简介
虽然分布式环境搭建好了,但我想在做API使用前了解一下HBase的工作流程,以便后面写代码的时候对代码的结构更加的了解。
其有如下一些优点:
读写数据快
表按照行键进行了排序,所以查询时可以很快定位
数据切分为多个Region,分布在多个RegionServer中,查询时,多个RegionServer可以一起工作
写的时候完成memorystore写操作即代表完成,读可以先看内存是否命中,如果没有还可以根据索引到磁盘文件中查找
将精彩一起访问的数据放在同一个列族,减少IO开销,减少解压缩时间
安全性
数据是持久化到磁盘文件的
有Hlog存在,支持内存数据丢失后的重做,可以确保数据完整
hdfs的多副本策略可以避免集群出现单节点故障问题

扩展性
基于hdfs可以在廉价机器上横向扩展,提高性能和容量
海量数据
基于列存储,空数据不占用空间,适合存储稀疏数据
高可用
借力zk做集群的分布式协调,保证其可用性
系统架构
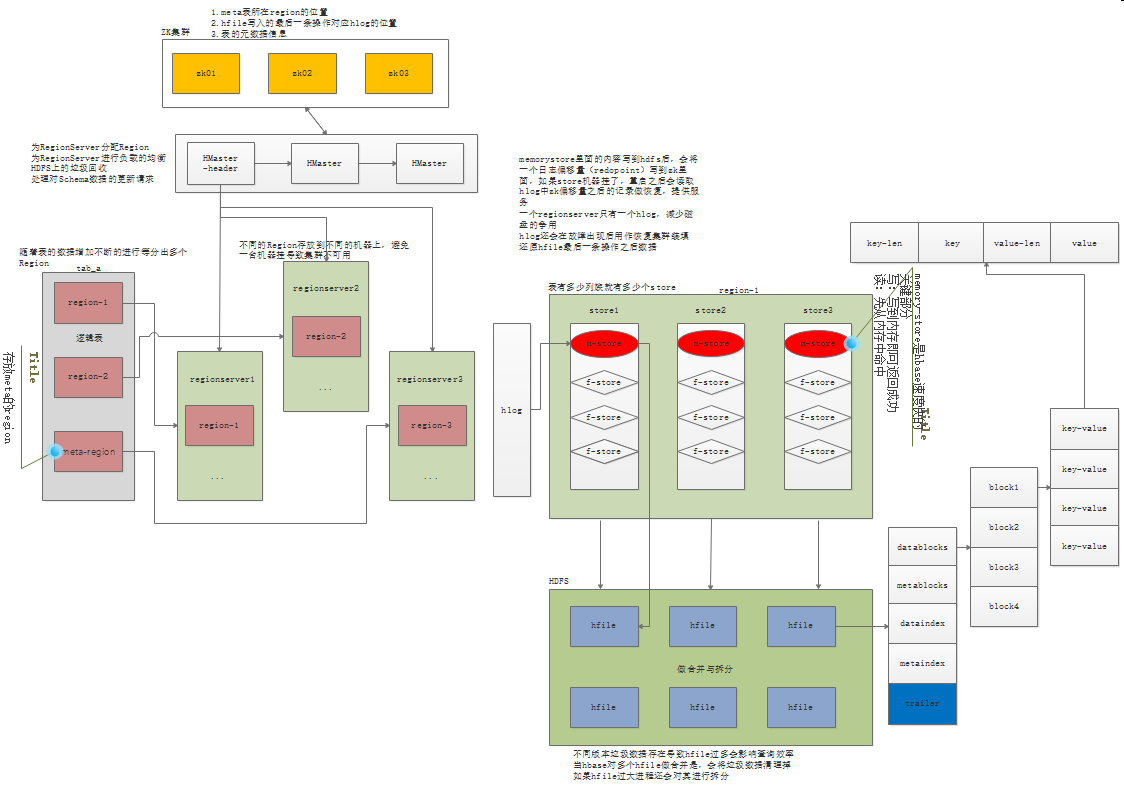
存储:
一个表被分为1...n个Region存储在不同的RegionServer上,一个Region包含多个store(store个数有表的列族决定),一个store有一个memory store和多个store file(可能是一个大的store file或者很多个小的store file,里面涉及到store的合并规格,store file对应hdfs里面就是hfile)
三大组件的工作
HMaster:
为RegionServer分配Region
为RegionServer进行负载的均衡
HDFS上的垃圾回收
处理对Schema数据的更新请求
HRegionServer
维护HMaster分配给它的Region
响应IO请求
做region切分
zookeeper
HMaster分布式协调
监控RegionServer的状态 将其上线下线信息通知HMaster
存储所有Region的寻址地址
存储hbase的元数据信息,比如:表 、列族等
更多的信息可以登录到zookeeper查看:ls /hbase
Region与Cell
Region
Region是HBase分布式存储的最小单元,而数据存储的最小单元是Cell。Region随着数据的不断增加会被切分成多个Region,然后由HMaster根据负载均衡算法决定他们都存放在哪个RegionServer上面,同时会更新meta表中的数据。
Region切分策略
ConstantSizeRegionSplitPolicy
0.94版本前默认切分策略
当一个region中最大的store file大于阈值(hbase.hregion.max.filesize)之后就会触发切分
store file是压缩后的大小,因此上传的文件可能是100M,压缩后也许只有30M
hbase.hregion.max.filesize不应设置过小,否则会导致region过多—>memorystore过多,每个memorystore都要分配内存,这样一来资源的利用率就会很差。从了解到的信息来看
IncreasingToUpperBoundRegionSplitPolicy
0.94版本~2.0版本默认切分策略
一个region中最大store file大于设置阈值就会触发切分,阈值公式为:(操作表在RegionServer上的region数)^3(flush size=128M)2,该种切分策略可以自适应大表和小表。
如果集群中小表过多,会导致有很多小的region在集群中存在。
可能导致region迁移到另一个RegionServer时发生split
SteppingSplitPolicy
2.0版本默认切分策略
一个region中最大store file大于设置阈值就会触发切分。当操作表在RegionServer上的region数等于1,切分阈值:flush size * 2,否则阈值是hbase.hregion.max.filesize
切分点
使用上面的切分策略触发切分后首先需要定位到切分点,切分点是Region当中最大的store file的最中心的block的第一个行键
关于更多的切分详细流程请参考HBase切分细节
Cell
Cell是数据存储的最小单元,通过行+列+时间戳可以唯一定义一个Cell,然后取出其中的数据。为什么有时间戳?因为一个列存在多个数据版本,时间戳最大的就是最新版本,也是默认取出来的版本。
写数据流程
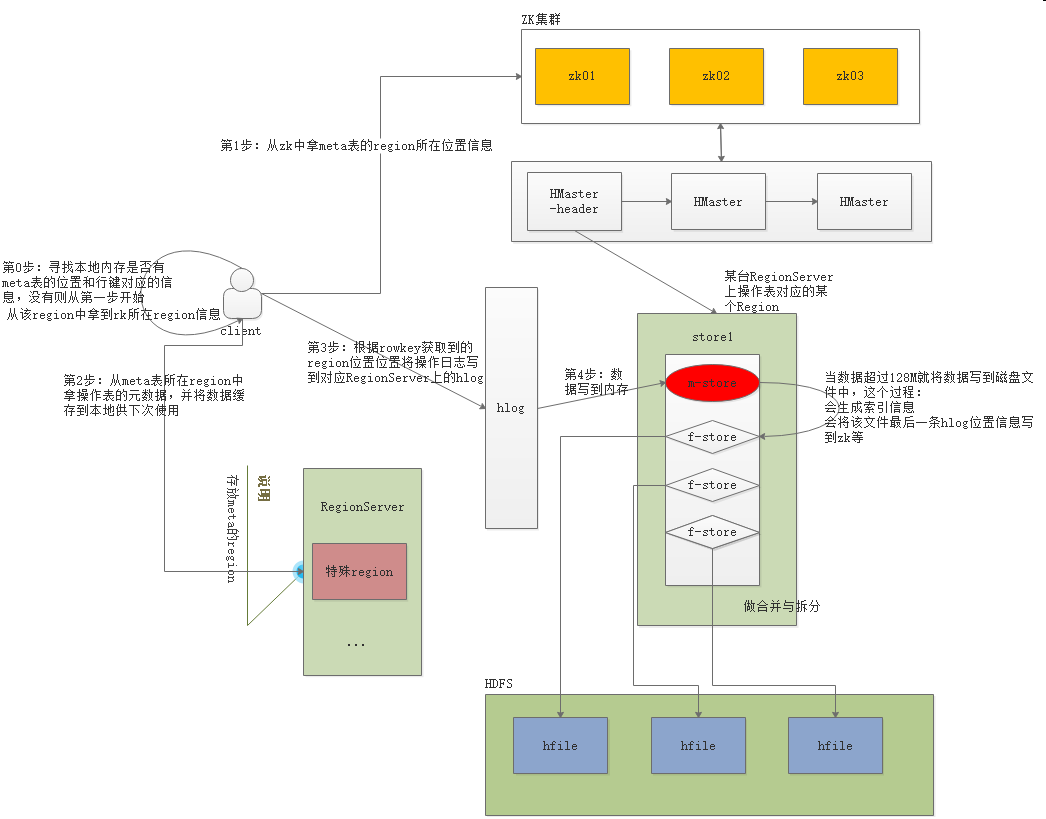
第1步:先看看本地内存是否有表的元数据信息,有则直接开始写数据(第4步),否则往下
第2步:到zk中拿meta表的所在hdfs中的位置信息
第3步:从meta表拿到元数据信息,并保存到本地内存中
第4步:开始往RegionServer申请写入数据,RegionServer记录操作日志到Hlog文件中,将数据写入到memorystore中并返回客户端
第5步:该步骤另外线程在操作。当memorystore达到一定阈值的时候会创建一个新的memorystore继续响应请求,将老的memorystore中的内容写到store file中,并在zk中记录下最后写出数据的redo point(重做日志 标点,用于故障恢复)
由于store file是不能在文件中随机修改(HDFS特性决定的),数据更新只是在不断的新增store file,那么必然我们认为的同一份数据在磁盘上会存在多个版本的数据,其中旧版本的数据就是垃圾数据,时间长了需要清理,当做store file合并时就会清理这些垃圾数据。
当store file过大时又可能触发切分,切分成不同的region,不同的region可能被迁移到不同的RegionServer上(HMaster决定)。
如果hbase某台RegionServer挂了,重启的时候会从zk中找到redo point,然后从hlog中拿到重做日志,恢复数据到内存并开始提供对外服务
读数据流程
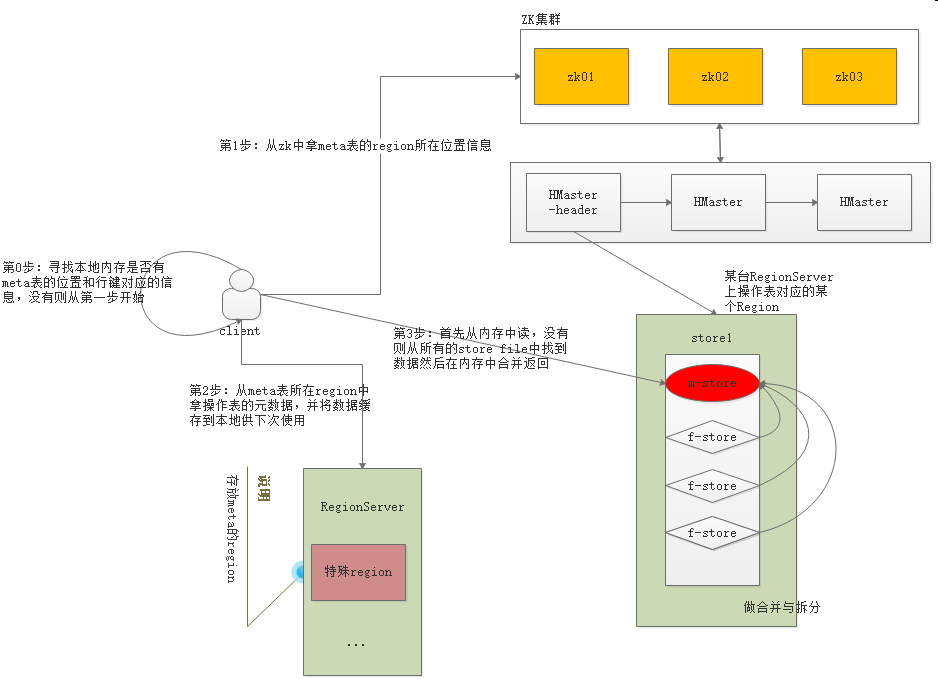
第1步:先看看本地内存是否有表的元数据信息,有则直接开始读数据(第4步),否则往下
第2步:到zk中拿meta表的所在hdfs中的位置信息
第3步:从meta表拿到元数据信息,并保存到本地内存中
第4步:看内存中是否有数据,有则直接返回,否则查找每个store file的Trailer,通过trailer找到Data Block Index,如果在这里发现了要找的数据,通过索引找到Data Blocks中对应的Data Block,将Data Block数据送回内存组装,最终多个hfile中获取到的数据合并后返回最新的给客户端
由于hbase中的数据天然排序,再加上索引,所以整个查询可以非常的快
列族设计要点
-
在设计hbase表时候,列族不宜过多,越少越好,官方推荐hbase表的列族不宜超过3个,因为region的store越多,memory store就越多,浪费资源
-
经常要在一起查询的数据最好放在一个列族中,尽量的减少跨列族的数据访问
-
如果有多个列族,多个列族中的数据应该设计的比较均匀,否则会出现很多的小文件,不利于hadoop发挥其性能
经了解,不少公司就是一张表一个列族
行键设计要点:
-
行键必须唯一
-
行键必须有业务上的意义,拿到行键你得知道它代表什么数据,可以根据业务上的数据拼凑出行键做查询,不要使用完全随机数,否则数据进去了,你拿不出来。当然如果不会根据行键查询都是全表扫描就另当别论了。
-
行键最好是字符串类型
-
行键最好具有固定的长度,不同长度的数据可能会造成排序后的结果和预期不一致
-
行键不宜过长,行键最多可以达到64KB,但建议在10~100字节之间,最好不要超过16字节,越短越好,最好是8字节的整数倍