前言
涉及到多进程/线程间对文件的并发读写,首先说明一下比较常见的多进程读写方法是在保证数据不混乱的前提下,让某一个进程专门负责写该文件,其它进程负责往该进程发消息。通常在日志系统中,开启一个专门的进程/线程进行文件的写操作,其他进程/线程充当生产者将内容传递给专门写的进程/线程负责write入文件。
一、文件写入方法
-
write:
write函数在<unistd.h>头文件中定义。ssize_t write(int fd, const void *buf, size_t count);
说明:write()函数尝试从buf开头的缓冲区中读取count个字节,并将其写入到文件描述符fd中。写入的字节数可能会小于count。比如:底层的物理截止没有足够的空间,或者遇到RLIMIT_FSIZE 资源限制,或者函数调用的时候被信号打断,没有写完。write写操作是原子操作,原子性体现在写入数据和更新该进程文件表项中的文件偏移量(见最后的源码分析)。虽然单独一个写操作是原子的,但是多进程读写时,若每个进程有单独的进程文件表项,当其它进程写入数据则会发生数据覆盖的情况,为了解决这一问题,就需要在
open()函数中附加一个标志O_APPEND。write()函数在append模式写入时是原子操作(写入的buf不超过内核缓存的情况下),对同一文件同一时间只能有一个write()对其写入,也就不会发生两个进程数据交叉出现的情况。通过O_APPEND标志将获取文件的offset和文件写入放在一起用锁进行了保护(write只是写入的原子操作),使得这两步是原子的,不会被内核打断。为了使进程间的数据不覆盖,要将更新文件偏移量与写文件放在一起加锁形成原子操作。文件写入前,先由
mutex_lock()对文件上锁,再进行相关操作并写文件,要达到不覆盖数据的目的,则要在上锁之后、写文件之前更新文件偏移量。//内核的同步写入函数 ssize_t generic_file_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos) { struct address_space *mapping = file->f_mapping; struct inode *inode = mapping->host; ssize_t ret; struct iovec local_iov = { .iov_base = (void __user *)buf, .iov_len = count }; // 文件的写入是加锁的 mutex_lock(&inode->i_mutex); ret = __generic_file_write_nolock(file, &local_iov, 1, ppos); mutex_unlock(&inode->i_mutex); if (ret > 0 && ((file->f_flags & O_SYNC) || IS_SYNC(inode))) { ssize_t err; err = sync_page_range(inode, mapping, *ppos - ret, ret); if (err < 0) ret = err; } return ret; } //加锁函数__generic_file_write_nolock中会做必要的数据检测:写入数据后是否超过系统文件大小限制,一次写入的数据量不能超过缓存大小、append标志更新偏移量等。 inline int generic_write_checks(struct file *file, loff_t *pos, size_t *count, int isblk) { struct inode *inode = file->f_mapping->host; unsigned long limit = current->signal->rlim[RLIMIT_FSIZE].rlim_cur; if (unlikely(*pos < 0)) return -EINVAL; if (!isblk) { /* FIXME: this is for backwards compatibility with 2.4 */ //这个判断语句是关键 if (file->f_flags & O_APPEND) *pos = i_size_read(inode); if (limit != RLIM_INFINITY) { if (*pos >= limit) { send_sig(SIGXFSZ, current, 0); return -EFBIG; } if (*count > limit - (typeof(limit))*pos) { *count = limit - (typeof(limit))*pos; } } } ... ... } -
fwrite
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)。参数说明如下:
ptr – 这是指向要被写入的元素数组的指针。
size – 这是要被写入的每个元素的大小,以字节为单位。
nmemb – 这是元素的个数,每个元素的大小为 size 字节。
stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输出流。 -
区别:fwrite中会创建用户态buf,会缓存多次写入,然后再一次性调用底层的write高效写入内核缓冲,可能会出现数据交叉的情况。fread 和fwrite,它自动分配缓存,速度会很快,比自己来设置buf要简单。如果要处理一些特殊的描述符,用read 和write,如套接口,管道之类的系统调用write的效率取决于你buf的大小和你要写入的总数量,如果buf太小,你进入内核空间的次数大增,效率就低下。而fwrite会替你做缓存,减少了实际出现的系统调用,所以效率比较高。使用write系统调用的情况下使用append,不会出现内容交叉的情况。使用fwriteANSIC标准C语言函数,会出现内容交叉的情况。
二、父子进程间读写文件
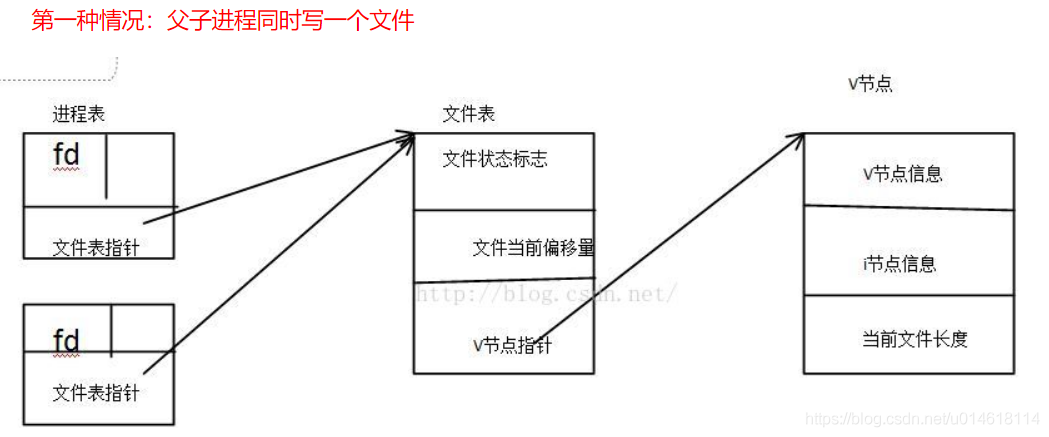
- 父进程再用fork函数创建子进程的时候,会把自己的上下文环境拷贝一份复制到子进程的内存空间中,这里当然包括进程表。所以子进程的进程表和父进程的是一模一样的,它们指向的是同一个文件表。两个亲缘关系的父子进程同时写一个文件时无论是否设置append模式,不会出现数据覆盖,这是有write的原子性(写入和更新进程表项的文件偏移量)保证的。两个进程对应文件表项中当前文件偏移量是唯一的,所以尽管在程序没有open函数没有使用append模式保证每次写入时的文件偏移量是正确的,但是依然能做到数据无覆盖。write分为定位和写入两个阶段,定位操作指定内容写入文件的位置,O_APPEND 设定定位与写入操作的原子性,每次写入都追加到文件末尾,它使得定位与写入成为原子操作,也即每次写入的时候都定位到文件的末尾,然后完成写操作,中间不允许打断。
- 文件锁: 如果使用fork()创建一个子进程,子进程会复制父进程中的所有描述符,从而使得它们也会指向同一个文件锁。在fork()之后,父进程关闭其文件描述符,然后锁就只在子进程的控制之下了。通过fork()创建的锁在exec()中会得以保留(除非在文件描述符上设置了close-on-exec标记并且该文件描述符是最后一个引用底层的打开文件描述的描述符)。其中O_CLOEXEC和FD_CLOEXEC作用:打开的文件描述符在执行exec调用新程序前自动被关闭。在进程
fork的时候,新产生的子进程的描述符也是从父进程继承(复制)来的。在子进程刚开始执行的时候,父子进程的描述符关系实际上跟在一个进程中使用dup复制文件描述符的状态一样。通过fork产生的多个进程,因为子进程的文件描述符是复制的父进程的文件描述符,所以导致父子进程同时持有对同一个文件的互斥锁。当一个文件描述符及其所有副本(包括子进程继承的和dup的)关闭时,才会释放对其建立的锁。子进程对继承的文件描述符上的锁进行修改/解锁,会影响到父进程的锁(对于dup的副本同样试用)。
二、 非亲缘进程间读写:
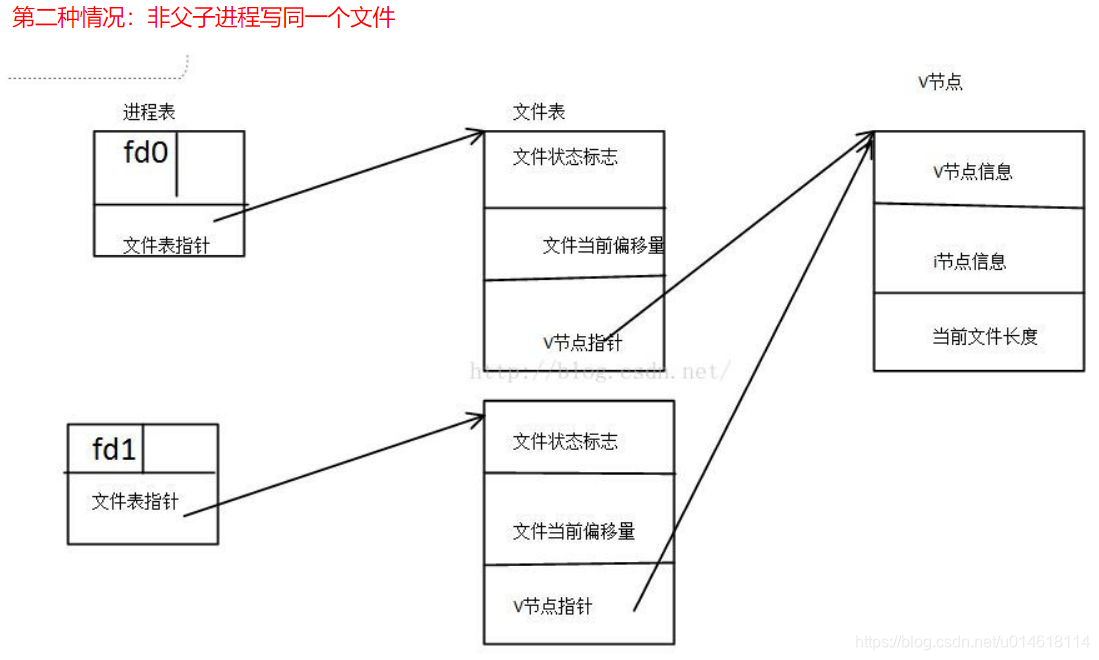
每个进程都有自己的缓冲区和文件表项,write首先写入该缓冲区,然后更新自己进程的文件表项偏移量,从而导致了多个进程之间的写操作是互不可见的,偏移量无法及时同步,进而可能出现写覆盖。两个非亲缘关系的进程使用append模式同时写一个文件时,不会出现数据混乱和覆盖的情况。注意:内核write函数在写入时是原子操作,所以两个进程会有一个竞争关系,最终只会由某个进程写入数据。两个非亲缘关系的进程同时写一个文件时,如果没有设置append同步文件偏移量,那么两个进程写入的数据会出现覆盖的情况。
三、 进程间的文件锁
在多个进程同时操作同一份文件的过程中,很容易导致文件中的数据混乱,需要锁操作来保证数据的完整性,这里介绍的针对文件的锁,称之为“文件锁”-flock,只能对整个文件加锁,这种粗粒度的加锁会限制协作进程间的并发。
-
flock,建议性锁,不具备强制性。一个进程使用flock将文件锁住,另一个进程可以直接操作正在被锁的文件,修改文件中的数据,原因在于flock只是用于检测文件是否被加锁,针对文件已经被加锁,另一个进程写入数据的情况,内核不会阻止这个进程的写入操作,也就是建议性锁的内核处理策略。
-
flock主要三种操作类型:
LOCK_SH,共享锁,多个进程可以使用同一把锁,常被用作读共享锁;
LOCK_EX,排他锁,同时只允许一个进程使用,常被用作写锁;
LOCK_UN,释放锁; -
进程使用flock尝试锁文件时,如果文件已经被其他进程锁住,进程会被阻塞直到锁被释放掉,或者在调用flock的时候,采用LOCK_NB参数,在尝试锁住该文件的时候,发现已经被其他服务锁住,会返回错误,errno错误码为EWOULDBLOCK。即提供两种工作模式:阻塞与非阻塞类型。
-
如果我们在进程中复制了一个文件描述符,那么使用
flock对这个描述符加的锁也会在新复制出的描述符中继续引用。 如果我们在进程中复制了一个文件描述符,那么使用flock对这个描述符加的锁也会在新复制出的描述符中继续引用。如果通过一个特定的文件描述符获取了一个锁并且创建了该描述符的一个或多个副本,那么,如果不显示的调用一个解锁操作,只有当文件描述符副本都被关闭了之后锁才会被释放。当一个文件描述符被复制时(dup()、dup2()、或一个fcntl() F_DUPFD操作),新的文件描述符会引用同一个文件锁。
四、 多线程读写文件
4.1 分析
- 一般单个文件单线程写可以保证性能。用一个线程专门负责文件写, 其它线程将数据包推入队列, 负责写的线程从队列中取数据操作
- 每个线程独立写一个文件, 全部完了再合并成一个文件。
- 使用读写锁,效率不如单线程写。
- append模式追加,与多进程类似。
4.2 : 一个线程往文件里写入内容,三个线程同时从文件中读取内容。但是。。写入的内容可能还在缓存区,没有立即被写入文件中,甚至直到程序结束才被完全写入文件中。这样不是无法读取往程序中写入的内容么?有何解决的方法?

五、文件描述符与打开文件的关系?
-
两个进程可以同时打开同一个文件,分别产生生成两个独立的fd。两个进程可以任意对文件进行读写操作,操作系统并不保证写的原子性。进程可以通过系统调用对文件加锁,从而实现对文件内容的保护。任何一个进程删除该文件时,另外一个进程不会立即出现读写失败。两个进程可以分别读取文件的不同部分而不会相互影响。一个进程对文件长度和内容的修改另外一个进程可以立即感知。
-
内核中,对应于每个进程都有一个文件描述符表,表示这个进程打开的所有文件。文件描述表中每一项都是一个指针,指向一个用 于描述打开的文件的数据块———file对象,file对象中描述了文件的打开模式,读写位置等重要信息,当进程打开一个文件时,内核就会创建一个新的file对象。需要注意的是,file对象不是专属于某个进程的,不同进程的文件描述符表中的指针可以指向相同的file对象,从而共享这个打开的文件。file对象有引用计数,记录了引用这个对象的文件描述符个数,只有当引用计数为0时,内核才销毁file对象,因此某个进程关闭文件,不影响与之共享同一个file对象的进程。

-
在处理文件时,内核空间和用户空间使用的主要对象是不同的。对用户程序来说,一个文件由一个文件描述符标识。该描述符是一个整数,在所有有关文件的操作中用作标识文件的参数。文件描述符是在打开文件时由内核分配,只在一个进程内部有效。两个不同进程可以使用同样的文件描述符,但二者并不指向同一个文件。基于同一个描述符在进程间来共享文件是不可能的。
六、 多线程write的原子性分析
首先,write调用不能保证你要求的调用是原子的,以下面的调用为例:
ret = write(fd, buff, 512);
Linux无法保证将512字节的buff写入文件这件事是原子的,因为:
-
即便你写了512字节那也只是最大512字节,buff不一定有512字节这么大;
-
write操作有可能被信号中途打断,进而使得ret实际上小于512;
-
实现根据不同的系统而不同,且几乎都是分层,作为接口无法确保所有层资源预留。磁盘的缓冲区可能空间不足,导致底层操作失败。
如果不考虑以上这些因素,write调用为什么不设计成直接返回True或者False呢?要么成功写入512字节,要么一点都不写入,这样岂不更好?之所以不这么设计,正是基于上述不可回避的因素来考虑的。其次,write调用能保证的是,不管它实际写入了多少数据,比如写入了n字节数据,在写入这n字节数据的时候,在所有共享文件描述符的线程或者进程之间,每一个write调用是原子的,不可打断的。
如果你希望多线程写文件的时候数据不会交叉,那就是在所有写进程打开文件的时候,采用O_APPEND方式打开即可。APPEND模式通过锁inode,保证每次写操作均在inode中获取的文件size后追加数据,写完后释放锁;由于write调用只是在inode或者file层面上保证一次写操作的原子性,但无法保证用户需要写入的数据的一次肯定被写完,所以在多线程多进程文件共享情况下就需要用户态程序自己来应对short write问题,比如设计一个锁保护一个循环,直到写完成或者写出错,不然循环不退出,锁不释放。可以说明,write系统调用在buf大小不超过内核缓存的时候是原子操作。理论上讲,内核可以在任何时候写磁盘,但并不是所有的write操作都会导致内核的写动作。内核会把要写的数据暂时存在缓冲区中,积累到一定数量后(达到一定的胀页比例)再一次写入。有时会导致意外情况,比如断电,内核还来不及把内核缓冲区中的数据写道磁盘上,这些更新的数据就会丢失。
C库函数写文件通过缓冲区,如果产生fwrite字节数较少的情况,可能是因为没有及时刷新缓冲区,所以,在每次fwrite后,调用一次fflush(),刷新缓冲区,即可解决问题。write也是通过write来实现的,fwrite是C语言的库,而write是系统调用。差别在write每次写的数据是调用者要求的大小,比如调用者要求写入10个字节数据,write就会写10个字节数据到内核缓冲区中,所以依然涉及到用户态与內核态之间的切换,操作系统会定期地把这些存在内核缓冲区的数据写回磁盘中。而fwrite不一样,fwrite每次都会先把数据写入一个应用进程缓冲区,等到该缓冲区满了,或者调用类似调用fflush这种冲洗缓冲区的函数时,系统会调用write一次性把相应数据写进内核缓冲区中。同样减少了系统调用(即write调用)。
七、进程间传递文件描述符:
背景: 在进程之间经常遇到需要在各进程之间传递文件描述符的情况,例如有一种设备它在加电期间只能打开一次,如果关闭后再次打开就会发生错误。这时就需要有一个调度程序,它调度多个相同设备,当有客户端需要此类型的设备时会向它发送一个请求,服务器会把某个设备的描述符给客户端。但是,由于不同进程之间的文件描述符所表示的对象是不同的,这需要一种特殊的传递机制来实现上述的要求。
实现: 当一个进程向另一个进程传送一个打开的文件描述符时,实际是想要让发送进程和接收进程共享同一文件表项。在技术上,发送进程实际上向接收进程传送一个指向一打开文件表项的指针。该指针被分配存放在接收进程的第一个可用描述符项中。 (注意,不要造成错觉,以为发送进程和接收进程中的描述符编号是相同的,通常它们是不同的。)两个进程共享同一打开文件表项,在这一点上与fork之后,父、子进程共享打开文件表项的情况完全相同。

7.1 父子进程间传递:
在进行fork调用后,由于子进程会拷贝父进程的资源,所以父进程中打开的文件描述符在子进程中仍然保持着打开,我们很容易的就将父进程的描述符传递给了子进程。
7.2、非亲缘进程间传递文件描述符:
由于不同进程的文件描述符表不同,所以要传递一个文件描述符,就是要在接收进程中的文件描述符表中创建一个新的文件描述符,并且这两个文件描述符要指向内核中相同的文件表项。每个进程中所使用的fd项实际上最终都是在内核中统一的文件表格中得到了统一,这也是进程间能传送文件描述符的基础。发送进程实际上向接受进程传送一个指向文件表项的指针。该指针被分配存放在接受进程的第一个可用描述符项中,虽然名为传送描述符,但是发送和接受进程的实际使用描述符是几乎不可能相同的,当发送进程传送给接收进程后,通常关闭该描述符,只是在描述符表中去掉该描述符,文件在全局文件表中仍然存在,相当于交出监护权。
为了用UNIX域套接字交换文件描述符,发送和接收函数的参数中都有一个指向msghdr结构的指针,该结构包含了所有有关收发内容的信息。该结构的定义大致如下:
struct msghdr {
void *msg_name; /* optional address */
socklen_t msg_namelen; /* address size in bytes */
struct iovec *msg_iov; /* array of I/O buffers */
int msg_iovlen; /* number of elements in array */
void *msg_control; /* ancillary data */
socklen_t msg_controllen; /* number of ancillary bytes */
int msg_flags; /* flags for received message */
};
其中,头两个元素通常用于在网络连接上发送数据报文,在这里,目的地址可以由每个数据报文指定。下面两个元素使我们可以指定由多个缓冲区构成的数组(散布读和聚集写),这与对readv和writev函数的说明一样。msg_flags字段包含了说明所接收到消息的标志,有两个参数用来处理控制信息的传送和接收:msg_control字段指向cmsghdr(控制信息首部)结构,msg_contrllen字段包含控制信息的字节数。
struct cmsghdr {
socklen_t cmsg_len; /* data byte count, including header */
int cmsg_level; /* originating protocol */
int cmsg_type; /* protocol-specific type */
/* followed by the actual control message data */
};
为了发送文件描述符,将cmsg_len设置为cmsghdr结构的长度加一个整型(描述符)的长度,cmsg_level字段设置为SOL_SOCKET,cmsg_type字段设置为SCM_RIGHTS,用以指明我们在传送访问权。(SCM指的是套接字级控制信息,socket_level cnotrol message。)访问权仅能通过UNIX域套接字传送。描述符紧随cmsg_type字段之后存放,用CMSG_DATA宏获得该整型量的指针。
三个宏用于访问控制数据,一个宏用于帮助计算smsg_len所使用的值。
#include <sys/socket.h>
unsigned char *CMSG_DATA(struct cmsghdr *cp);
返回值:指向与cmsghdr结构相关联的数据的指针
struct cmsghdr *CMSG_FIRSTHDR(struct msghdr *mp);
返回值:指向与msghdr结构相关联的第一个cmsghdr结构的指针,若无这样的结构则返回NULL
struct cmsghdr *CMSG_NXTHDR(struct msghdr *mp, struct cmsghdr *cp);
返回值:指向与msghdr结构相关联的下一个cmsghdr结构的指针,该msghdr结构给出了当前cmsghdr结构,若当前cmsghdr结构已是最后一个则返回NULL
unsigned int CMSG_LEN(unsigned int nbytes);
返回值:为nbytes大小的数据对象分配的长度
Single UNIX规范定义了前三个宏,但没有定义CMSG_LEN。GMSG_LEN宏返回为存放长度为nbytes的数据对象(控制数据)所需的字节数。它先将nbytes加上cmsghdr结构(控制数据头部)的长度,然后按处理机体系结构的对齐要求进行调整,最后再向上取整。内核根据发送的cmsg_type值,会对发送方的fd进行转换,转换成接收到的fd,并且将接收方的fd映射为发送方fd对应的文件。
//示例:
int send_fd(int fd, int fd_to_send)
{
struct iovec iov[1];
struct msghdr msg;
char buf[2]; /* send_fd()/recv_fd() 2-byte protocol */
iov[0].iov_base = buf;
iov[0].iov_len = 2;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
if(fd_to_send < 0)
{
msg.msg_control = NULL;
msg.msg_controllen = 0;
buf[1] = -fd_to_send; /* nonzero status means error */
if(buf[1] == 0)
buf[1] = 1; /* -256, etc. would screw up protocol */
}
else
{
if(cmptr == NULL && (cmptr = malloc(CONTROLLEN)) == NULL)
return(-1);
cmptr->cmsg_level = SOL_SOCKET;
cmptr->cmsg_type = SCM_RIGHTS;
cmptr->cmsg_len = CONTROLLEN;
msg.msg_control = cmptr;
msg.msg_controllen = CONTROLLEN;
*(int *)CMSG_DATA(cmptr) = fd_to_send; /* the fd to pass */
buf[1] = 0; /* zero status means ok */
}
buf[0] = 0; /* null byte flag to recv_fd() */
if(sendmsg(fd, &msg, 0) != 2)
return(-1);
return(0);
}
八、write函数源码分析
ssize_t
generic_file_write(struct file *file,const char *buf,size_t count, loff_t *ppos)
{
struct address_space *mapping = file->f_dentry->d_inode->i_mapping;
struct inode *inode = mapping->host;
unsigned long limit = current->rlim[RLIMIT_FSIZE].rlim_cur;
loff_t pos;
/*
*不存在于page cache的时候分配的页面
*/
struct page *page, *cached_page;
ssize_t written;
long status = 0;
int err;
unsigned bytes;
/*验证count有效*/
if ((ssize_t) count < 0)
return -EINVAL;
/*验证用户态地址空间buf有效,可读*/
if (!access_ok(VERIFY_READ, buf, count))
return -EFAULT;
cached_page = NULL;
/*
*获取信号量i_sem 一次只能有一个进程对文件发出write系统调用
*/
down(&inode->i_sem);
pos = *ppos; /*文件的偏移量,即当前位置*/
err = -EINVAL;
if (pos < 0)
goto out;
err = file->f_error;
if (err) {
file->f_error = 0;
goto out;
}
written = 0;
/* FIXME: this is for backwards compatibility with 2.4 */
/*
*如果文件为普通文件且设置了O_APPEND
*则把*ppos设置为文件结束,i_size为文件大小
*新数据均为追加
*/
if (!S_ISBLK(inode->i_mode) && file->f_flags & O_APPEND)
pos = inode->i_size;
/*
* Check whether we've reached the file size limit.
*/
/*
* 执行文件大小检查.
*/
err = -EFBIG;
if (!S_ISBLK(inode->i_mode) && limit != RLIM_INFINITY) {
if (pos >= limit) {
send_sig(SIGXFSZ, current, 0);
goto out;
}
/* Fix this up when we got to rlimit64 */
if (pos > 0xFFFFFFFFULL)
count = 0;
else if(count > limit - (u32)pos) {
/* send_sig(SIGXFSZ, current, 0); */
count = limit - (u32)pos;
}
}
/*
* LFS rule
*/
if ( pos + count > MAX_NON_LFS && !(file->f_flags&O_LARGEFILE)) {
if (pos >= MAX_NON_LFS) {
send_sig(SIGXFSZ, current, 0);
goto out;
}
if (count > MAX_NON_LFS - (u32)pos) {
/* send_sig(SIGXFSZ, current, 0); */
count = MAX_NON_LFS - (u32)pos;
}
}
/*
* Are we about to exceed the fs block limit ?
*
* If we have written data it becomes a short write
* If we have exceeded without writing data we send
* a signal and give them an EFBIG.
*
* Linus frestrict idea will clean these up nicely..
*/
if (!S_ISBLK(inode->i_mode)) {
if (pos >= inode->i_sb->s_maxbytes)
{
if (count || pos > inode->i_sb->s_maxbytes) {
send_sig(SIGXFSZ, current, 0);
err = -EFBIG;
goto out;
}
/* zero-length writes at ->s_maxbytes are OK */
}
if (pos + count > inode->i_sb->s_maxbytes)
count = inode->i_sb->s_maxbytes - pos;
} else {
if (is_read_only(inode->i_rdev)) {
err = -EPERM;
goto out;
}
if (pos >= inode->i_size) {
if (count || pos > inode->i_size) {
err = -ENOSPC;
goto out;
}
}
if (pos + count > inode->i_size)
count = inode->i_size - pos;
}
err = 0;
if (count == 0)
goto out;
remove_suid(inode);
/*
*上次修改索引节点时间合上次写文件时间为当前时间
*索引节点对象标记为脏
*/
inode->i_ctime = inode->i_mtime = CURRENT_TIME;
mark_inode_dirty_sync(inode);
/*
*检查O_DIRECT标志,若设置则写操作绕过page cache
*/
if (file->f_flags & O_DIRECT)
goto o_direct;
/*
*未设置O_DIRECT标志,按页循环写
*/
do {
unsigned long index, offset;
long page_fault;
char *kaddr;
int deactivate = 1;
/*
* Try to find the page in the cache. If it isn't there,
* allocate a free page.
*/
/*该页面起点offset*/
offset = (pos & (PAGE_CACHE_SIZE -1)); /* Within page */
/*要写的缓冲页面逻辑序号index*/
index = pos >> PAGE_CACHE_SHIFT;
/*写入长度bytes*/
bytes = PAGE_CACHE_SIZE - offset;
if (bytes > count) {
bytes = count;
deactivate = 0;
}
/*
* Bring in the user page that we will copy from _first_.
* Otherwise there's a nasty deadlock on copying from the
* same page as we're writing to, without it being marked
* up-to-date.
*/
{
volatile unsigned char dummy;
__get_user(dummy, buf);
__get_user(dummy, buf+bytes-1);
}
status = -ENOMEM; /* we'll assign it later anyway */
/*
* 在页高速缓存中找页,如果页没有缓存,调用page_cache_alloc分配新页面,
* 且调用add_to_page_cache_unique 通过他来调用__add_to_page_cache
*将新页面加入高速缓存
* 包括inode queue(clean pages)和hash表
* & 调用lru_cache_add将其加入LRU
* 锁住页 PG_locked标志
* 增加页引用计数器,其count字段
*/
page = __grab_cache_page(mapping, index, &cached_page);
if (!page)
break;
/* We have exclusive IO access to the page.. */
if (!PageLocked(page)) {
PAGE_BUG(page);
}
/*
*获得页的起始线性地址
*/
kaddr = kmap(page);
/*
*调用索引节点的address_space对象prepare_write分配相应的bh结构,
*建立队列然后对队列进行初始化
*还考虑调用ll_rw_block从磁盘中读取一些缓冲区(如果有必要)
*详见block_prepare_write解析一文
*/
status = mapping->a_ops->prepare_write(file, page, offset, offset+bytes);
if (status)
goto sync_failure;
/*
*把用户态下缓冲区中的字符copy到页中
*/
page_fault = __copy_from_user(kaddr+offset, buf, bytes);
flush_dcache_page(page);
conditional_schedule();
/*
*调用索引节点的address_space对象commit_write
*把buffers标记为脏,以便随后将其写入磁盘
*详见generic_commit_write解析一文
*/
status = mapping->a_ops->commit_write(file, page, offset, offset+bytes);
if (page_fault)
goto fail_write;
if (!status)
status = bytes;
if (status >= 0) {
written += status;
count -= status;
pos += status;
buf += status;
}
unlock:
kunmap(page);
/* Mark it unlocked again and drop the page.. */
UnlockPage(page);
if (deactivate)
deactivate_page(page);
else
mark_page_accessed(page);
page_cache_release(page);
if (status < 0)
break;
} while (count);
done:
*ppos = pos;
if (cached_page)
page_cache_release(cached_page);
/* For now, when the user asks for O_SYNC, we'll actually
* provide O_DSYNC. */
if (status >= 0) {
if ((file->f_flags & O_SYNC) || IS_SYNC(inode))
status = generic_osync_inode(inode, OSYNC_METADATA|OSYNC_DATA);
}
out_status:
err = written ? written : status;
out:
up(&inode->i_sem);
return err;
fail_write:
status = -EFAULT;
goto unlock;
sync_failure:
/*
* If blocksize < pagesize, prepare_write() may have instantiated a
* few blocks outside i_size. Trim these off again.
*/
kunmap(page);
UnlockPage(page);
page_cache_release(page);
if (pos + bytes > inode->i_size)
vmtruncate(inode, inode->i_size);
goto done;
o_direct:
written = generic_file_direct_IO(WRITE, file, (char *) buf, count, pos);
if (written > 0) {
loff_t end = pos + written;
if (end > inode->i_size && !S_ISBLK(inode->i_mode)) {
inode->i_size = end;
mark_inode_dirty(inode);
}
*ppos = end;
invalidate_inode_pages2(mapping);
}
/*
* Sync the fs metadata but not the minor inode changes and
* of course not the data as we did direct DMA for the IO.
*/
if (written >= 0 && file->f_flags & O_SYNC)
status = generic_osync_inode(inode, OSYNC_METADATA);
goto out_status;
}