Hadoop(二)–全分布式安装、hadoop 高可用
一. 全分布式安装
当重置后,不一定要进行删掉。可以把clusterID和name的id保持一致。

伪分布式是把所有的角色进程放在node06的进程之上,但是全分布式应该是不同的节点的一个分发。

之前的搭建是所有的角色进程在同一个节点hadoop0上, 真实的应该namenode单独部署一台服务器。
- 所有环境都要有jdk;
通过jps来查看 - 同步所有服务器的时间;;
查看别名:cat /etc/hosts,互相有映射ip地址才可以ping通;
cat /etc/sysconfig/selinux检查是否是关闭状态;

全分布式的免密登录一定要有:谁是主节点,谁是管理节点,谁就要分发自己的密钥文件。
免密登录涉及到一个主节点和其他三台从节点的免密;
第一步:先回到home目录,看是否有隐藏文件。(没有则需要创建)
cd
ll -a
查看是否有.ssh文件
第二步:进入到.ssh文件目录下,通过分发命令进行分发;
在node06的服务器上:
cd .ssh/
scp id_dsa.pub node07:`pwd` /node06.pub
node06是主节点,node07是要被分发的节点;
在node07的服务器上:
cd .ssh/
cat node06.pub >> authorized_keys

有了公钥后就意味着:在node06的服务器上,可以通过ssh node07来实现免密钥登陆。

有了这个基础,就可以搭建全分布式了。如果之前没有搭建伪分布式的话,需要先对hadoop-env.sh进行修改,没有的话会提示JVM not found。
需要修改core-site.xml:

另外需要对hdfs-site.xml进行修改:

需要对slaves进行修改,对从节点进行配置:
如果不慎将06放在第一行的位置,即主从节点放在了一起,那么需要做的操作就是转移。把DataNode进行转移。
分发操作:
先看每台服务器是否有相同的目录。
再把对应的文件见进行分发。
scp -r stx/node07:pwd``

细节:在哪块配置环境变量。到目前为止是node06,需要把环境变量都配置成功。
通过scp来实现profile环境变量的分发:
scp /etc/profile node07:/etc/

现在就满足启动集群的基本条件了,但是在启动集群时,要先进行节点的格式化操作。
在hadoop0(node06)上执行:hdfs namenode -format,进行格式化。格式化的作用就是把文件存储在core-site.xml中定义的full文件的位置处。
格式化只是对主节点设置,其他节点无。启动时其他节点才会有。
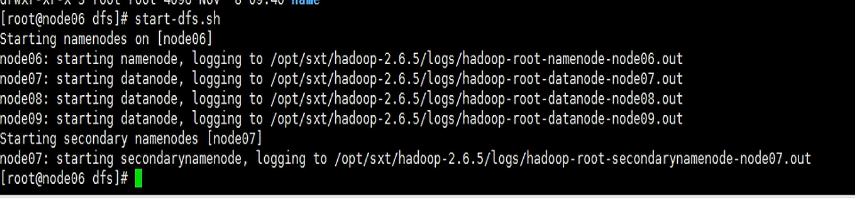
进入到full的文件夹,cd /var/sxt/hadoop/full/dfs通过start-dfs.sh来进行启动。启动完成后,通过jps来查看节点启动情况,
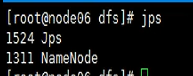
在主节点上(hadoop0或者node06上),只有namenode;
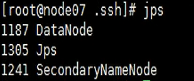
假定其中一个namenode出问题了,该怎么办?
- 看日志,日志在
/hadoop-2.7.4/logs下,主节点只有namenode的日志(hadoop0或者node06),datanode的日志在其他节点上。(hadoop1,hadoop2,hadoop3) - 查看日志的倒数100行:
tail -100 hadoop-root-datanode-hadoop1.log - 文件上传时,切割得时候是严格的来切割的。
hdfs dfs -D dfs.blocksize=1048576 -put test.txt
二. 高可用

hadoop1中namenode是最别扭的:一个namenode要掌控多个datanode,它是单一的管理节点,管理整个集群。一旦namenode挂断后,整个集群会造成不可用的现象。
上述是单点故障问题。namenode维护元数据信息,与磁盘不发生交互,假设集群达到了很大的规模,而单点在控制和维护大集群的数据量,有可能会造成单点的能力有限,限制了整个集群发挥的作用。这叫做单点瓶颈问题。

F–Federation 联邦;
HA–high availability
HA–可以一变多,由多个主节点提供服务,不是同时提供。只是提供一个备用的方式。当主挂断后,备用的才顶上来,避免由于单点的宕机造成整个集群的宕机。
F–多个主节点同时提供服务,是为了扩充namenode的能力来存在的,所谓联邦。

2.0的主从架构模型图:

上面完成了自动切换,下面完成了手动切换。自动搭建时会用到zookeeper的框架,来协调规划。
两个namenode节点,另一个要想顶替其中一个,需要数据同步。同步原数据信息,其实就是对下面不同数据块的描述。
block块数据叫动态,偏移量之类叫静态。
同步是采用两种方式的,静态和动态方式不同。
为什么叫动态–因为是datanode向namenode来汇报。datanode现在向两个namenode同时汇报,动态块信息由单一汇报变为了多方汇报,namenode两个之间可以把元数据同步。
关键是静态同步如何同步?
socket通信,硬编码方式。但是这种方式需要ack确认机制,需要给一个反馈,面临一个两难的问题,确认与否。如果机器坏了,那么就无法确认。这就叫做强一致性。这引起了单点阻塞的角色。
客户端角色只和active的namenode保持联系。
hadoop怎么做?–edits写在日志文件,通过namenode来确认。(之前)
让新服务器存储当前的日志文件,(客户端对其操作命令),然后另一个namenode从日志中往外读,通过这样的方式实现同步。这叫nfs。
这种处理方式的弊端在于–仍然有单点故障的问题,于是衍生出了journalnode技术。
提供日志服务器集群节点,帮助完成集群服务器同步数据的操作。三台服务器同时接受日志文件,三台服务器接收的一样。为什么要三台接受相同的内容,担心会坏掉,这样就做了一个保险的工作。
多台服务器的原因:怕其中一个挂断。但是多台服务器可能出现的情况:有无必要让三台服务器全都确认接受成功?强一致性在关系数据库是可以的,在集群中是不可行的。
故一旦三个其中一个坏掉了,就需要有一个容忍下限。允许一台关掉(3台)。一般都搭奇数集群。弱一致性。
涉及到了cap定理。
Activate把数据存到集群中,Stabdy把数据给同步(做持久化操作),无需secondarynode。
数据分为两部分:datanode如何进行两个节点的同步;静态的元数据信息怎么来进行同步。通过journalnode的集群实现消息的上传和下载。
手动切换
自动切换
必须依赖zookeeper集群,分布式的一个协调系统。协调其他大数据集群的运行状态。
在其中起到核心的管理作用。
zookeeper做分布式协调最好的架构。
zookeeper会在每一个namenode上开辟一个物理进程,这个物理进程叫:FailoverController,故障转移控制进程。
zookeeper怎么来完成相应的主从的一个切换?开始时,namenode都处于非故障状态,zookeeper提供了一个选举机制,每个namenode都向zookeeper申请,谁先注册,谁来作为主节点。
zookeeper理解为小型数据库,意义是帮助协调,注册了一个节点或者是创建了一个节点路径znode。
在路径之下,会有相关的该节点的注册信息。zookeeper维护性能通过父子目录树来做,注册好了,就是意味着主节点在维护。
注册–创建节点,在zookeeper集群当中。
事件监控–zookeeper和namenode时刻保持联系,通过zkfc保持联系。节点突然宕机,zkfc进程开辟两个组件:healthmo,选举机制。zkfc随时随地监控namenode的健康状态。义务就是:让他参加选举和监控健康状态。
发现问题后,zk就获知了事件,通知standby节点。从节点委托zk来监控事件发生。zk集群捕获到事件告知从节点,从节点做的事情就是想篡权,把自己注册上来,自己作为主节点。这种行为叫函数的回调。
函数回调的是每一个客户端的函数。
注册节点创建、通知行为。
zookeeper会维持这样的一种操作:
- 当注册成功后,zkfc进程会随时随地观察健康主节点状态;
- 一旦发现不健康了,通过举机制告知zookeeper其选举人的身份发生改变;
- 节点发生事件后,zookeeper通知standby,standby把自己当作activate;(但现在还不能直接进行改变)
- standby强制性让active变为standby,再把自己变为activate;
同一时刻只能允许一个activate。

联邦

如图,3个namenode同时在并行,底层的datanod分工好像下面的存储模型。
联邦起到的作用:
假定namenode节点的内存数据量有限,但是底层数据量又非常庞大,这时单节点的局限性显现。
联合i形式一:
为什么需要联邦:集群不平衡。多个namenode节点并行工作,共同利用底层的存储空间。
联合形式二:
增加namenode节点,原有的内存空间不扩充;
联合i形式三:
datanode不够用,需要多个namenode来以联邦的形式运作进行管理。
第一个例子是每个namenode干不同的业务,把存储空间给合并;第三个是大家干的是一个业务;
(记着老板分主机的场景)

namenode节点多的话,这样做对客户来说还会有一个弊端:需要来记住哪个namenode来做的事情。
这样的弊端企业中常常会有这样的解决方案:提供NameNode联邦方式存储的基础之上,在上层提供一个服务平台接口。接口机制对操作进行一个分类:客户端和服务平台联系,先找到平台针对大数据的接口,由这些接口来完成下面datanode的分类存储。

还有个问题:服务器有宕机风险,从横向角度而言,提升了服务器集群的横向扩充存储能力。故垂直的角度,每一个机器都要做一个高可用。高可用的目的是同步主节点的信息。

联邦的搭建不作为重点。namenode存储的数据是metadata数据,放的都是偏移量之类的信息。
搭建HA高可用集群
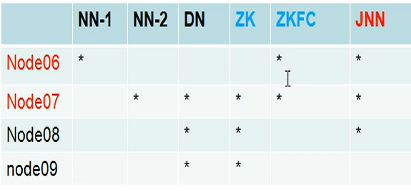
两个namenode节点之间要实现自动切换的功能。故node06和node07之间要有一个免密钥的操作。
密钥生成器:
追加到自己文件中。

将其分发到node06的当前目录下:(改个名,避免覆盖)

nameservices表示一个逻辑name,需要关联到配置的节点信息。
高可用搭建理论
2.0版本主要解决了1.0版本的单点故障问题,通过高可用HA和联邦的方式。


读文档;
nameservices:
先加载到hdfs中;
dfs.namenode.rpc-address 来通过远程服务调用,找到物理机的位置。
dfs.namenode.http-address:给浏览器提供服务,让浏览器访问这个集群。
dfs.namenode.shared.edits.dir:
dfs.ha.fencing.methods:表示状态隔离的含义。这个东西的配置当存活节点出现故障时将其隔离开。
举例:有两个节点,一个是ann,一个是sbnn。当ann发生故障时,选举机制就会通知zookeeper集群,zookeeper会封装这个事件,交给sbnn。sbnn拿到后不是简单的把自己做一个提升,而是先强制的转换ann的状态,让其作为一个非活动节点。
这个转换就是dfs.ha.fencing.methods的作用。
私钥操作涉及到哪个文件–id_dsa。
命令就是:生成密匙文件,然后追加到author的文件中。
fs.defaultFS:namenode主节点,修改的是core-site文件。

zookeeper是游离于整个系统之外的,并不是必备的。启动和关闭和当前集群的启动关闭无关。
在zookeeper集群中,每一个nameNode都会有一个会话session和其绑定。
web开发中session作为访问者的唯一标识,http协议是无状态协议,上次访问下次一定不知道。为了解决它,服务器提供session,交给客户端的cookie来维护,从而达到区别的面对。
每一个namenode节点,其会在zookeeper中注册,而每一个namenode都对应了一个持久化的session。session有生命周期的问题,一旦节点和集群之间发生了联系中断之后,与之绑定的node节点也随之被销毁掉了。
zookeeper:第一允许你注册,第二回调监控,第三事件函数。回调的是客户端的函数,其实回调的是zkfc的函数。
zkfc保持和监控namenode的状态。
zookeeper单独集群,要跑在3-5个节点之上。要切断cluster。hdfs-site中加入参数配置。完成自动的故障转移。
zookeeper要求集群搭建开始时有一个信息,就是有几台服务器参与了集群的搭建。第二要求把每台服务器提供服务器的编号,即serverid。涉及到zookeeper的选举机制。既然是主从架构,开始时就要确定谁是主,同时启动时,谁编号最大就是主。

接着就开始分发。