模板参数传递的区别(针对于函数模板的自动类型推导)
按值传递
按值传递的后果是:导致函数模板的自动类型推导退化(decay),何为退化,下面就让我仔细的说一下:
① 按值传递会导致传入参数失去const和volatile属性:
#include <iostream>
using namespace std;
template <typename T>
void ShowInf(T obj)
{
cout << typeid(T).name() << endl;
}
int main()
{
const int a = 10;
ShowInf(a);
}

我们看到,函数形参的类型与我们传入的实参类型不一致,去掉了const常量属性。
为什么要用volatile关键字?
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改。比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
声明时语法:volatile int vInt;
当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。例如:
volatile int i=10;
int a = i;
int b = i; volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在 b 中。而优化做法是,由于编译器发现两次从 i读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在 b 中。而不是重新从 i 里面读。这样以来,如果 i是一个寄存器变量或者表示一个端口数据就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。
下面通过插入汇编代码,测试有无 volatile 关键字,对程序最终代码的影响:
#include <stdio.h>
void main()
{
int i = 10;
int a = i;
printf("i = %d", a);
// 下面汇编语句的作用就是改变内存中 i 的值
// 但是又不让编译器知道
__asm {
mov dword ptr [ebp-4], 20h
}
int b = i;
printf("i = %d", b);
} 然后,在 Debug 版本模式运行程序,输出结果如下:
i = 10
i = 32 然后,在 Release 版本模式运行程序,输出结果如下:
i = 10
i = 10 输出的结果明显表明,Release 模式下,编译器对代码进行了优化,第二次没有输出正确的 i 值。下面,我们把 i 的声明加上 volatile 关键字,看看有什么变化:
#include <stdio.h>
void main()
{
volatile int i = 10;
int a = i;
printf("i = %d", a);
// 下面汇编语句的作用就是改变内存中 i 的值
// 但是又不让编译器知道
__asm {
mov dword ptr [ebp-4], 20h
}
int b = i;
printf("i = %d", b);
} 分别在 Debug 和 Release 版本运行程序,输出都是:
i = 10
i = 32 这说明这个 volatile 关键字发挥了它的作用。其实不只是“内嵌汇编操纵栈”这种方式属于编译无法识别的变量改变,另外更多的可能是多线程并发访问共享变量时,一个线程改变了变量的值,怎样让改变后的值对其它线程 visible。一般说来,volatile用在如下的几个地方:
1) 中断服务程序中修改的供其它程序检测的变量需要加volatile;
2) 多任务环境下各任务间共享的标志应该加volatile;
3) 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义。
② 按值传递会导致传入参数失去引用属性:
#include <iostream>
using namespace std;
template <typename T>
void ShowInf(T obj)
{
cout << typeid(T).name() << endl;
}
int main()
{
int b = 10;
int& a = b;
ShowInf(a);
}
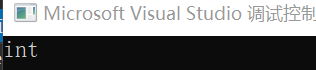
③ 按值传递会导致传递的数组退化成指针:
#include <iostream>
using namespace std;
#include <string>
#include <type_traits>
template <typename T>
void ShowInf(T obj)
{
cout << typeid(T).name() << endl;
cout << "is array:" << is_array<T>::value << endl;
}
int main()
{
char ch[] = "111";
ShowInf<>(ch);
ShowInf<char[]>(ch);
}
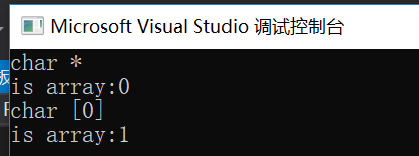
我们看到,当使用显式类型的时候,传入的ch数据是数组的首地址,我们可以在函数内部判断出这个传入参数是函数的首地址,但是当使用隐式类型转换,即自动类型推导时,在函数内部这个指针就是一个普通的指针。
按引用传递
#include <iostream>
using namespace std;
#include <type_traits>
#include <any>
template <typename T>
void ShowInf(T& obj)
{
if (is_const<T>::value)
{
cout << "const int &" << endl;
}
}
int main()
{
const int obj = 10;
ShowInf(obj);
} 这里,我们按照引用传递一个const int&的变量,因此此时的模板T&是const int&,即T为const int类型,我们要注意的是T是const int并非const int&。我们看到当使用T&进行隐式类型推到时,可以正确地推导出数据的类型。
#include <iostream>
using namespace std;
#include <type_traits>
#include <any>
template <typename T>
void ShowInf(T& obj)
{
if (is_array<T>::value)
{
cout << "char[]" << endl;
}
else
{
cout << "char*" << endl;
}
}
int main()
{
char ch[] = "111";
ShowInf(ch);
} 当使用&进行数据类型推导时,可以保留数组指针的特性,不至于退化为普通指针。
注意:
Typeid<T>.name()输出的是const char*数据类型的常量,比如int, const int*等, 但是遗憾的是这种方式输出不了const int&:
#include <iostream>
using namespace std;
#include <type_traits>
#include <any>
template <typename T>
void ShowInf(T& obj)
{
cout << is_const<T>::value << endl; // 注意:这里的is_const只能判断纯const变量,const int&不是纯const变量
cout << typeid(obj).name() << endl;
}
int main()
{
const int obj = 10;
ShowInf(obj);
}
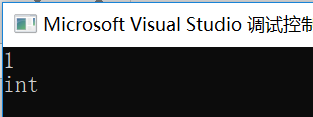
我们从结果看到,这个变量的类型确实是const int&,但是这里却没显示。