- 前言: …
-
1 Windows
- 下载标注工具:windows_v1.8.1.zip 或者网址:添加链接描述
 下载好windows_v1.8.1.zip,并解压,你可以把他放在新建的Data_Mark文件夹下。
下载好windows_v1.8.1.zip,并解压,你可以把他放在新建的Data_Mark文件夹下。
- 在Data_Mark内新建JPEGImages和labels两个文件夹,其中将待标注的图像拷贝到文件夹JPEGImages。
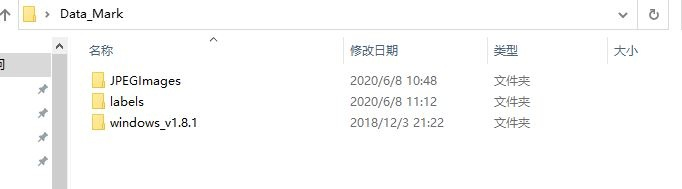
- 运行软件,在目录C:\Users\anlogic\Desktop\Data_Mark\windows_v1.8.1下,你可以直接双击打开labelImg.exe。


- 开始标注之前,你还需要注意这样几点:
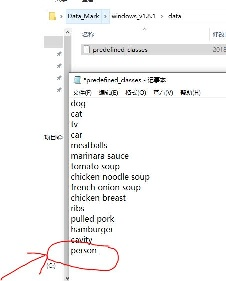
- 更新你需要标注的类别的名称:
C:\Users\anlogic\Desktop\Data_Mark\windows_v1.8.1\data\predefined_classes.txt 里面的名称序号需要和voc.names一致,(保证person的id为14就可以,你可以直接将例子中排在第二的person剪切到最后,修改过之后重启该软件!)。
-
在打开的labelImg.exe,左侧工具栏中,你可以点击Open Dir 按钮选择待标注的图像路径(至JPEGImages)。
。
。

- 标注之前可以勾选标题栏中View下的Auto Save Mode,否则每标注完一张图像需要Ctrl+s一下。
- 为了方便勾选标注名称,可以勾选右侧的Use default label, 并填写类别名称,如person。

- 还有一些快捷键:W改变鼠标状态并开始标注,D下一个,A上一个。
- 标记框需要严格匹配对象的大小。


- 检查生成的标签文件,(参数依次为训练样本的id, center_x_ratio, center_y_ratio, box_width_ratio, box_height_ratio)。

- 标注完成后,删除自动生成的文件:C:\Users\anlogic\Desktop\Data_Mark\labels\classes.txt
2 Linux
-
in C++: https://github.com/AlexeyAB/Yolo_mark
-
in Python: https://github.com/tzutalin/labelImg
3 VOC6_R0
- Head
/AIHOME/data/VOC6_R0/train.txt
/AIHOME/data/VOC6_R0/2007_test.txt
class: person, dog, bicycle, car, tvmonitor, chair
create new dataset train.txt
-
Process
/AIHOME/data/VOC6_R0/README.md
Make new VOC dataset -
structure
‘’’
VOC6
|
—voc # ori dataset
|
—VOCdevkit # new dataset
|
—VOC2007
|
—Annotations
|
—ImageSets # copy from voc
|
—JPEGImages
|
—labels
|
—VOC2012
|
—Annotations
|
—ImageSets # copy from voc
|
—JPEGImages
|
—labels
|
—extract_voc2007.py
|
—extract_voc2012.py
|
voc_label.py
‘’’ -
extract 2007
python extract_voc2007.py
‘’’
delete xml files if no needed class,
delete other class object in the same xml,
to VOCdevkit/VOC2007/Annotations,
to VOCdevkit/VOC2007/JPEGImages,
to VOCdevkit/VOC2007/ImageSets/Main/train.txt & val.txt & test.txt
‘’’扫描二维码关注公众号,回复: 12312584 查看本文章
-
extract 2012
python extract_voc2012.py
‘’’
same ways
Notes: in 2012 dataset XML process, the 2007~2008’s XML files is diff from 2009~2012’s
‘’’ -
create new labels
python voc_label.py
‘’’
create 2007_test.txt,
2007_train.txt,
2007_val.txt
2012_train.txt
2012_val.txt
‘’’ -
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
‘’’
creat train.txt
‘’’ -
for new add dataset, such as 20200612, creat addtrain.txt
python addtrain.py
‘’’
—20200612
|
—JPEGImages
|
—labels
‘’’ -
generate dataset
cat 2007_train.txt 2007_val.txt 2012_*.txt addtrain.txt > train.txt