一、自定义表:
1. 数据类型:
I. 字符串:
char(n):固定长度字符串,上限2000,最大长度为n,实际长度也是n,其余用空格填充。 (不设置长度时,默认长度为1)
例如:char(5) 'abcd' 最大长度5,实际长度5,不足位的使用空格填充。
varchar(n):上限4000工业标准,支持空字符串,Oracle的varchar2是非工业标准,改为存储null值。可能未来不支持,无法向后兼容。
varchar2(n):可变长度字符串,上限4000,最大长度为n,实际长度为字节个数。 (必须有固定长度)
例如:varchar2(5) '你好' 最大长度5,实际长度4 //存储字节:5个,存储字符:2个
nvarchar2(n):可变长度字符串,上限2000,最大长度为n,实际长度为字符个数。 (必须有固定长度)
例如:varchar2(5) '你好' 最大长度5,实际长度2 //存储字节:5个,存储字符:5个
II. 数字:
integer:任意长度的整数,超过15位后使用科学计数法显示xE10^N。 (只保留整数部分,输入小数自动失去精度)
number / number(n) / number(n,m):可用于描述整数长度和小数长度
例如:number 可存储任意长度的的小数
例如:number(5) 可存储总长度为5的整数 1234 //correct 最大(38,n)
例如:number(5,2) 可存储总长度为5的整数+小数 1234.00 //error(小数自动精确到具体长度,总长度不能超过指定值)
12.3实际存储值为12.30(长度为4)//correct
1234.5实际存储值为1234.50(长度为6) //error
III. 时间:
date:年月日时分秒,只精确到秒。通过sysdate获取的系统时间所对应的类型就是date。 //可用timestamp
IV.大对象类型【了解】:
CLOB:存储大本文(字符)数据。---Solr全文搜索
BLOB:存储较大二进制文件(多媒体文件,最大4GB)。---MapReduce+HDFS大数据分析+文件存储(PB级)
2. 约束:
I. 主键约束:primary key 唯一的标识表中的一行数据,此列的值不可重复,不可为null,一张表中只能有一个主键列。不变的列适合做主键。
II. 唯一约束:unique 唯一的标识表中的一行数据,不可重复,可以为null(可重复),一张表中可以有多个唯一列。
III. 非空约束:not null 此列必须有值。
IV. 检查约束:check 通过制定规则,约束此列中的值必须满足某条件才能插入。
//列:email,要求此列中的值必须包含'@zpark'
check( email like'%@zpark%' )
//列:password,要求此列中的值长度必须是6位。
check( length(password) = 6 )
check( password like'______' ) //6个_
//列:sex,要求此列中的值必须是'男'或者'女'
check( sex = '男' or sex = '女' )
check( sex in ('男','女') )
//列:age 要求此列中的值必须在1~160之间
check( age >= 1 and age <= 160)
check( age between 1 and 160)
V. 外键约束:foreign key引用外部表的某个列的值,插入数据时,约束此列的值必须是引用表中存在的数据。二者的数据类型必须相同。
语法:references 外部表(字段) //clazz_id number(6) references clazz(clazz_id)

3. 建表【重点】:
I. 语法:
create table 表名(
列名 数据类型 [约束],
列名 数据类型 [约束],
......
列名 数据类型 [约束] //最后一列的末尾不加逗号
);
create table 表名(列名1 数据类型 [约束] , 列名2 数据类型 [约束] , 列名3 数据类型 [约束] )
II. 用例:
//存储班级信息
班级编号 number(6) 主键
班级名称 varchar2(50) 非空

//存储学生信息
学号 varchar2(50) 主键
姓名 varchar2(50) 非空
性别 varchar2(1) 检查(M,F)
生日 date 非空
电话 varchar2(50) 唯一
邮箱 varchar2(30) 无
班级编号 number(6) 外键(班级表的班级编号)

//引用clazz表的clazz_id列的值作为外键,插入时约束学生的班级编号必须存在。
alter table t_student add clazz_Id integer; //添加列
alter table t_student add constraint pk_clazz_Id foreign key (clazz_Id) references t_clazz(clazz_Id); //添加外键约束
注:
1).如创建后需要删除表,使用drop table 表名;
2).创建关系表时,先创建主表,再创建从表(添加引用)。
3).删除关系表时,先删除从表,再删除主表。
二、数据操作(增删改):
1. 插入(insert):
I. 语法:insert into 表名(列1,列2,列3...) values(值1,值2,值3...);
II. 详解:表名后的列名和values后的值要一一对应。
III. 用例:
//添加一条班级信息(10、17级79班)
insert into clazz (clazzid , clazzname) values(10,'17级79班');
//添加一名学生信息(1001、tom、M、1995-1-1、10)
insert into t_student (student_id , student_name , sex , borndate , phone , clazz_id)
values(1001,'tom','M',to_date('1995-01-01','yyyy-mm-dd'),'13900000001',10);
注:输入外键时,必须保证此值在主表中已经存在,否则无法插入。
//省略列名(输入所有值)
insert into t_student
values(1003,'marry','F',to_date('1995-02-02','yyyy-mm-dd'),'13900000003',10);
注:顺序和个数必须和列的定义一致
//省略列名(输入部分值)
insert into t_student
values(1003,'marry','F',to_date('1995-02-02','yyyy-mm-dd'),null,10);
注:缺省部分使用null填充
2. 修改(update):
I. 语法:update 表名 set 列1 = 新值1, 列2 = 新值2 ,... where 条件;
II. 详解:set后跟多个 列名 = 值 ,绝大多数情况下都要加where条件,否则为全表更新。
III. 用例:
//修改1001的电话为13900001111
update t_student set phone = '13900001111' where student_id = '1001';
//修改1002的名字为'marry'、性别为'女'
update t_student set s_name = 'marry', sex = 'F' where s_id = '1002';
//修改班级名称为'2017级79班'学生的班级编号为20
update t_student set clazz_id = 20 where clazz_id = (select clazz_id from t_clazz where clazz_name = '2017级79班')
3. 删除(delete):
I. 语法:delete from 表名 where 条件;
II. 详解:删除表中满足where条件的数据。
III. 用例:
//删除学号为J003的学生信息
delete from student where student_id = 'J003';
//删除班级名称为'2017级79班,并且叫tom的男同学
delete from t_student
where student_name = 'tom' and sex = 2 and clazz_id = (select clazz_id from clazz where clazz_name = '2017级79班')
//删除班级编号为10的班级信息
delete from clazz where clazz_id = 10; //ERROR 删除被引用的数据时,必须先删从表数据,再删主表数据。不允许从表数据孤立。
4. 补充:联合主键、联合约束(Excel)
问题描述:创建成绩表,分别存储学生ID和科目名称。描述一个学生的一门课程的成绩。
应用场景:约束一个学生在输入成绩时,相同科目,只能输入一次成绩。拒绝重复数据插入(学生ID+课程编号)。
解决方案:将学生姓名和科目名称作为联合主键。
create table t_score(
student_name varchar2(20) not null,
subject_name varchar2(50) not null,
score number(5,2) check(score between 1 and 100) not null ,
primary key(student_name , subject_name) //联合主键(通过多个字段值来唯一标识一行数据)
);
//或者使用 unique(字段1,字段2,...) //联合约束
三、事务:
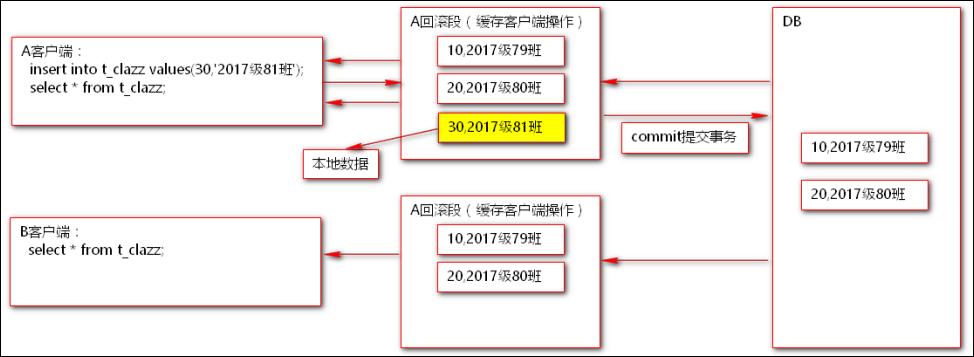
问题1:
insert into clazz(clazz_id,clazz_name) values (49,'Java49班');
A客户端执行一条班级表的插入的语句,使用B客户端查询不到数据?
原因:只有执行了commit才会改变数据库中的数据。
问题2:
转账操作:A给B转账10000元。A账户减,B账户加。
通过事务来控制原子操作
update account set balance = balance - 10000 where id = '6222020200001111'; ---将'6222020200001111'账户余额减10000
如果此时系统断电,下面的SQL语句将不会执行
update account set balance = balance + 10000 where id = '6222020200002222'; --将'6222020200002222'账户余额加10000
1. 概念:
事务是一个原子操作,可以由一条或多条SQL组成。
在同一个事务当中,所有的SQL都成功执行时,整个事务成功,有一条SQL执行失败,整个事务都执行失败。
2. 事务的边界:
I. 开始:上一个事务结束后的第一条增删改的语句,即事务的开始。
II. 结束:
1). 提交:
a. 显示提交:commit;
b. 隐式提交:一条创建、删除的语句,正常退出(SQL*Plus EXIT);
2). 回滚:
a. 显示回滚:rollback;
b. 隐式回滚:非正常退出(断电、Down机)。
3. 事务的原理:
数据库会为每一个客户端都维护一个空间独立的缓存区(回滚段),一个事务中所有的增删改语句的执行结果都会缓存在回滚段中,只有当事务中所有SQL语句均正常结束(commit),才会将回滚段中的数据同步到数据库。否则无论因为哪种原因失败,整个事务将回滚(rollback)。
注:create、drop、alter语句,自带commit。
4. 生产环境:基于增删改语句的操作结果(均返回操作后受影响的行数),可通过程序逻辑手动控制事务提交或回滚。
5. 事务的特性:ACID
I. 原子性(Atomic) :同一事务中的多个sql是不可分割的整体,都成功才成功,有一个失败,就全部失败。
II. 一致性(Consistency) :事务开始前和事务结束后,数据库中数据保持一致。
III. 隔离性(Isolation) :事务与事务之间相互独立,互不干涉。
IV. 持久性(Durability):事务执行后,对数据库的影响是永久的。
四、操作优化:
1. 序列【重点】:
I. 语法:create sequence序列名 [参数];
II. 详解:用来生成一列自动增长的值。
create sequence seq_class
[minvalue 值] //最小值
[maxvalue 值] //最大值
[start with ] //起始值
[increment by 值] //递增数
[cache 缓存个数] //每次生成时,可一次获取多个序列编号,避免每次生成都访问数据库服务器。
[cycle] //循环,当生成序列数达到maxvalue后,是否循环使用。根据业务,允许不唯一的列可以使用。
[order] //保证获取顺序。当数据量庞大时,序列只能保证顺序的唯一性,而不保证数据的序列数的顺序。1~10,21~30,11~20
注:默认start with 1 increment by 1
III. 用例:
select seq_student.nextval from dual; //获取下一个递增值。
select seq_student.currval from dual; //获取当前序列值,必须在使用nextval获取过之后使用。
//使用sequence自动生成序列值作为主键
insert into t_student(s_id,s_name,sex,borndate,age,c_id)
values(seq_student.nextval,'aaa',1,to_date('1990-01-01','yyyy-mm-dd'),19,46);
注:drop sequence 序列名; //删除序列
2. 视图:
I. 语法:create view 视图名 as select......
II. 详解:保存SQL语句的虚表,简化查询。(如方法调用)
III. 用例:
//查询员工信息(编号、名字、薪资、部门名称)
create view v_emp as //附加 //不能并行使用*作为列名,如:e.*, d.*
select e.employee_id , e.first_name , e.salary , d.department_name
from employees e inner join departments d on e.department_id = d.department_id;
//查询编号是203的员工信息(编号、名字、薪资、部门名称)
select * from v_emp where employee_id = 203;
注:视图不会独立存储数据,原表发生改变,视图也发生改变。没有优化任何查询性能。
drop view 视图名; // 删除视图,不会影响原表数据。
grant create view to hr; //授权给...
revoke create view from hr; //撤销自...
3. 索引:
I. 语法:create index 索引名 on 表(列)
II. 详解:索引类似与字典的目录,用于加快数据检索的速度。
III. 用例:
//为员工表的薪资列创建索引
create index emp_salary_ix on employees(salary); //Oracle自动使用查询引擎检索。
//为学生表的姓名创建索引
create index stu_name_ix on t_student(student_name);
注:
1).查询频率较高的字段,可以创建索引来提高查询效率,一个字段只能有一个索引。
2).索引并非创建的越多越好(占用存储空间,增删改的同时需要维护索引,消耗内存、CPU),提高查询速度,降低了增删改效率。
3).Oracle默认在主键和唯一键上自动创建索引。
drop index 索引名; //删除索引