
作者:小伍哥
来源:AI入门学习
python内置一系列强大的字符串处理方法,但这些方法只能处理单个字符串,处理一个序列的字符串时,需要用到循环。
那么,有没有办法,不用循环就能同时处理多个字符串呢,pandas的向量化操作就提供了这样的方法。
向量化的操作使我们不必担心数组的长度和维度,只需要关系操作功能,尤为强大的是,除了支持常用的字符串操作方法,还集成了正则表达式的大部分功能,这使得pandas在处理字符串列时,具有非常大的魔力。
例如,要计算每个单词中‘a’的个数,下面一行代码就可以搞定,非常高效。

假如用内置的字符串函数进行操作,需要进行遍历,且Python原生的遍历操作无法处理缺失值。
#用循环进行处理

#存在缺失值时,打印报错

Pandas的向量化操作,能够正确的处理缺失值,无报错信息,如下:

通过上面的例子,对向量化进行简单总结,向量化是一种同时操作整个数组而不是一次操作一个元素的方法,下面从看看具体怎么应用。
向量化的字符方法
Pandas的字符串属的方法几乎包括了大部分Python的内置字符串方法(内置共有45个方法),下面将列举一些常见的方法的用法,例如上面的count()方法将会返回某个字符的个数,而len方法将会返回整个字符的长度。
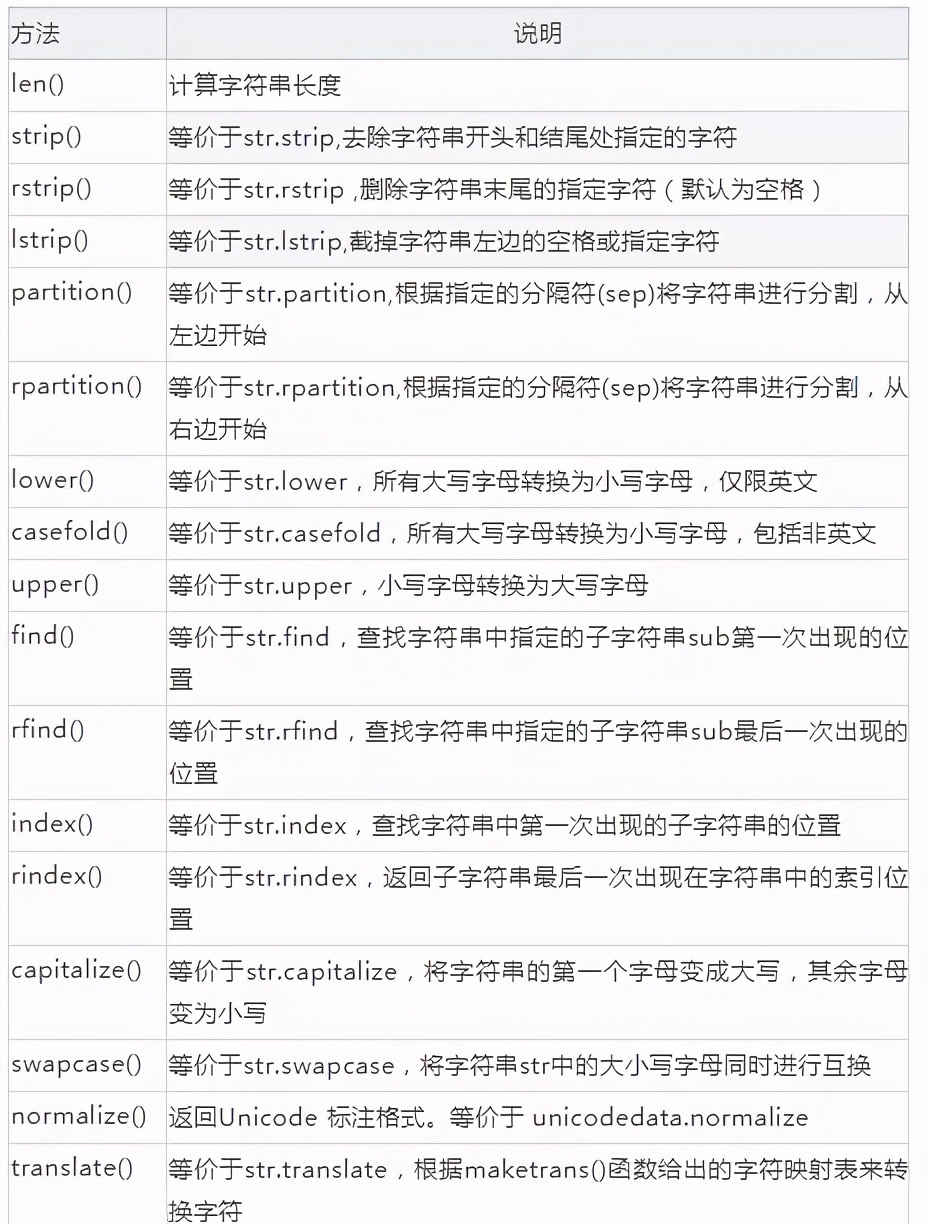

下面选取部分函数举例,其他函数参考字符串模块:Python字符串的45个方法详解
len()

lower()

zfill()
右对齐,前面用0填充到指定字符串长度。

向量化的正则表达式
Pandas的字符串方法根据Python标准库的re模块实现了正则表达式,下面将介绍Pandas的str属性内置的正则表达式相关方法。

split()
split,按指定字符分割字符串,类似split的方法返回一个列表类型的序列
#按数字分割

切分后的列表中的元素可以通过get方法或者 [] 方法进行读取

使用expand方法可以轻易地将这种返回展开为一个数据表。

同样,我们也可以限制切分的次数:

rsplit()
rsplit与split相似,不同的是,这个切分的方向是反的。即,从字串的尾端向首段切分。

replace ()
replace方法默认使用正则表达式

findall()
提取聊天记录中的QQ号

其他向量化的方法
除了上面介绍的Pandas字符串的正常操作和正则表达式外,Pandas的str属性还提供了其他的一些方法,这些方法非常的有用,在进行特征提取或者数据清洗时,非常高效,具体如下:
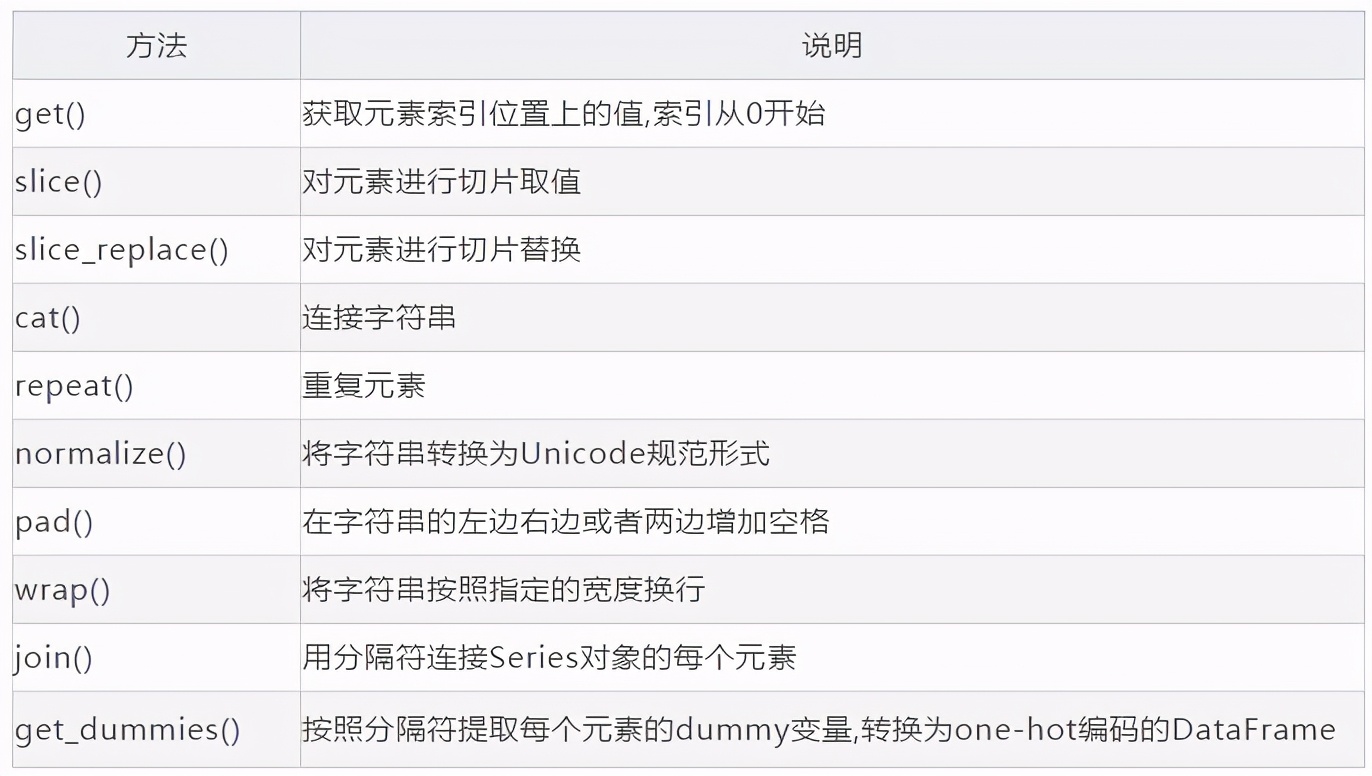
wrap()

pad()

slice()

get()

slice_replace()
切片替换

get_dummies()
另一个需要好好解释的是get_dummies()方法,举个例子:假如我们用A,B,C,D来表示一个人的某个特征:

repeat()

cat()
作用:连接字符串
用法:Series.str.cat(others=None, sep=None, na_rep=None)
参数:
- others : 列表或复合列表,默认为None,如果为None则连接本身的元素
- sep : 字符串 或者None,默认为None
- na_rep : 字符串或者 None, 默认 None。如果为None缺失值将被忽略。
返回值: concat : 序列(Series)/索引(Index)/字符串(str)
