一、总结基于遗传算法的优化BP神经网络的学习算法:
二、应用MATLAB实现基于遗传算法的优化BP神经网络:
要求有程序和实验结果
实验1
设计一个基于遗传算法的优化BP神经网络对曲线拟合,已知输入向量和输出向量为
P=-1:0.1:0.1
T=(-0.832 -0.423 -0.024 0.344 1.282
3.456 4.02 3.232 2.102 1.504 0.248 1.242 )
实验2仔细阅读下面内容,完成下述实验
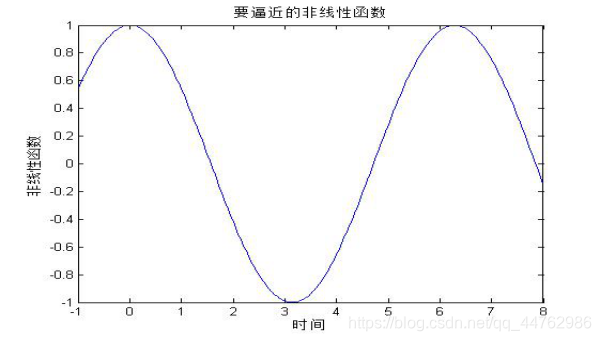
试设计一基于遗传算法的优化BP神经网络,逼近非线性函数y=cosx
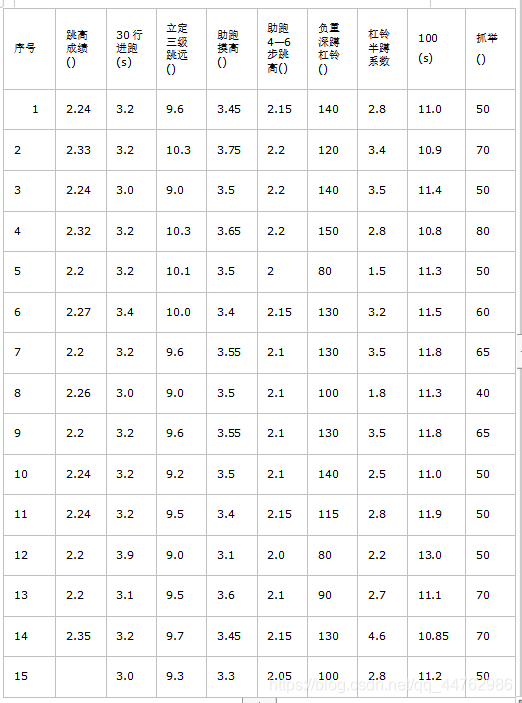
实验3 根据表1,设计一个基于遗传算法优化的BP神经网络,预测序号15的跳高成绩。
三、实验结果
实验一
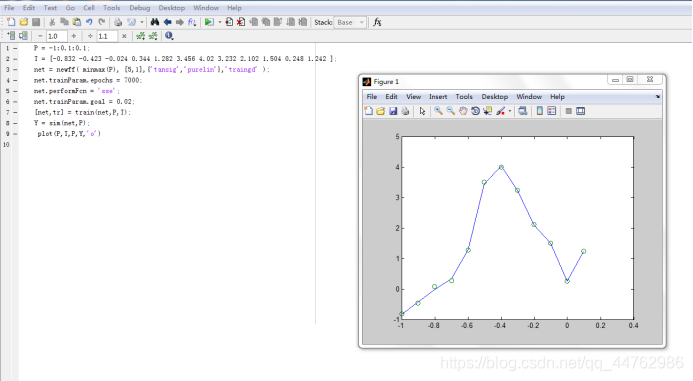
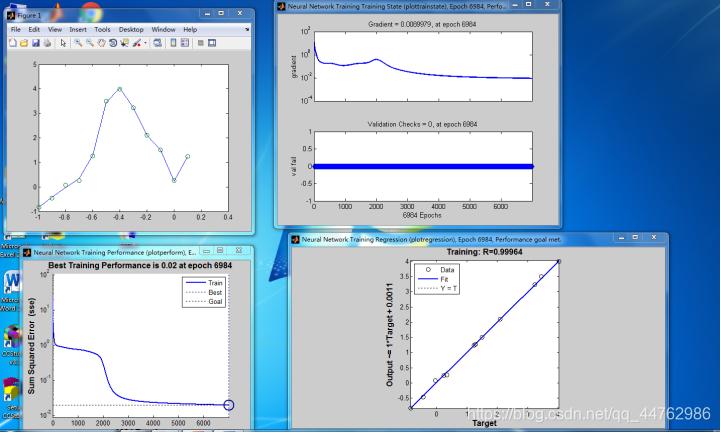
P = -1:0.1:0.1;
T = [-0.832 -0.423 -0.024 0.344 1.282 3.456 4.02 3.232 2.102 1.504 0.248 1.242 ];
net = newff( minmax(P), [5,1],{
'tansig','purelin'},'traingd' );
net.trainParam.epochs = 7000;
net.performFcn = 'sse';
net.trainParam.goal = 0.02;
[net,tr] = train(net,P,T);
Y = sim(net,P);
plot(P,T,P,Y,'o')
实验二
k=1;
p=[-1:.05:8];
t=cos(p);
plot(p,t,'-');
title('要逼近的非线性函数');
xlabel('时间');
ylabel('非线性函数');
n=3;
net = newff(minmax(p),[n,1],{
'tansig' 'purelin'},'trainlm');
%对于初始网络,可以应用sim()函数观察网络输出。
y1=sim(net,p);
figure;
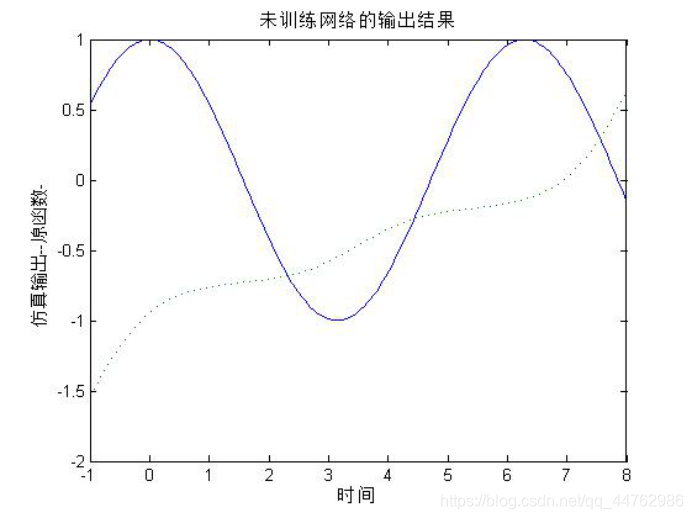
plot(p,t,'-',p,y1,':')
title('未训练网络的输出结果');
xlabel('时间');
ylabel('仿真输出--原函数-');
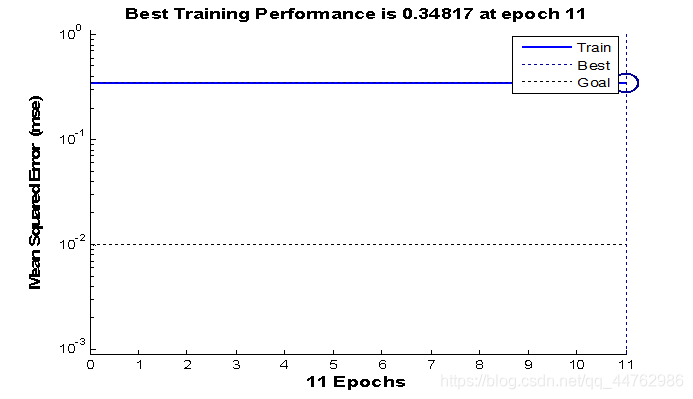
net.trainParam.epochs=50;
net.trainParam.goal=0.01;
net=train(net,p,t);
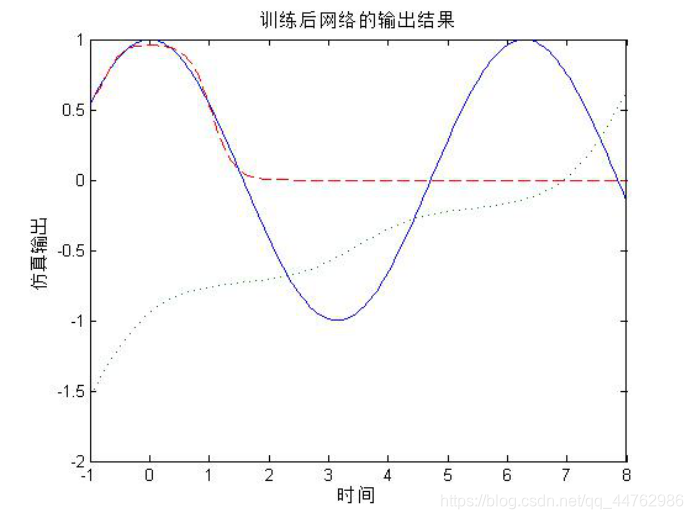
y2=sim(net,p);
figure;
plot(p,t,'-',p,y1,':',p,y2, '--')
title('训练后网络的输出结果');
xlabel('时间');
ylabel('仿真输出');
实验三
function err=Bpfun(x,P,T,hiddennum,P_test,T_test)
inputnum=size(P,1);
outputnum=size(T,1);
net=feedforwardnet(hiddennum);
net=configure(net,P,T);
net.layers{
2}.transferFcn='logsig';
net.trainParam.epochs=1000;
net.trainParam.goal=0.01;
net.trainParam.lr=0.1;
net.trainParam.show=NaN;
w1num=inputnum*hiddennum;
w2num=outputnum*hiddennum;
w1num=inputnum*hiddennum;
w2num=outputnum*hiddennum;
w1=x(1:w1num);
B1=x(w1num+1:w1num+hiddennum);
w2=x(w1num+hiddennum+1:w1num+hiddennum+w2num);
B2=x(w1num+hiddennum+w2num+1:w1num+hiddennum+w2num+outputnum);
net.iw{
1,1}=reshape(w1,hiddennum,inputnum);
net.lw{
2,1}=reshape(w2,outputnum,hiddennum);
net.b{
1}=reshape(B1,hiddennum,1);
net.b{
2}=reshape(B2,outputnum,1);
net=train(net,P,T);
Y=sim(net,P_test);
err=norm(Y-T_test);
function Obj = Objfun(X,P,T,hiddennum,P_test,T_test)
[M,N] = size(X);
Obj=zeros(M,1);
for i = 1:M
Obj(i)=Bpfun(X(i,:),P,T,hiddennum,P_test,T_test);
End
clc
clear all
close all
A=[3.2 3.2 3.0 3.2 3.2 3.4 3.2 3.0 3.2 3.2 3.2 3.9 3.1 3.2 3.0];
B=[9.6 10.3 9.0 10.3 10.1 10.0 9.6 9.0 9.6 9.2 9.5 9.0 9.5 9.7 9.3];
C=[3.45 3.75 3.5 3.65 3.5 3.4 3.55 3.5 3.55 3.5 3.4 3.1 3.6 3.45 3.3];
D=[2.15 2.2 2.2 2.2 2 2.15 2.1 2.1 2.1 2.1 2.15 2.0 2.1 2.15 2.05];
E=[140 120 140 150 80 130 130 100 130 140 115 80 90 130 100];
F=[2.8 3.4 3.5 2.8 1.5 3.2 3.5 1.8 3.5 2.5 2.8 2.2 2.7 4.6 2.8];
G=[11.0 10.9 11.4 10.8 11.3 11.5 11.8 11.3 11.8 11.0 11.9 13.0 11.1 10.85 11.2];
H=[50 70 50 80 50 60 65 40 65 50 50 50 70 70 50];
T=[2.24 2.33 2.24 2.32 2.2 2.27 2.2 2.26 2.2 2.24 2.24 2.2 2.2 2.35];
A=mapminmax(A,0,1);
B=mapminmax(B,0,1);
C=mapminmax(C,0,1);
D=mapminmax(D,0,1);
E=mapminmax(E,0,1);
F=mapminmax(F,0,1);
G=mapminmax(G,0,1);
H=mapminmax(H,0,1);
[T,PS1]=mapminmax(T,0,1);
P=[A;B;C;D;E;F;G;H];
P(:,15)=[];
net=newff([0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1],[20,1],{
'tansig','logsig'},'traingdx');
net.trainParam.epochs=15000;
net.trainParam.goal=0.01;
%设置学习速率为0.1
LP.lr=0.1;
net=train(net,P,T);
t1=sim(net,[0 0.2308 0.3077 0.2500 0.2857 0.4194 0.1818 0.2500])
T1_FANGUIYI=mapminmax('reverse',t1,PS1)
P_test=-1:0.1:0.1
T_test=[-0.832 -0.423 -0.024 0.344 1.282 3.456 4.02 3.232 2.102 1.504 0.248 1.242 ]
hiddennum=31;
threshold=[0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1];
inputnum=size(P,1);
outputnum=size(T,1);
w1num=inputnum*hiddennum;
w2num=outputnum*hiddennum;
N=w1num+hiddennum+w2num+outputnum;
NIND=40;
MAXGEN=5;
PRECI=10;
GGAP=0.95;
px=0.7;
pm=0.01;
trace=zeros(N+1,MAXGEN);
FieldD=[repmat(PRECI,1,N);repmat([-0.5;0.5],1,N);repmat([1;0;1;1],1,N)];
Chrom=crtbp(NIND,PRECI*N);
gen=0;
X=bs2rv(Chrom,FieldD);
ObjV=Objfun(X,P,T,hiddennum,P_test,T_test);
while gen<MAXGEN
fprintf('%d\n',gen)
FitnV=ranking(ObjV);
SelCh=select('sus',Chrom,FitnV,GGAP);
SelCh=recombin('xovsp',SelCh,px);
SelCh=mut(SelCh,pm);
X=bs2rv(SelCh,FieldD);
ObjVSel=Objfun(X,P,T,hiddennum,P_test,T_test);
[Chrom,ObjV]=reins(Chrom,SelCh,1,1,ObjV,ObjVSel);
X=bs2rv(Chrom,FieldD);
gen=gen+1;
[Y,I]=min(ObjV);
trace(1:N,gen)=X(I,:);
trace(end,gen)=Y;
end
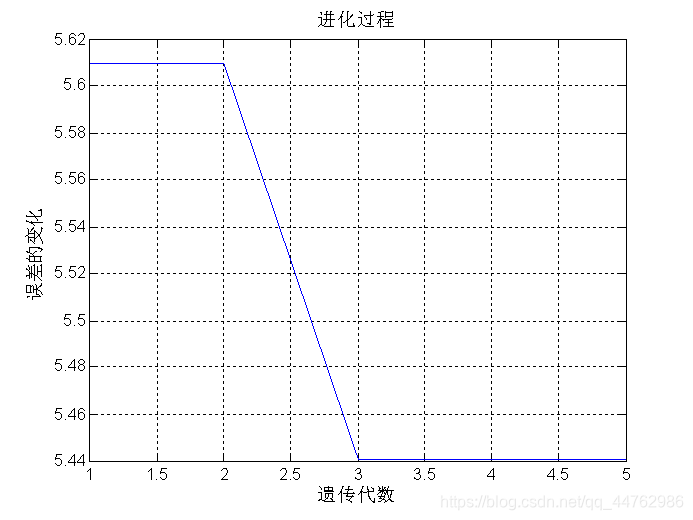
figure(1);
plot(1:MAXGEN,trace(end,:));
grid on
xlabel('遗传代数')
ylabel('误差的变化')
title('进化过程')
bestX=trace(1:end-1,end);
bestErr=trace(end,end);
fprintf(['最优初始权值和阈值:\nX=',num2str(bestX'),'\n最小误差err=',num2str(bestErr),'\n'])
hiddennum=31;
inputnum = size(P,1);
outputnum = size(T,1);
net = feedforwardnet(hiddennum);
net = configure(net,P,T);
net.layers{2}.transferFcn = 'logsig';
net.trainParam.epochs = 1000;
net.trainParam.goal = 0.01;
net.trainParam.lr = 0.1;
net = train(net,P,T);
disp(['1.使用随机权值和阈值'])
disp('测试样本预测结果:')
Y1 = sim(net,P_test)
err1 = norm(Y1-T_test);
err11 = norm(sim(net,P)-T);
disp(['测试样本的误差仿真误差:',num2str(err1)])
disp(['训练样本的误差仿真误差:',num2str(err11)])
inputnum = size(P,1);
outputnum = size(T,1);
net = feedforwardnet(hiddennum);
net = configure(net,P,T);
net.layers{2}.transferFcn = 'logsig';
net.trainParam.epochs = 1000;
net.trainParam.goal = 0.01;
net.trainParam.lr = 0.1;
w1num = inputnum*hiddennum;
w2num = outputnum*hiddennum;
w1=bestX(1:w1num);
B1=bestX(w1num+1:w1num+hiddennum);
w2=bestX(w1num+hiddennum+1:w1num+hiddennum+w2num);
B2=bestX(w1num+hiddennum+w2num+1:w1num+hiddennum+w2num+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=reshape(B2,outputnum,1);
net = train(net,P,T);
disp(['2.使用优化后的权值和阈值'])
disp('测试样本预测结果')
Y2 = sim(net,P_test)
err2 = norm(Y2-T_test);
err21 = norm(sim(net,P)-T);
disp(['测试样本的误差仿真误差:',num2str(err2)])
disp(['训练样本的误差仿真误差:',num2str(err21)])
实验结果
t1 =
0.1620 0.2990 0.2990 0.2990 NaN 0.2990 0.2990 NaN
T1_FANGUIYI =
2.2243 2.2448 2.2448 2.2448 NaN 2.2448 2.2448 NaN
P_test =
Columns 1 through 11
-1.0000 -0.9000 -0.8000 -0.7000 -0.6000 -0.5000 -0.4000 -0.3000 -0.2000 -0.1000 0
Column 12
0.1000
T_test =
Columns 1 through 11
-0.8320 -0.4230 -0.0240 0.3440 1.2820 3.4560 4.0200 3.2320 2.1020 1.5040 0.2480
Column 12
1.2420
0
1
2
3
4
最优初始权值和阈值:
X=0.045455 -0.4521 -0.33969 -0.021994 -0.25562 0.06696 0.29765 0.33187 -0.27713 0.41105 0.33675 0.40225 -0.39443 0.41105 0.07087 -0.36706 -0.08651 -0.018084 -0.3348 -0.10508 -0.084555 -0.43939 -0.4912 -0.027859 0.034702 0.013196 -0.32405 -0.23021 0.23118 -0.46579 -0.39247 0.33675 -0.11486 0.026882 -0.36217 -0.40029 0.33675 0.35826 -0.48631 -0.37879 0.17937 -0.45601 0.35435 0.31329 0.31525 -0.22923 0.21261 0.00048876 0.48827 0.32991 0.4306 -0.38172 0.42962 -0.26833 0.36706 -0.28495 -0.039589 0.11193 0.22727 0.41887 0.31329 0.45601 -0.48436 0.1305 0.19501 0.28397 -0.38074 -0.35142 -0.032747 -0.25073 0.24487 -0.29081 0.38465 0.47947 -0.32991 0.22043 -0.39638 -0.30645 0.20186 0.061095 -0.45503 0.48045 0.096285 0.35239 -0.30352 -0.08651 -0.15885 0.0063539 0.25562 -0.038612 -0.24194 0.23998 -0.49022 0.16373 0.071848 -0.48143 -0.19697 -0.06305 -0.37586 0.2263 -0.32209 0.14321 -0.44721 0.47752 -0.41984 -0.32991 0.32209 -0.20674 -0.3827 -0.09824 0.038612 0.22434 -0.0024438 0.14712 -0.28983 0.45308 -0.45112 0.09824 0.48827 0.28788 -0.05523 -0.28201 -0.029814 0.49902 0.11095 0.29472 -0.14223 -0.48729 -0.2957 -0.3739 0.18719 -0.37879 0.49022 0.0073314 -0.49707 -0.3827 0.38759 0.15591 -0.042522 0.42571 0.12757 0.18915 0.4609 0.39052 -0.061095 0.18817 -0.05132 -0.37195 -0.43548 -0.27419 -0.21554 0.045455 0.14418 -0.22923 -0.14418 0.09433 -0.17546 -0.24096 0.39932 0.21457 0.067937 0.25269 -0.23607 0.075758 -0.24878 0.32405 0.45699 -0.1217 0.054252 0.30059 -0.073803 0.39932 -0.022972 -0.29081 0.31818 0.15103 0.31232 -0.10508 -0.38759 -0.2566 -0.43646 -0.18328 0.44721 -0.3915 -0.39443 -0.17351 -0.17058 0.0826 0.17449 0.28006 0.10313 -0.37097 0.38661 0.27126 0.31427 -0.23118 0.32796 0.35728 -0.34751 -0.19892 -0.39736 0.10313 0.1305 -0.33284 -0.19501 -0.0043988 0.10117 0.30743 -0.2781 0.18622 0.49413 0.36901 -0.46579 -0.49316 -0.11388 -0.29472 -0.14809 -0.3739 0.47556 0.024927 0.33578 0.15396 0.48436 0.28299 -0.041544 -0.1911 0.42766 0.085533 -0.41691 -0.46872 0.42278 -0.087488 0.021017 0.075758 0.46774 -0.35924 0.010264 0.38172 0.152 0.30938 -0.40811 0.19795 -0.17742 0.34751 -0.31329 -0.13148 -0.023949 -0.25367 0.5 -0.16471 0.46481 -0.27028 0.44624 0.43255 -0.27517 0.1217 -0.36999 -0.28397 0.053275 0.12757 -0.091398 -0.23509 -0.033724 0.24194 0.27224 0.30254 -0.10508 0.40616 0.0024438 0.12366 -0.1999 0.34848 -0.0053763 -0.28983 -0.42571 0.18133 0.25464 -0.22043 -0.092375 0.1002 -0.026882 0.3651 0.18133 0.24878 0.27517 -0.41984 -0.07478 -0.45503 0.34555 -0.37097 -0.21554 -0.1002 -0.30743 0.44233 -0.2781 0.42571 0.30645 -0.3651 -0.1002 0.13148 -0.36608 -0.24096 -0.22239 0.23705 -0.24096 -0.48045 0.0435 0.34946 -0.16862 -0.41496 0.47165
最小误差err=5.4407
>>
1.使用随机权值和阈值
测试样本预测结果:
Y1 =
Columns 1 through 10
0.5003 0.5002 0.5002 0.5001 0.5001 0.5000 0.5000 0.5000 0.5000 0.5000
Columns 11 through 12
0.5000 0.5000
测试样本的误差仿真误差:6.0265
训练样本的误差仿真误差:1.3366
2.使用优化后的权值和阈值
测试样本预测结果
Y2 =
Columns 1 through 10
0.5000 0.5000 0.5000 0.5000 0.5000 0.5000 0.5000 0.5000 0.5000 0.5000
Columns 11 through 12
0.5000 0.5000
测试样本的误差仿真误差:6.0264
训练样本的误差仿真误差:1.3173
>>