论文地址:https://arxiv.org/abs/1811.05419v1
github网址:https://github.com/ilovepose/fast-human-pose-estimation.pytorch
全文总结
该论文并未提出啥有意思的东西,总体就是知识蒸馏和“自定义模型压缩”的应用,提供一个思路。
该方法名为 FTD,Fast Pose Distillation,也就是知识蒸馏应用在pose检测上的意思。
文章内容介绍
文中的方法应用对象为Hourglass网络,其有8个stage的hourglass block,每个stage有9个残差块,每个残差块中的channel数为256。作者提出,在depth和width上进行模型的压缩,即压缩后的模型为4个stage的hourglass block,每个残差块中的channel数为128。
其训练“压缩模型”的思路,和传统的知识蒸馏没啥区别,也就是教师-学生模式:(1)先训练一个完整的模型,(2)再训练一个较小的模型。训练目标为教师模型的输出 与 ground-truth,即有两个训练目标,进行加权和(但文中使用的权重为一样的,是通过实验出来的参数)。
Pose检测一般会采用“中间监督”的策略,需要注意的是,文中每个中间监督学习的目标不是对应的stage,而是教师模型的输出,如下图所示;

实验结果
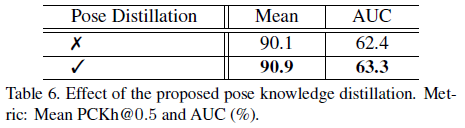
知识蒸馏带来的提升为0.8%(从90.1%到90.9%),实验结果如下:
交叉熵损失函数的尝试,结果并无大区别:

自定义的模型压缩方案,也是尝试出来的:
