一、基本概念
- 串的定义:串是由零个或者多个字符组成的有限序列,串中字符的个数称为串的长度,含有零个元素的串叫做空串。
- 子串:串中任意连续的字符组成的子序列。主串:包含子串的串。子串的第一个字符的位置作为子串在主串的位置。空格串:由一个或者多个空格组成的串。串是限定了元素为字符的线性表。
- 对串中某子串的定位操作称为串的模式匹配,其中待定位子串称为模式串。
二、串的结构
- 定长顺序存储表示结构定义
typedef struct
{
char str[msxSize+1];//maxSize为已经定义的常量,表示串的最大长度,+1是指"\0"
int length;
} Str;
变长分配存储表示
typedef struct
{
char *ch;//指向动态分配存储区首地址的字符指针
int length; //串的长度
} Str;
这种存储方式需要malloc()函数来分配一个长度为length、类型为char的连续存储空间,分配的空间可以用free()函数释放掉。用malloc()函数来分配存储空间,如果成功,则返回一个指向起始地址的指针,作为串的基地址,如果分配失败,则返回NULL。
三、 串的基本操作
- 赋值操作–对数组中每个元素进行逐一赋值操作strassign()
int strassign(Str& str,char *ch)
{
if(str.ch)
free(str.ch);//释放原来的空间
int len=0;
char *c=ch;
while(c)
{
len++;
c++;
}
if(len==0)
{
str.ch=NULL;
str.length=0;
return true;
}
else
{
str.ch=(char)malloc(sizeof(char)*(len+1));//多一个用于存放\0
if(str.ch==NULL)
return false;
else
{
c=ch;
for(int i=0;i<=len;i++,c++)//\0也被存入str.ch
str.ch[i]=*c;
str.length=len;
return true;
}
}
}
- 取串长度操作
int strlength(Str str)
{
return str.length;
}
- 串比较操作–串排序中的核心操作
int strcompare(Str s1,Str s2)
{
for(int i=0;i<s1.length&&i<s2.length;i++)
if(s1.ch[i]!=s2.ch[i])
return s1.ch[i]-s2.ch[i];
return s1.length-s2.length;
}
- 串连接操作–将两个串首尾连接在一起,合并成一个新的字符串
int concat(Str& str,Str s1,Str s2)
{
if(str.ch)
{
free(str.ch);
str.ch=NULL;
}
str.ch=(char*)malloc(s1.length+s2.length+1);
if(str.ch==NULL)
return false;
int i=0;
for(;i<s1.length;i++)
str.ch[i]=s1.ch[i];
int j=0;
for(;j<=s2.length;j++)//注意此处为<=,因为要放入\0
str.ch[i+j]=s2.ch[j];
str.length=s1.length+s2.length;
return true;
}
- 求子串操作
int substring(Str& substr,Str str,int pos,int len)
{
if(pos<0||pos>str.length||len<0||len>str.length)
return false;
if(substr.ch!=NULL)
{
free(substr.ch);
substr.ch=NULL;
}
if(len==0)
{
substr.ch==NULL;
substr.length=0;
return true;
}
else
{
substr.ch=(char*)malloc(sizeof(char)*(len+1));
int i=pos;
int j=0;
while(i<pos+len)
{
substr.ch[j]=str.ch[i];
++i;
++j;
}
substr.ch[pos+len]=NULLL;
substr.length=len;
return true;
}
}
- 串清空操作
int clearstring(Str& str)
{
if(str.ch)
{
free(str.ch);
str.ch=NULL;
}
str.length=0;
return true;
}
四、串的模式匹配算法
- 一种简单的模式匹配算法
int index(Str str,Str substr)
{
int i,j,k;
i=0,j=0,k=i;
while(i<str.length&&j<substr.length)
{
if(str.ch[i]==substr.ch[j])
{
++i;
++j;
}
else
{
j=0;
i=++k;
}
}
if(j==substr.length)
return true;
else
return -1;
}
- KMP算法
- 通过上述简单的模式匹配算法,你可以发现,i的每一次回溯在出现重复的ABABABABAB型时,i按照原来的方式回溯会显得很笨,据此,KMP算法则进行了优化。利用部分匹配这个有效信息,保持i指针不回溯,通过修改j指针,让模式串尽可能的移动到有效的位置,对与ABABABAB型,我们就可以跳过AB部分,直接匹配不同的位置x,要实现该方法,就必须现定义一个NEXT数组,当主串与模式串发生不匹配的情况下,直接将模式串跳到NEXT数组对应的位置即可,从而使主串不需要回溯。
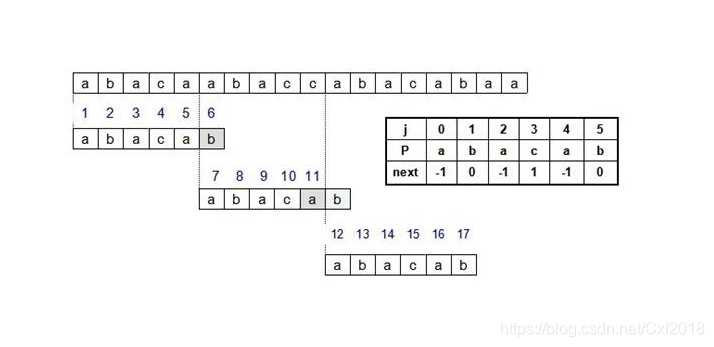
- 整体思路:在已经匹配的前缀当中寻找到最长可匹配后缀子串和最长可匹配前缀子串,在下一轮直接把两者对齐,从而实现模式串的快速移动。
找到最长可匹配后缀、前缀子串:事先缓存到一个集合当中–数组next,用的时候再去集合next中取。
- 对模式串预处理,生成next数组
- 进入主循环,遍历主串
2.1. 比较主串与模式串的字符
2.2.如果发现坏字符,查询next数组,得到匹配前缀所对应的最长可匹配前缀子串,移动模式串到对应的位置
2.3.如果当前字符匹配,继续循环
- 数组next
这个地方好难懂,附上他人讲解KMP的next部分代码
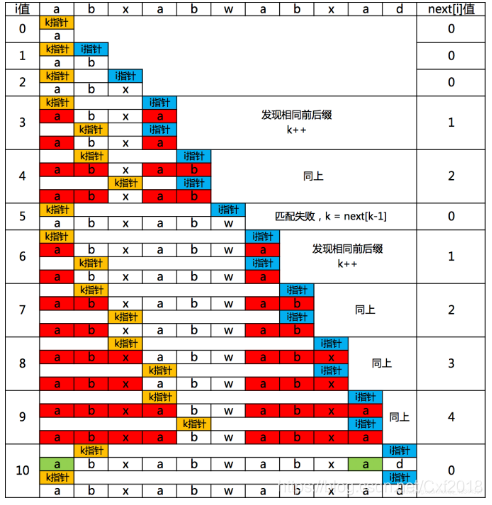
void GetNext(Str str,int *next)
{
next[0]=-1;
int j=0;
int k=-1;
while(j<str.length-1)
{
if(k==-1||str.ch[k]==str.ch[j])
{
k++;
j++;
next[j]=k;
}
else
k=next[k];
}
}
- KMP算法
int KMP(Str str,Str substr,int *next)
{
int j=0;
int i=0;
while(i<=str.length&&j<=substr.length)
{
if(j==0||str.ch[i]==substr.ch[j])
{
i++;
j++;
}
else
{
j=next[j];
}
}
if(j>substr.length)
return i-substr.length;
else
return 0;
}