把题解与上机指导那本书拿来补充一下缺漏知识。
先放出谭浩强《C程序上机题解与上机指导》的补充知识部分的目录

一、位运算:
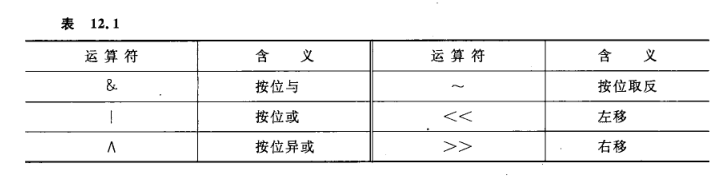
说明:
(1)位运算符中除“~”以外,均为二目(元)运算符,即要求两侧各有一个运算量。如a&b.
(2)参加位运算的对象只能是整型或字符型的数据,不能为实型数据。下面对各种位运算分别介绍。
#include<stdio.h>
int main()
{
unsigned a = 0xffffe0ff, b = 0xffffc2ff;
//%x按16进制输出。
printf("%x\n", a & b); //按位与
printf("%x\n", a | b); //按位或
printf("%x\n", a ^ b); //按位异或
printf("%x\n", ~a); //按位取反
printf("%x\n", a << 4); //左移4位(乘以2的4次方)
printf("%x\n", a >> 8); //右移8位(除以2的8次方)
printf("这里一个f占4位,即‘1111’,十进制的15\n");
return 0;
}
例:实现循环右移

#include<stdio.h>
#define WORDSIZE 32 //我现在是X86模式编译,占32位,4字节(32位=4字节)
int main()
{
unsigned a, b, c;
int n;
printf("请输入a和n \n");
scanf("%x,%d", &a, &n);
b = a << (WORDSIZE - n);//书中源码这里是16(字节),我运行发现总是不对,发现我现在是X86模式编译,占32位
c = a >> n;
c = c ^ b;
printf("a:%x \nc:%x", a, c);
return 0;
}运行结果:

以下来自:
https://zhidao.baidu.com/question/165145005.html
移位 -- 不是“位移”操作
n<<3,2进制,左移3位,就是 n=n*2*2*2, 就是n*8
0,1,2,3 -- 变 0,8,16,24
x >> 24 最高字节 移到最左, & 0xff 取出来。
x >> 16 第二 高字节 移到最左, & 0xff 取出来。
x >> 8 第3 高字节 移到最左, & 0xff 取出来。
x >> 0 不移动,& 0xff 取出来。
例如:
00111111 01010101 11111111 00000001
x >> 8 得
00000000 00111111 01010101 11111111
x >> 16 得
00000000 00000000 00111111 01010101
x >> 24 得
00000000 00000000 00000000 00111111
关于“位段”
c语言允许在一个结构体中以位为单位来指定其成员所占用的内存长度,
这种以位为单位的成员成为“位段”或“位域”(bit field)。
利用位段能用较少的位数存储数据


使用“位段”
类型名 [成员名]:宽度;
#include<stdio.h>
struct Packed_data
{
unsigned a : 2;
unsigned b : 2;
unsigned c : 2;
unsigned d : 2;
short i;
}data1;
struct Packed_data2
{
unsigned a : 2;
unsigned b : 3;
unsigned c : 4;
short i;
}data2;
int main()
{
printf("%d\n", sizeof(data1));
printf("%d\n", sizeof(data2));
return 0;
}
实际上会遇到系统的“自动补全”(至少占一个存储单元,即一个机器字(64位的一个字(WORD)是8字节)),结果如上图,data2也是8个字节。

*位段空间分配方向因机器而异。一般是从右到左进行分配(如图)。
二、预处理:
C语言允许在源程序中加人一些“预处理指令”( preprocessing directive),以改进程序设计环境,提高编程效率。这些预处理指令是由C标准建议的,但是它不是C语言本身的组成部分,不能用C编译系统直接对它们进行编译(因为编译程序不能识别它们)。必须在对程序进行正式编译(包括词法和语法分析、代码生成、优化等)之前,先对程序中这些特殊的指令进行“预处理"(preprocess,也称"编译预处理"或“预编译”)。把预处理指令转换成相应的程序段,它们和程序中的其他部分组成真正的C语言程序.对预处理指令进行的预处理工作,是由称为C预处理器(preprocessor)的程序负责处理的.
在预处理阶段,预处理器把程序中的注释全部删除;对预处理指令进行处理,如把#include指令指定的头文件(如stdio.b)的内容复制到#include指令处:对#define指令,进行指定的字符替换(如将程序中的符号常量用指定的字符串代替),同时删去预处理指令。
经过预处理后的程序不再包括预处理指令了,最后再由编译程序对预处理后的源程序进行实际的编译处理,得到可供执行的目标代码。现在使用的许多C编译系统,把C预处理器作为C编译系统的一个组成部分,在进行编译时一气呵成。因此有的用户误认为预处理指令是C语言的一部分,甚至以为它们是C语句,这是不对的。必须正确区别预处理指令和C语句区别预处理和编译,才能正确使用预处理指令。C语言与其他高级语言的一个重要区别是可以使用预处理指令和具有预处理的功能。
1.预处理指令:
https://www.cnblogs.com/zi-xing/p/4550246.html
- #空指令,无任何效果
- #include包含一个源代码文件
- #define定义宏
- #undef取消已定义的宏(限制作用域)
- #if如果给定条件为真,则编译下面代码
- #ifdef如果宏已经定义,则编译下面代码
- #ifndef如果宏没有定义,则编译下面代码
- #elif如果前面的#if给定条件不为真,当前条件为真,则编译下面代码
- #endif结束一个#if……#else条件编译块
- #error停止编译并显示错误信息
书上说了3种情况:
- 宏定义(3,4)
“宏定义”是用指定标识符代替字符串(不分配内存,所以不要把 宏名 当做 变量名 使用);同时也是条件编译的“条件”
例,把“3.14”宏置换为“PI”
#define PI 3.14详细介绍:https://www.jianshu.com/p/2915629103e4
- 文件包含处理(2)
“文件包含”指令是很有用的,它可以节省程序设计人员的重复劳动。
例如,某单位的人员往往使用一组固定的符号常量(如g-9.11,pi-3. 1415926,e= 2.71........可.以把这些宏定义指令组成一个头文件,然后各人都可以用# include指令将这些符号常量包含到自己所写的源文件中,而不必自己重复定义这些符号常量,相当于工业上的标准零件,拿来就用。
#include "BiaoHaoKu"
- 条件编译(5,6,7,8,9)
条件编译对于提高C源程序的通用性是很有好处的。
如果一个C源程序在不同计算机系统上运行,而不同的计算机又有一-定的差异(例如,有的机器以16位(2个字节)来存放一个整数,而有的则以32位存放一个整数),这样在不同的计算机上编译程序时往需要对源程序作必要的修改,这就降低了程序的通用性。
例:解决int位长
#ifedf COMPUTER A
#define INTEGER 16
#cise
#define INTEGER_SIZE 32
#endif
如果在↑上面这组条件编译指令之前曾出现以下指令行:
#defne COMPUTER_A 0
或将COMPUTERA定义为任何字符串,甚至是
# deline COMPUTER_A即只要COMPUTER_A已被定义过,则在程序预编译时就会奏效——预编译后程序中的INTEGER SIZE都用16代替否则都用32代替。
这样,源程序可以不必做任何修改就可以用于不同类型的计算机系统。当然以上介绍的只是一种简单的情况,读者可以根据此思路设计出其他条件编译。
例:部分模式时有用(在想输出信息时输出信息)
#ifedf DEBUG
printf("开启debug模式。x=%d",x);
#endif
2.关于 #pragma once:
方式一:
#ifndef的方式依赖于宏名字不能冲突,这不光可以保证同一个文件不会被包含多次,也能保证内容完全相同的两个文件不会被不小心同时包含。当然,缺点就是如果不同头文件的宏名不小心"撞车",可能就会导致头文件明明存在,编译器却硬说找不到声明的状况
#ifndef __SOMEFILE_H__
#define __SOMEFILE_H__
... ... // 一些声明语句
#endif方式二:
#pragma once则由编译器提供保证:同一个文件不会被包含多次。注意这里所说的"同一个文件"是指物理上的一个文件,而不是指内容相同的两个文件。带来的好处 是,你不必再费劲想个宏名了,当然也就不会出现宏名碰撞引发的奇怪问题。对应的缺点就是如果某个头文件有多份拷贝,本方法不能保证他们不被重复包含。当 然,相比宏名碰撞引发的"找不到声明"的问题,重复包含更容易被发现并修正。
#pragma once
... ... // 一些声明语句