乒乓操作法
乒乓操作法是FPGA 开发中的一种数据缓冲优化设计技术,可以看成是另一种形式的流水线技术。输入的数据流在通过“输入数据流选择单元”时,时间等分地将数据流分配到两个数据缓冲模块内。数据缓冲模块可以是FPGA 中的任何存储模块,如双口RAM、单口RAM 和FIFO等。
乒乓操作的流程:
在第一个缓冲周期,将输入的数据流缓存到“数据缓冲模块1";
在第二个缓冲周期,通过“输入数据流选择单元”的切换,将输入的数据流缓存到“数据缓冲模块2”,同时将“数据缓冲模块1”缓存的第一个周期的数据通过“输出数据流选择单元”的选择,送到“数据流运算处理模块”进行运算处理;
在第三个缓冲周期,通过“输入数据流选择单元”的再次切换,将输入的数据流缓存到“数据缓冲模块1”,同时将“数据缓冲模块2”缓存的第二个周期的数据通过“输出数据流选择单元”的切换,送到“数据流运算处理模块”进行运算处理,如此循环往复。
乒乓操作的特点:
(1)输入数据流和输出数据流都是连续不断的,没有任何停顿,因此特别适用于对数据流进行流水线式处理。因此,乒乓操作法常应用于流水线式算法,完成数据的无缝缓冲与处理。
(2)需要使用双倍的存储器资源。
(3)适用于数据来不及每次传输都进行处理,需要缓存的情况。
乒乓操作实例
模块简介
模块中使用到了 RTL设计(2)- 双口RAM。
模块功能:使用AXI-Stream通信,将1024个32bit数据转换为8bit数据输出。
时序逻辑:
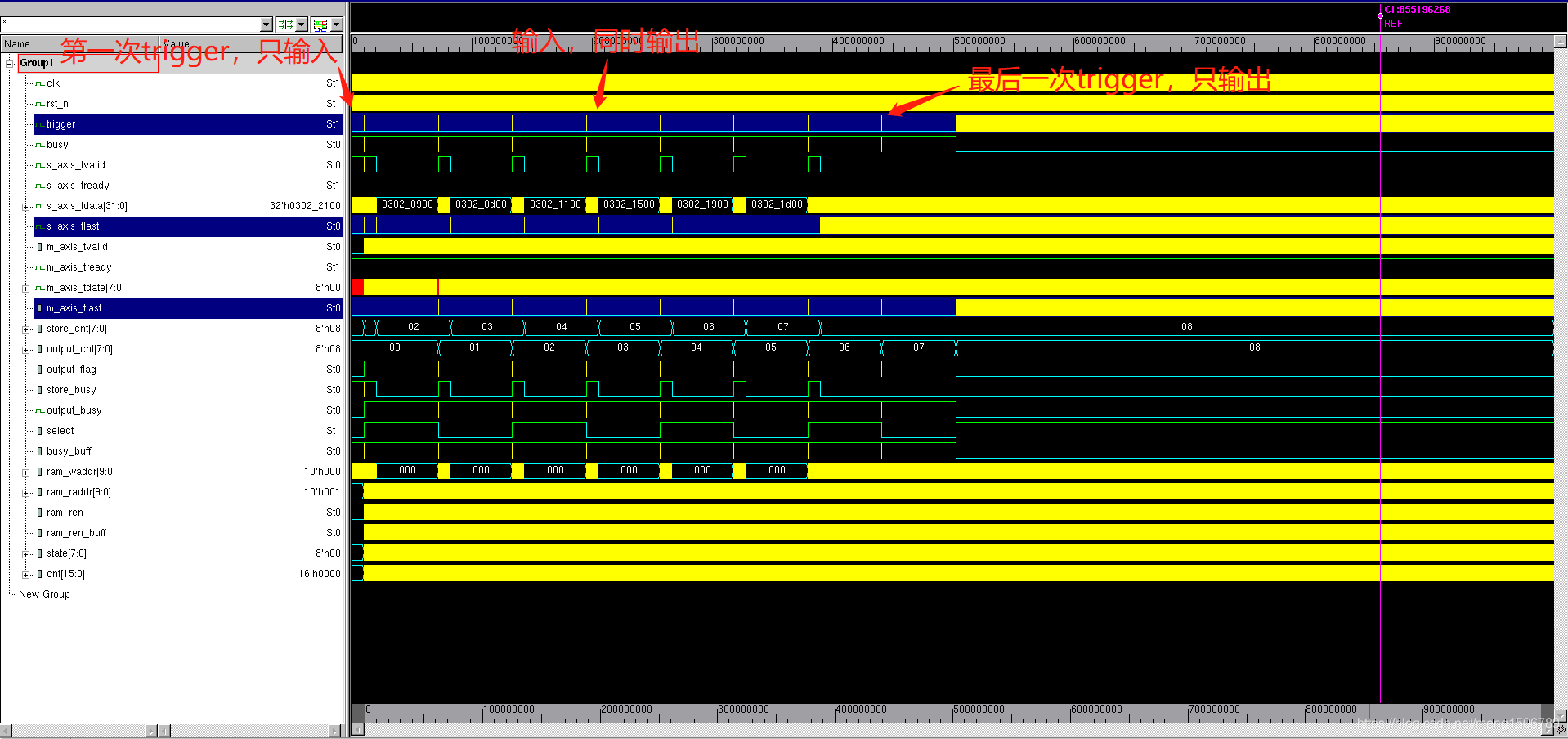
第1次 trigger == 1脉冲信号:写入数据到ram_ping
第2次 trigger == 1脉冲信号:切换select,写入数据到ram_pong,同时将ram_ping的数据输出
第3次 trigger == 1脉冲信号:切换select,写入数据到ram_ping,同时将ram_pong的数据输出
…
第8次 trigger == 1脉冲信号:切换select,写入数据到ram_pong,同时将ram_ping的数据输出
第9次(仿真中的最后一次) trigger == 1脉冲信号:切换select,将ram_ping的数据输出
注意:当程序设计中,数据截取的寻址过于复杂时,可以使用多维reg数组来简化寻址逻辑。
如:reg [7:0] data[15:0][8:0];
程序
dataconvert.v
`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/09
// Author Name: Sniper
// Module Name: dataconvert
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module dataconvert
#(
parameter BUS_DATA_WIDTH = 32
)
(
input clk,
input rst_n,
input trigger,//pulse signal
output busy,
//AXI-Stream input
input s_axis_tvalid,
output s_axis_tready,
input [BUS_DATA_WIDTH-1:0] s_axis_tdata,
input s_axis_tlast,
//AXI-Stream output
output reg m_axis_tvalid,
input m_axis_tready,
output [7:0] m_axis_tdata,
output reg m_axis_tlast
);
assign s_axis_tready = 1;
//count control
reg [7:0] store_cnt;
reg [7:0] output_cnt;
always@(posedge clk or negedge rst_n)
if(!rst_n)
store_cnt <= 0;
else if(s_axis_tvalid & s_axis_tready & s_axis_tlast)
store_cnt <= store_cnt + 1;
always@(posedge clk or negedge rst_n)
if(!rst_n)
output_cnt <= 0;
else if(m_axis_tvalid & m_axis_tready & m_axis_tlast)
output_cnt <= output_cnt + 1;
//output_flag control
reg output_flag;
always@(posedge clk or negedge rst_n)
if(!rst_n)
output_flag <= 0;
else if(trigger && output_cnt != store_cnt && !busy)
output_flag <= 1;
else if(m_axis_tvalid & m_axis_tready & m_axis_tlast)
output_flag <= 0;
//busy control
reg store_busy;
wire output_busy;
always@(posedge clk or negedge rst_n)
if(!rst_n)
store_busy <= 0;
else if(s_axis_tvalid & s_axis_tready & s_axis_tlast)
store_busy <= 0;
else if(s_axis_tvalid & s_axis_tready)
store_busy <= 1;
assign output_busy = output_flag;
assign busy = store_busy | output_busy;
//ping-pong control
reg select;
reg busy_buff;
always@(posedge clk or negedge rst_n)
if(!rst_n)
select <= 0;
else
begin
busy_buff <= busy;
if(busy_buff & ~busy)//remove busy
select <= ~select;
end
localparam RAM_NUM = BUS_DATA_WIDTH/8;
localparam RAM_DEPTH = 1024;
reg [$clog2(RAM_DEPTH)-1:0] ram_waddr;
reg [$clog2(RAM_DEPTH)-1:0] ram_raddr;
wire [7:0] ram_wdata[RAM_NUM-1:0];
wire [7:0] ram_ping_rdata[RAM_NUM-1:0];
wire [7:0] ram_pong_rdata[RAM_NUM-1:0];
reg ram_ren;
//ram_waddr control
always@(posedge clk or negedge rst_n)
if(!rst_n)
ram_waddr <= 0;
else if(s_axis_tvalid & s_axis_tready & s_axis_tlast)
ram_waddr <= 0;
else if(s_axis_tvalid & s_axis_tready)
ram_waddr <= ram_waddr + 1;
//data locate
reg [7:0] ram_rdata_buff[RAM_NUM-1:0];
reg ram_ren_buff;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin
//ram_rdata_buff[RAM_NUM-1:0] <= 0;
ram_ren_buff <= 0;
end
else
begin
ram_ren_buff <= ram_ren;
if(ram_ren_buff)
ram_rdata_buff[RAM_NUM-1:0] <= select ? ram_pong_rdata[RAM_NUM-1:0] : ram_ping_rdata[RAM_NUM-1:0];
else if(m_axis_tvalid & m_axis_tready)
ram_rdata_buff[RAM_NUM-1:0] <= {
ram_rdata_buff[0], ram_rdata_buff[RAM_NUM-1:1]};//shift right round
end
assign m_axis_tdata = ram_rdata_buff[0];
//m_axis_tvalid control
reg [7:0] state;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin
m_axis_tvalid <= 0;
ram_ren <= 0;
state <= 0;
end
else
begin
if(output_flag)
case(state)
0:
begin
state <= state + 1;
m_axis_tvalid <= 0;
ram_ren <= 1;
end
1:
begin
state <= state + 1;
ram_ren <= 0;
end
2:
begin
state <= state + 1;
m_axis_tvalid <= 1;
end
3,4,5,6:
begin
if(m_axis_tvalid && m_axis_tready)
begin
state <= state + 1;
if(state == 6)
begin
state <= 1;
m_axis_tvalid <= 0;
ram_ren <= 1;
end
end
end
default: state <= 0;
endcase
else
begin
m_axis_tvalid <= 0;
ram_ren <= 0;
state <= 0;
end
end
//m_axis_tlast control
reg [15:0] cnt;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin
m_axis_tlast <= 0;
cnt <= 0;
end
else if(m_axis_tvalid && m_axis_tready)
begin
if(cnt == RAM_DEPTH*BUS_DATA_WIDTH/8-1 -1)
m_axis_tlast <= 1;
else
m_axis_tlast <= 0;
if(cnt == RAM_DEPTH*BUS_DATA_WIDTH/8 -1)
cnt <= 0;
else
cnt <= cnt + 1;
end
//ram_rd control
always@(posedge clk or negedge rst_n)
if(!rst_n)
ram_raddr <= 0;
else if(trigger && output_cnt != store_cnt && !busy)
ram_raddr <= 0;
else if(ram_ren)
ram_raddr <= ram_raddr + 1;
genvar i;
generate
for(i=0;i<RAM_NUM;i=i+1)
begin
assign ram_wdata[i] = s_axis_tdata[8*(i+1)-1 -:8];
dualram
#(
.WIDTH(8),
.DEPTH(RAM_DEPTH)
)
u_ram_ping
(
.wr_clk(clk),
.wr_addr(ram_waddr),
.wr_data(ram_wdata[i]),
.wr_en(s_axis_tvalid & s_axis_tready & select),
.rd_clk(clk),
.rd_addr(ram_raddr),
.rd_data(ram_ping_rdata[i]),
.rd_en(ram_ren & ~select)
);
dualram
#(
.WIDTH(8),
.DEPTH(RAM_DEPTH)
)
u_ram_pong
(
.wr_clk(clk),
.wr_addr(ram_waddr),
.wr_data(ram_wdata[i]),
.wr_en(s_axis_tvalid & s_axis_tready & ~select),
.rd_clk(clk),
.rd_addr(ram_raddr),
.rd_data(ram_pong_rdata[i]),
.rd_en(ram_ren & select)
);
end
endgenerate
endmodule
tb_dataconvert.sv

`timescale 1ns / 1ps
// Company:
// Engineer:
//
// Create Date: 2020/12/10
// Author Name: Sniper
// Module Name: tb_dataconvert
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
module tb_dataconvert;
//parameter
parameter BUS_DATA_WIDTH = 32;
//input
reg clk;
reg rst_n;
reg trigger;
reg s_axis_tvalid;
reg [BUS_DATA_WIDTH-1:0] s_axis_tdata;
reg s_axis_tlast;
reg m_axis_tready;
//output
wire busy;
wire s_axis_tready;
wire m_axis_tvalid;
wire [7:0] m_axis_tdata;
wire m_axis_tlast;
reg [7:0] rand_n;
int percent = 20;
initial
begin
clk = 0;
rst_n = 0;
trigger = 0;
m_axis_tready = 1;
#100;
rst_n = 1;
$srandom(100);//random seed
forever @(posedge clk)
begin
rand_n = $urandom_range(99);
m_axis_tready <= rand_n >= percent;
end
end
//clock
always #5 clk = ~clk;
//trigger
reg [3:0] trig_state;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
trigger <= 0;
trig_state <= 0;
end
else
begin
case(trig_state)
0:
begin
trigger <= 0;
trig_state <= trig_state + 1;
end
3:
begin
if(!busy)
begin
trigger <= 1;
trig_state <= 0;
end
end
default: trig_state <= trig_state + 1;
endcase
end
end
//axis_write
reg [7:0] sys_state;
reg [15:0] cnt;
reg [7:0] trigger_cnt;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
s_axis_tvalid <= 0;
s_axis_tdata <= {
8'd3,8'd2,8'd1,8'd0};
s_axis_tlast <= 0;
sys_state <= 0;
cnt <= 0;
trigger_cnt <= 0;
end
else
begin
case(sys_state)
0:
begin
s_axis_tvalid <= 0;
s_axis_tlast <= 0;
cnt <= 0;
sys_state <= sys_state + 1;
end
1:
begin
if(trigger)
begin
trigger_cnt <= trigger_cnt + 1;
if(trigger_cnt < 8)
begin
s_axis_tvalid <= 1;
sys_state <= sys_state + 1;
end
else
trigger_cnt <= trigger_cnt;
end
end
2:
begin
if(s_axis_tvalid & s_axis_tready)
begin
s_axis_tdata <= s_axis_tdata + 1;
cnt <= cnt + 1;
if(cnt == 1022)
s_axis_tlast <= 1;
if(cnt == 1023)
begin
cnt <= 0;
sys_state <= 0;
s_axis_tvalid <= 0;
s_axis_tlast <= 0;
end
end
end
default: sys_state <= 0;
endcase
end
end
//DUT
dataconvert
#(
.BUS_DATA_WIDTH(BUS_DATA_WIDTH)
)
DUT
(
.clk(clk),
.rst_n(rst_n),
.trigger(trigger),
.busy(busy),
.s_axis_tvalid(s_axis_tvalid),
.s_axis_tready(s_axis_tready),
.s_axis_tdata(s_axis_tdata),
.s_axis_tlast(s_axis_tlast),
.m_axis_tvalid(m_axis_tvalid),
.m_axis_tready(m_axis_tready),
.m_axis_tdata(m_axis_tdata),
.m_axis_tlast(m_axis_tlast)
);
initial
begin
$dumpfile("tb_dataconvert.vcd");
$dumpvars(0,tb_dataconvert);
end
initial #1_000_000 $finish;
endmodule
运行结果
vcs -R -sverilog dualram.v dataconvert.v tb_dataconvert.sv
输出端保持 ready=1 :
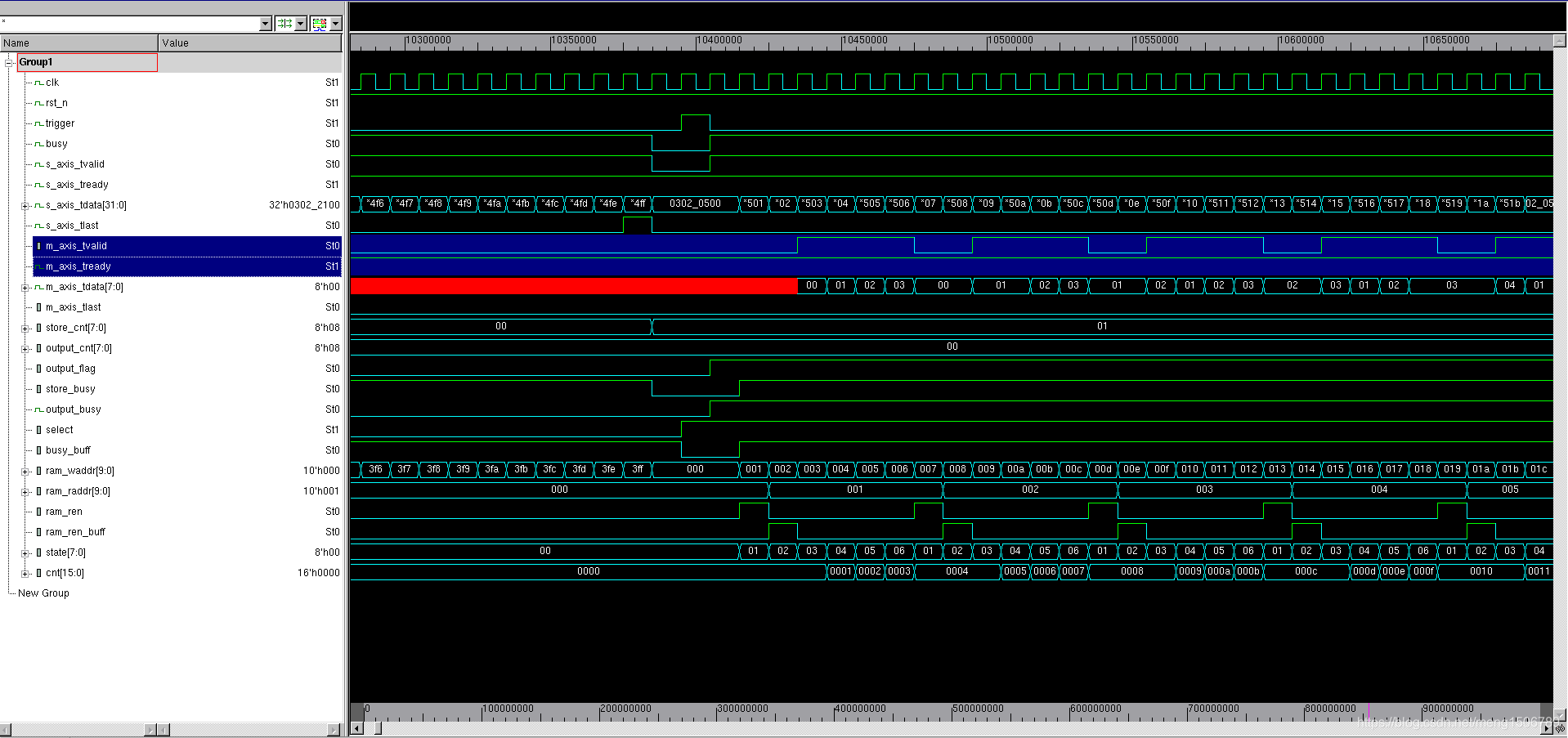
输出端 ready是随机的,用来验证AXI-Stream的流控功能: