引言
当你碰到几个G甚至更大的数据时,如何查看结构化数据的缺失情况呢?总不能用excel表手动肉眼可视化吧?此时,就用到了missingno库
missingno库功能非常强大了!!!
下面展示missingno库的简单实用
代码
# 这个数据有6.19G
import missingno as mg
import pandas as pd
import numpy as np
try:
# 加载数据特别快
dtrain = pd.read_parquet('dtrain.parquet', engine='auto')
except:
dtrain = pd.read_csv('../input/jane-street-market-prediction/train.csv', index_col='ts_id')
# 缩小内存
dtrain = dtrain.astype({
c: np.float32 for c, t in dtrain.dtypes.items() if t == np.float64})
# 转变成parquet格式
dtrain.to_parquet('dtrain.parquet')
print('数据加载完成')
# 缺失值可视化—展示部分
# dtrain表示类型为dataframe的表格,sample(5000)表示抽取表格中5000个样本
mg.matrix(dtrain.sample(5000))
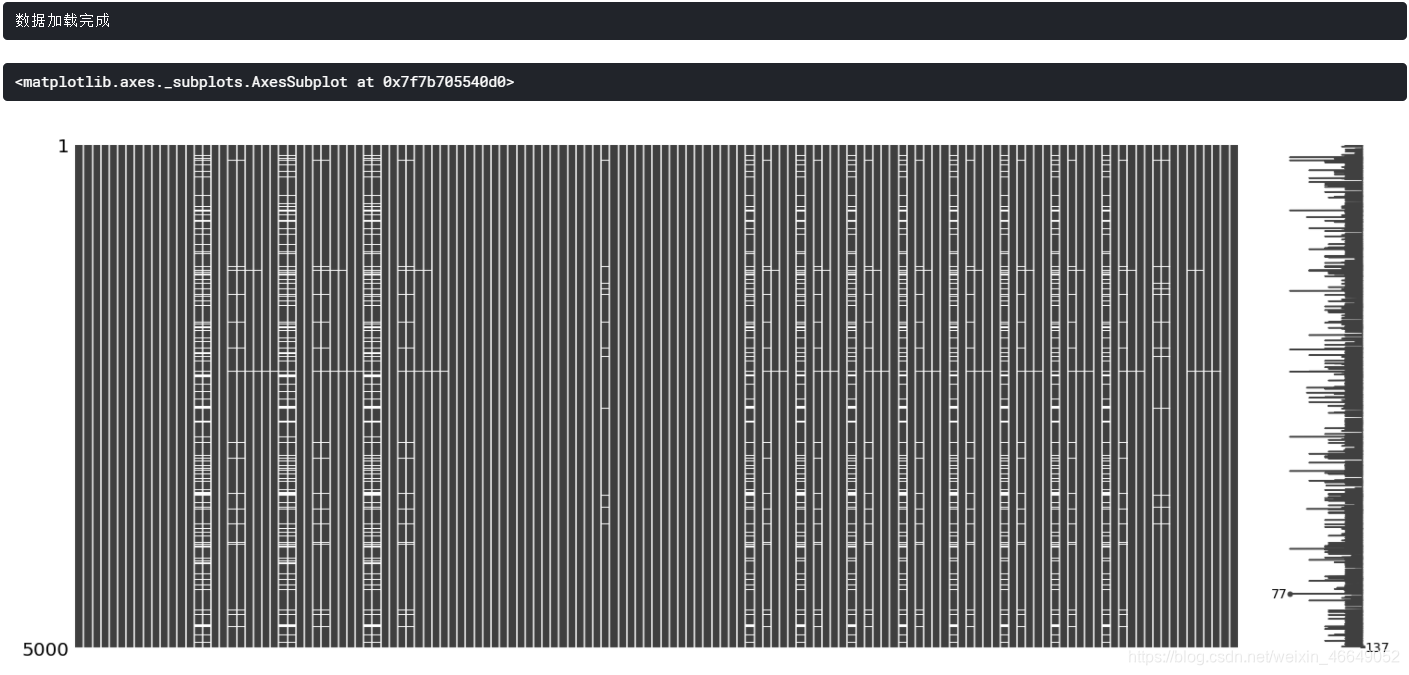
白线越多,代表缺失值越多!!!
生成热力图,来展示特征间的缺失关系
mg.heatmap(dtrain,figsize=(16,16))
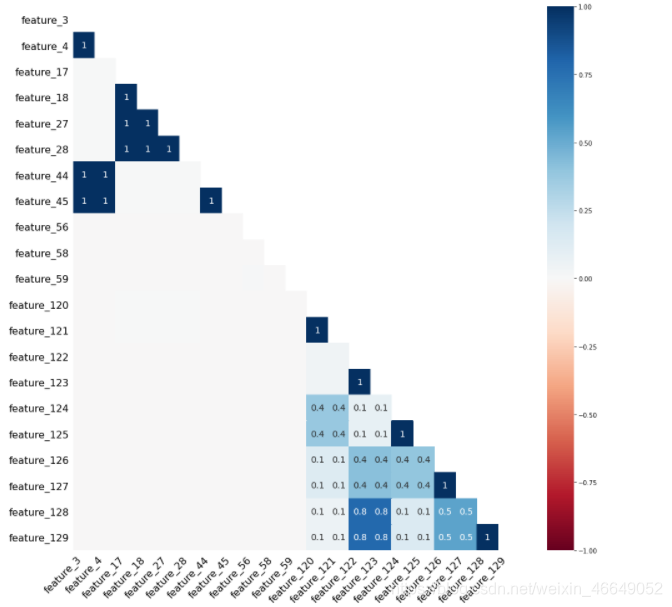
当热度为1时,表明:当某一列特征出现缺失值时,另一列特征一定缺失
# 画组合图
msno.dendrogram(dtrain.iloc[:5000,:])