本文目录
一、实体之间的关系
1.1 一对多(1:N)

1.2 多对一(N:1)

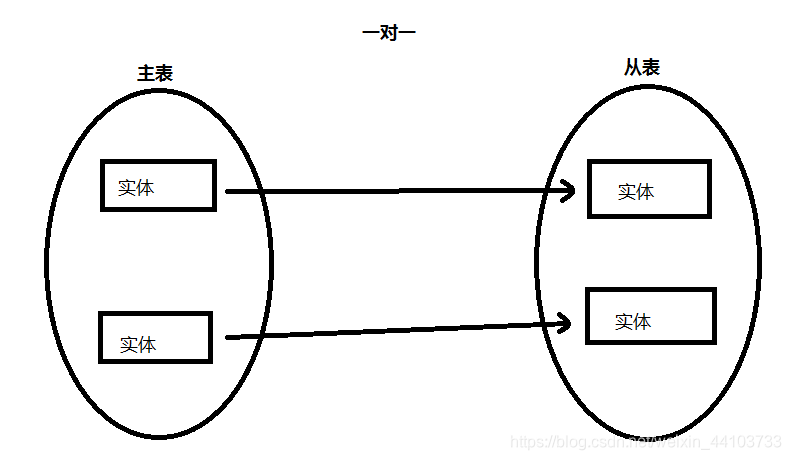
1.3 一对一(1:1)
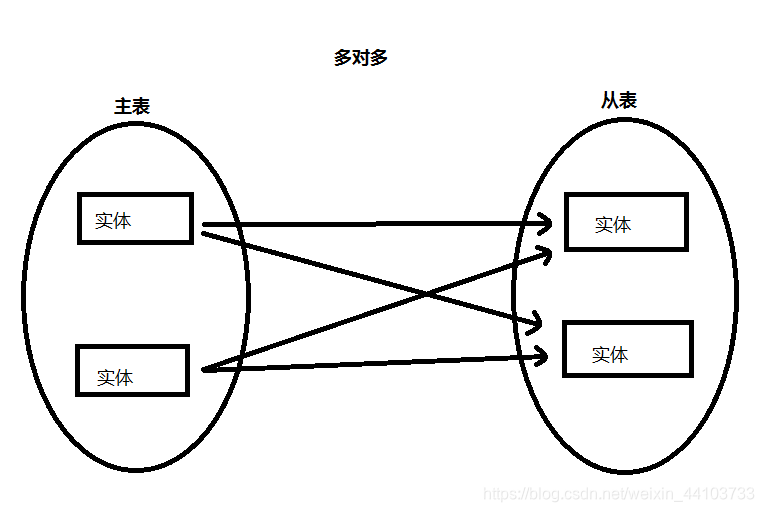
1.4 多对多(N:N)
1.5 小结
实现一对一:主键和主键建关系;
实现一对多:主键和非主键建关系;
实现多对多:引入第三张关系表;
二、数据库设计
2.1 数据库设计步骤
- 收集信息:与该系统有关人员进行交流、充分理解数据库需要完成的任务
- 标识对象(实体 - Entity):标识数据库要管理的关键对象或实体
- 标识每个实体的属性(Attribute)
- 标识对象之间的关系(Relationship)
- 将模型转换成数据库
- 规范化
2.2 数据规范化
-
第一范式:确保每列原则性
第一范式的目标是确保每列的原子性,一个字段表示一个含义 -
第二范式:非键字段必须依赖于键字段
第二范式在满足第一范式的前提下,要求每个表只描述一件事情 -
第三范式:消除传递依赖
第三范式在满足第二范式的前提下,除了主键以外的其他列消除传递依赖 -
反三范式
范式越高,数据冗余越少,表越来越多,但是效率又是就越底下为了提高运行效率,可以适当让数据冗余。
2.3 例题
需求:
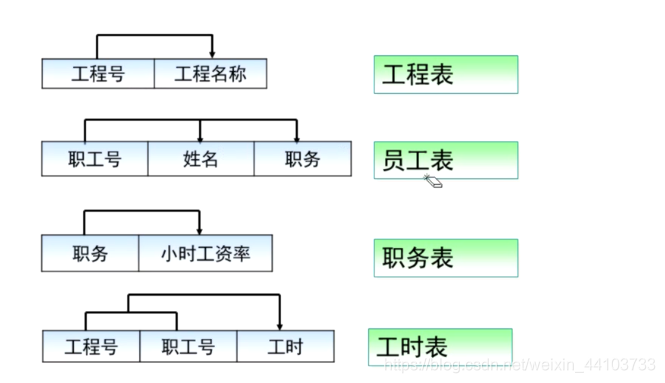
假设某建筑公司要设计一个数据库,公司的业务规则说明如下:
- 公司承担多个工程项目,每一项工程有:工程号、工程名称、施工人员等。
- 公司有多名职工,每一名职工有:职工号、姓名、性别、职务。
- 公司按照工时和小时工资率支付工资,小时工资率由职工的职务决定
标识实体:
- 工程;
- 职工;
- 工时;
- 小时工资率;
共有四个表:
三、查询语句
语法: select [选项] 列名 [from 表名] [where 条件] [group by 分组] [order by 排序] [having 条件] [limit 限制]
测试代码:
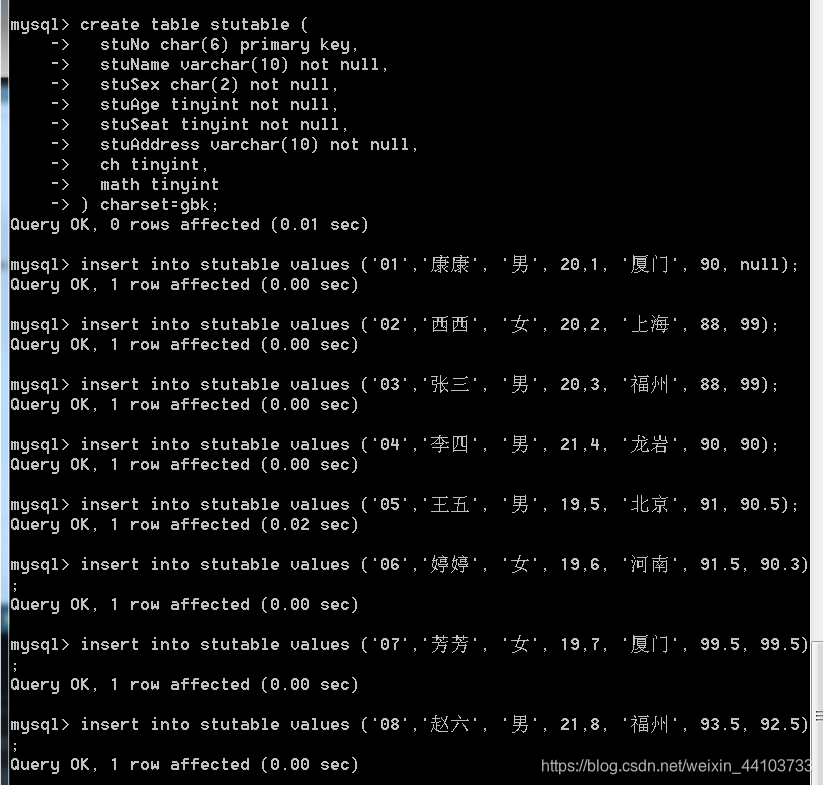
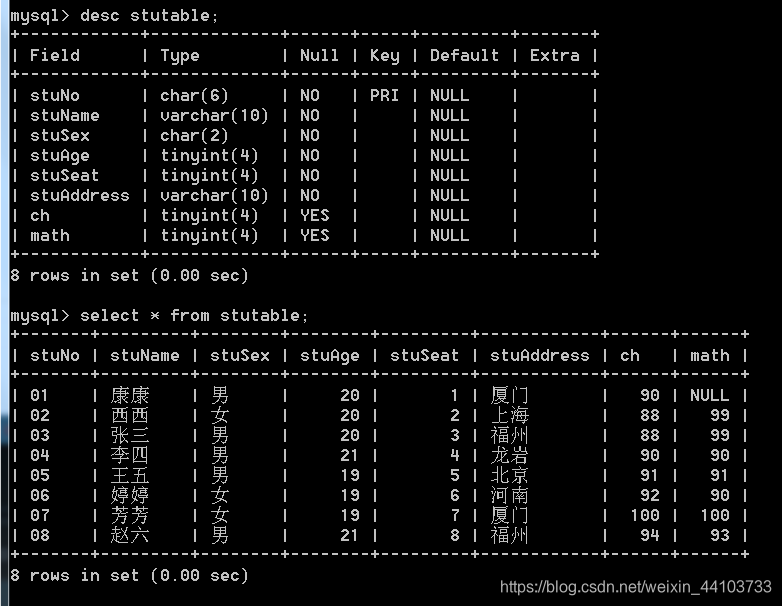
create table stutable (
stuNo char(6) primary key,
stuName varchar(10) not null,
stuSex char(2) not null,
stuAge tinyint not null,
stuSeat tinyint not null,
stuAddress varchar(10) not null,
ch tinyint,
math tinyint
) charset=gbk;
insert into stutable values ('01','康康', '男', 20,1, '厦门', 90, null);
insert into stutable values ('02','西西', '女', 20,2, '上海', 88, 99);
insert into stutable values ('03','张三', '男', 20,3, '福州', 88, 99);
insert into stutable values ('04','李四', '男', 21,4, '龙岩', 90, 90);
insert into stutable values ('05','王五', '男', 19,5, '北京', 91, 90.5);
insert into stutable values ('06','婷婷', '女', 19,6, '河南', 91.5, 90.3);
insert into stutable values ('07','芳芳', '女', 19,7, '厦门', 99.5, 99.5);
insert into stutable values ('08','赵六', '男', 21,8, '福州', 93.5, 92.5);
3.1 字段表达式
可以直接输出内容:


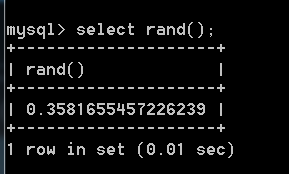
可以输出mysql自带的一些函数,例如随机数rand():
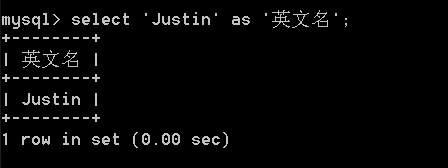
可以通过as给字段去别名:

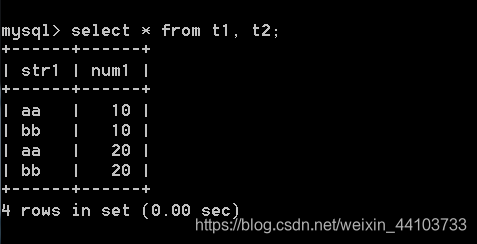
3.2 from子句
from:来自,from后面跟的是数据源。数据源可以有多个,返回笛卡尔积。
插入测试表:
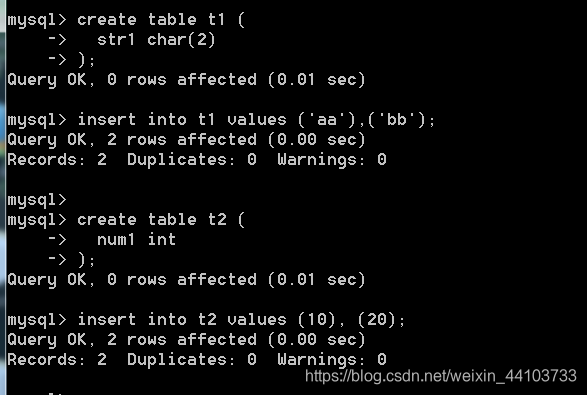
测试多个数据源:
多个数据源返回笛卡尔积:
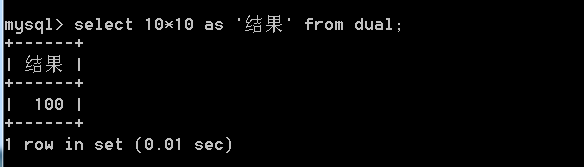
3.3 dual表
dual表是一个伪表,在有些特定情况下,没有具体的表的参与,但是为了包装select语句的完整又必须要一个表名,这时候就使用伪表。
3.4 where子句
where后面跟的是条件,在数据源中进行筛选。返回条件为真记录。where后面跟着是条件语句,如果为真则返回,例如where 1将会把所有记录返回,where 0 则一条都不会返回。
| MySQL支持的运算符 | 含义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| = | 等于 |
| != | 不等于 |
| and | 与 |
| or | 或 |
| not | 非 |
| in 、not in | (不在)在 |
| between and 、 not between and | (不)在什么的什么之间 |
| is null 、 is not null | (不)是为空 |
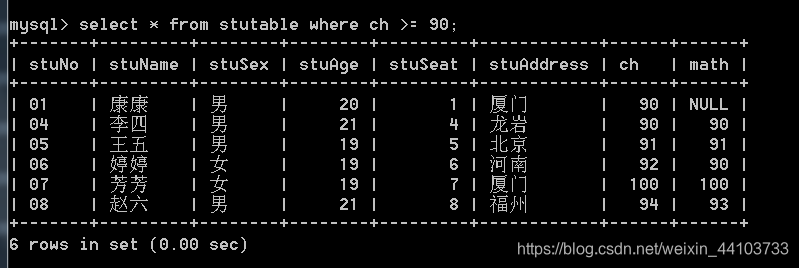
例题:
- 查找语文成绩高于90的学生:
- 查找语文和数学都高于90的:

- 查询语文或数学低于90分的同学:
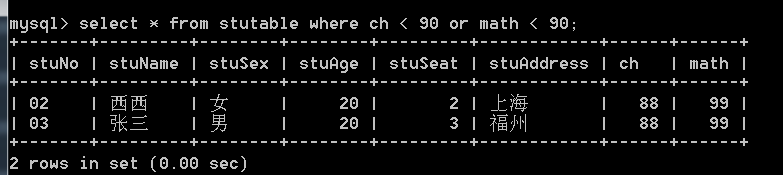
- 查找厦门的学生(sql语句不区分大小写):
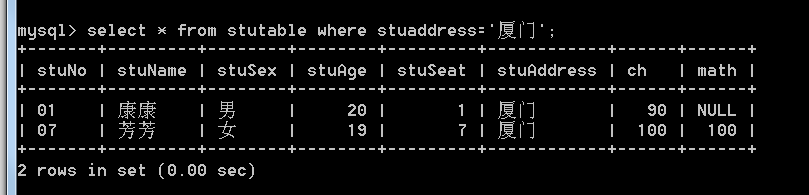
通过in:
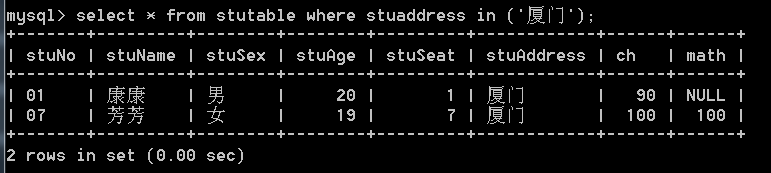
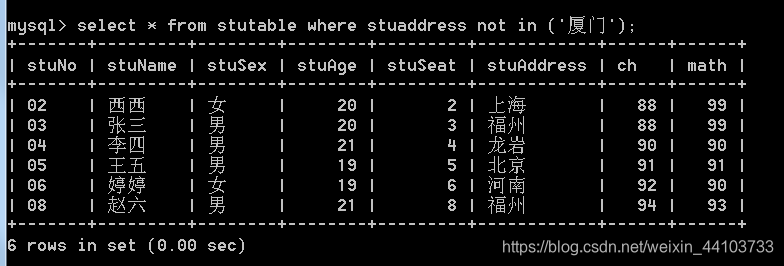
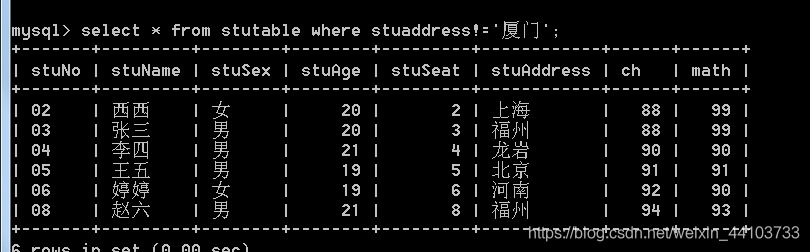
- 查找不是厦门的学生(sql语句不区分大小写):
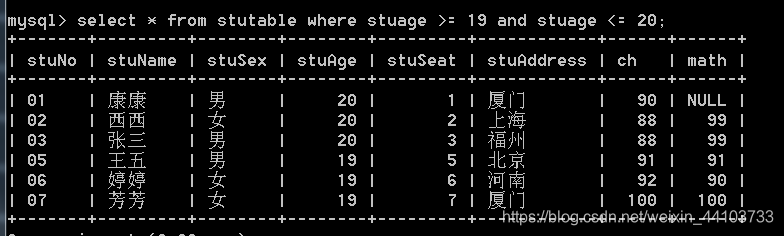
- 查找年龄在19 - 20之间的学生:
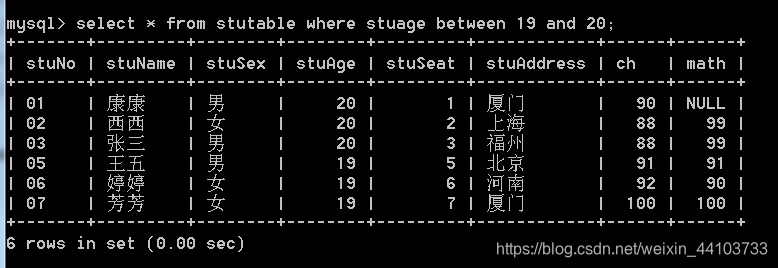
利用between and:
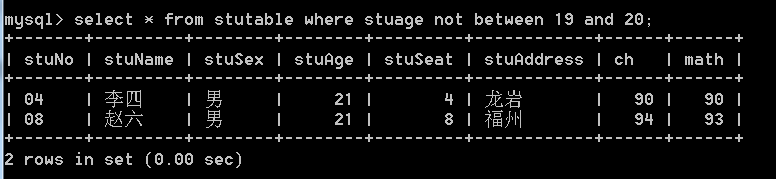
- 查找年龄不在19 - 20之间的学生:
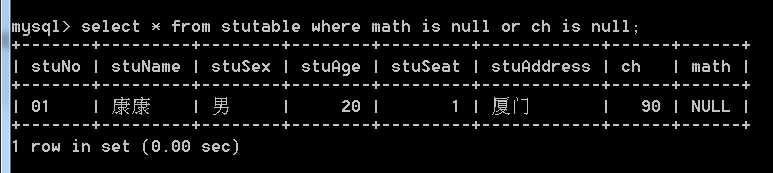
- 查找缺考的学生:
3.5 聚合函数和分组查询(group by)
将查询的结果分组,分组查询目的在于统计数据。
3.5.1 聚合函数
- sum() 求和
- avg() 求平均数
- max() 求最大值
- min() 求最小值
- count() 求记录数
例题:
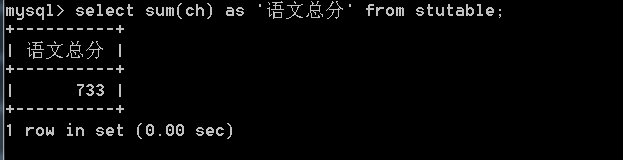
1、求语文总分:
2、求数学最大值:

3、语文平均分:

3.5.2 分组查询
语法:select 分组字段,取值函数 as 别名 from 表名 group by 分组字段;
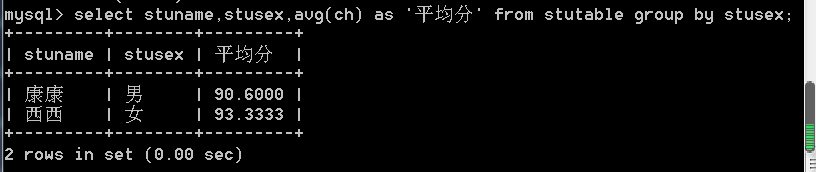
1、查询男生和女生的各自语文平均分:

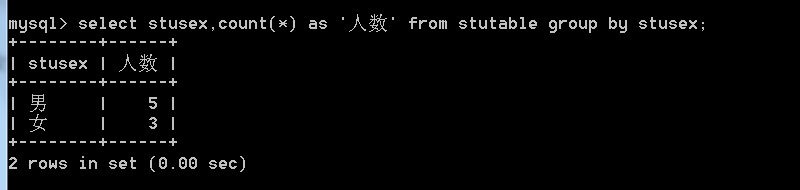
2、查询男生和女生各自多少人:
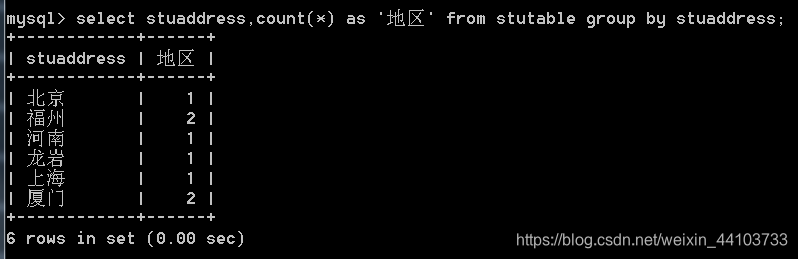
3、查询每个地区有多少人:
4、每个地区的数学平均分:
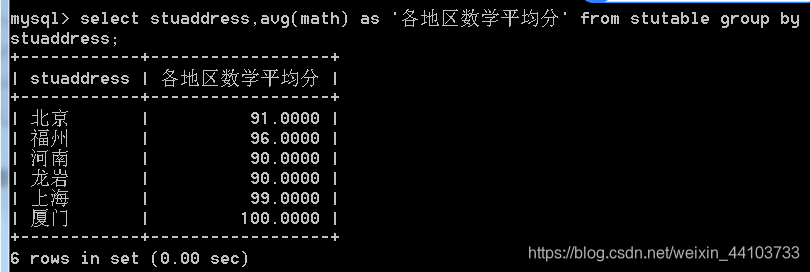
5、如果分组字段中放普通字段:
可以发现只会返回第一项查询到的数据。
总结:
- 如果是分组查询,查询字段必须是分组字段和聚合函数。
- 查询字段是普通字段,只取第一个值。
可以通过group_concat()函数将同一组的值连接起来显示:
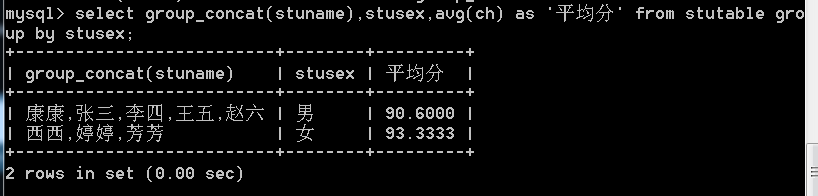
6、多列数组

3.6 排序(order by)
asc:升序(默认)
desc:降序
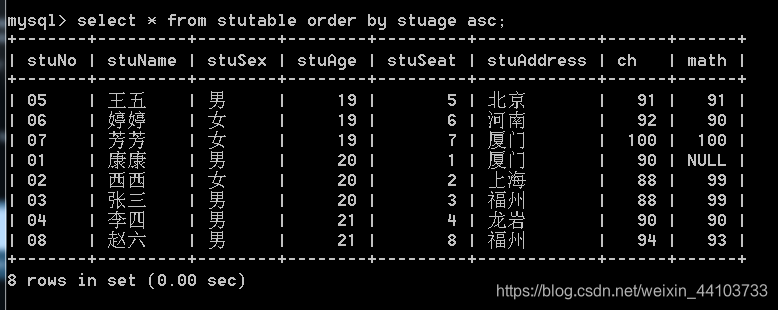
1、按照年龄排序:
降序:

2、按年龄降序,如果年龄一样的按照语文成绩进行降序:
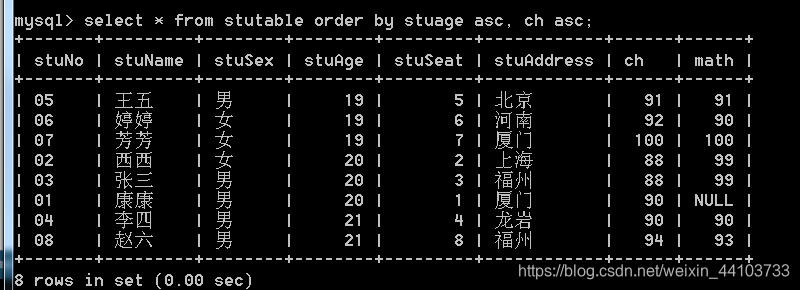
3.7 having条件
having条件就是在结果集上继续进行筛选。
例题:


如上图having报错的原因在于,第一次查询了stuname,而having在stuname的基础去查询stusex,stuname肯定没有stusex所以报错了。
where和having的区别:
where是对原始数据进行筛选,having是对记录集进行筛选。
3.8 limit
语法:limit 起始位置, 显示长度
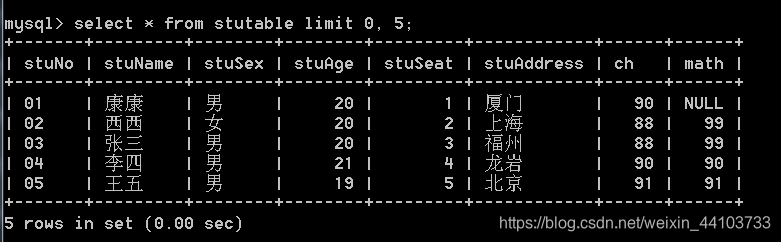
1、找出语文和数学成绩总分前三名:

2、找出总分成绩后三名同学数学成绩加2分:

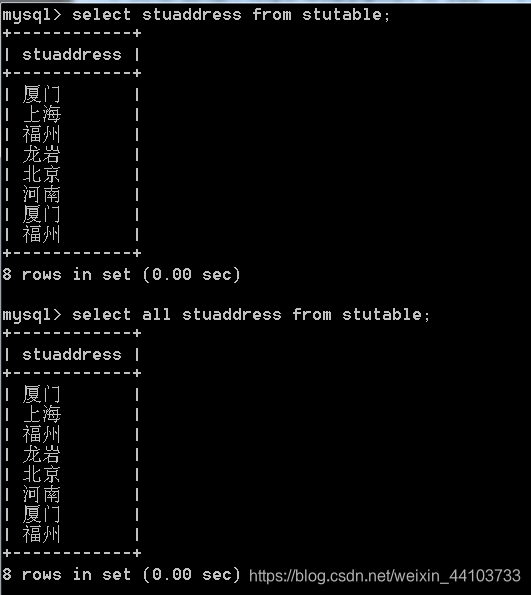
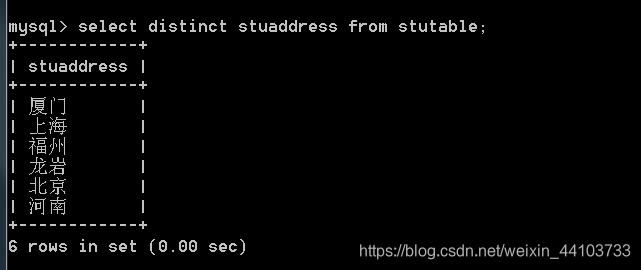
3.9 查询语句中的选项
查询语句中的选项有两个:
1、all:显示所有数据(默认)
2、distinct:去除结果集中重复的数据
例:
四、模糊查询
4.1 通配符
1、_[下划线] 表示任意一个字符
2、% 表示任意字符
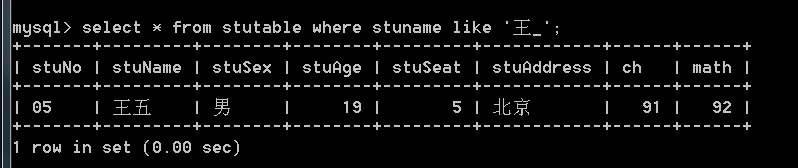
4.2 模糊查询(like)
4.3 联合(union)
将多个表的数据组合到一起
语法: select 语句 from 表1名 union [选项] select 语句 from 表2名 union [选项] select 语句
union的选项也有两个:
1、all:显示所有数据
2、distinct: 去除重复的数据【默认】
union的注意事项:
1、union两边的select语句的字段个数必须是一致的。
2、union两边的select语句的字段名可以不一致,最终按第一个select语句的字段名。
3、union两边的select语句中的数据类型可以不一致。
在学习的MySQL的路上,如果你觉得本文对你有所帮助的话,那就请关注点赞评论三连吧,谢谢,你的肯定是我写博的另一个支持。