前言
一到实习就忍不住想写博客。第一次做Python后端开发,发现不会用pd和np的开发效率实在底下,在这里记录一下。老惯例,只写用过的函数和遇到的错误。
pandas
简介
pandas主攻的是表格的处理,这里最主要的数据结构就是两个:
- Series 相当于1darray

Series有行标签(row labels),没有列标签(column labels) - Dataframe 相当于2darray
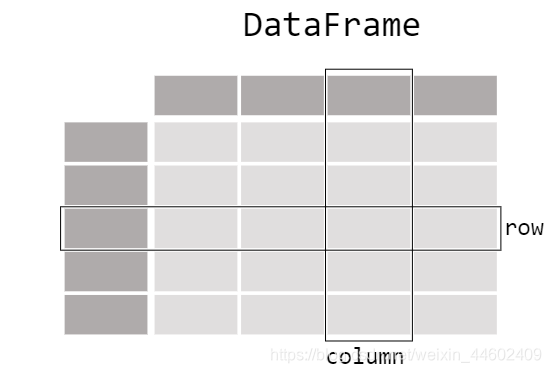
A DataFrame is a 2-dimensional data structure that can store data of different types (including characters, integers, floating point values, categorical data and more) in columns.
注意pandas里的操作基本都是在副本上做的,所以勿忘了将结果赋值给变量!
基本操作
- 获取元素值 / 获取Series
按照字典的方式:df['name']
excel读写
- 读excel,使用
pd.read_excel(path="",sheet_name='Sheet1')
注意读出来的excel与原顺序不一定相同,建议先sort - 写excel,使用
df.to_excel(path="",sheet_name='Sheet1')
排序
- 按值
sort_values(by='column_name')
也可以对多个值进行排序by=['column1','column2']
注意排序并不会改变原dataframe,只是创建了临时的右值!
合并

- 普通合并
df.concat([df_list])
适用于列名相同,纵向合并的情况,可以放在一个列表里无脑直接concat
- 参数详解
df.concat([df_list,axis,join])
将df_list里面的所有dataframe用join的方式在axis轴上进行合并,横向扩展就是 axis = 1
pandas里面的concat并不要求矩阵严格对齐,根据Join方式的不同生成的结果也不同,其逻辑和Mysql Join很相似,等用到了再补充
报错与解决
复现
weight_list = [1,2,3...]
df_weight = pd.DataFrame(weight_list, index=['weight'])
&
df1 = concat([df_list])
pd.concat([df1,df2],axis=1)
# 两者均报错
报错
ValueError: Shape of passed values is (1, 332), indices imply (1, 1)
解决
首先看第一个,pandas documentation中对index的定义
Index to use for resulting frame. Will default to RangeIndex if no indexing information part of input data and no index provided.
扫描二维码关注公众号,回复: 12306717 查看本文章
很明显,index的行数要和value的行数相同,不然会报错
同理,columns的列数要和value的列数相同,这里用column就行
第二个错误是比较tricky了,前面经过一次concat合并后,里面的index其实是混乱的状态,具体原因还未深究,但是print(df1.index)可以看到index并非连续。所以一个良好的习惯是在每次concat后加上reset_index()