目录
前言
上一篇博客:计组实验3 mips冒险之流水线冒险
摸了半个月了。。。咕咕咕 今天来写计组实验 4
这个实验非常简单,就是有点难。
这个实验比较容易算错,或者是被模拟器出人意料的结果搞的神神叨叨的,所以今天来记录并且详细分析该实验。
注:请务必阅读本文的【阻塞周期计算方法】部分,这部分是结论!看了就容易看懂实验中周期的计算。
实验内容
按照下面的实验步骤及说明,完成相关操作记录实验过程的截图:
- 首先,给出一段矩阵乘法的代码,通过开启BTB功能对其进行优化,并且观察流水线的细节,解释BTB在其中所起的作用;
- 其次,自行设计一段使得即使开启了BTB也无效的代码。
- 第三,使用循环展开的方法,观察流水因分支停顿的次数减少的现象,并对比采用BTB结构时流水因分支而停顿的次数。
(选做:在x86系统上编写C语言的矩阵乘法代码,用perf观察分支预测失败次数,分析其次数是否与你所学知识吻合。再编写前面第二部使用的令分支预测失败的代码,验证x86是否能正确预测,并尝试做解释)
背景知识
在遇到跳转语句的时候,我们往往需要等到MEM阶段才能确定这条指令是否跳转(通过硬件的优化,可以极大的缩短分支的延迟,将分支执行提前到ID阶段,这样就能够将分支预测错误代价减小到只有一条指令)
这种为了确保预取正确指令而导致的延迟叫控制冒险(分支冒险)。为了降低控制冒险所带来的性能损失,一般采用分支预测技术。
分支预测技术
分支预测技术包含编译时进行的静态分支预测,和执行时进行的动态分支预测。这里,我们着重介绍动态分支预测中的BTB(Branch Target Buffer)技术。
BTB即为分支目标缓冲器,它将分支指令(对应的指令地址)放到一个缓冲区中保存起来,当下次再遇到相同的指令(跳转判定)时,它将执行和上次一样的跳转(分支或不分支)预测。
一种可行的BTB结构示意图如下:
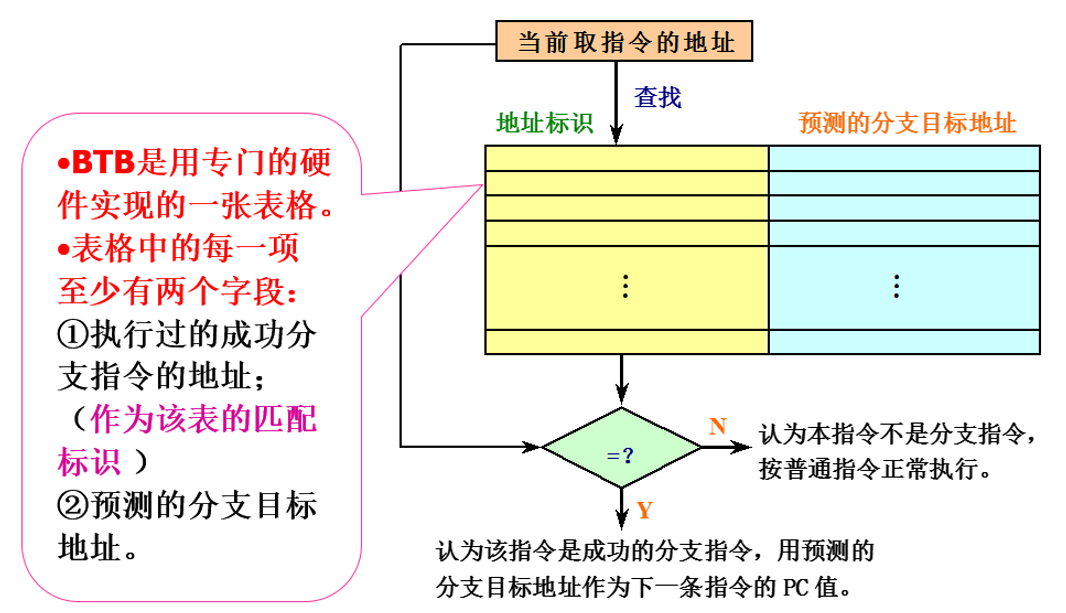
在采用了BTB之后,在流水线各个阶段所进行的相关操作如下:
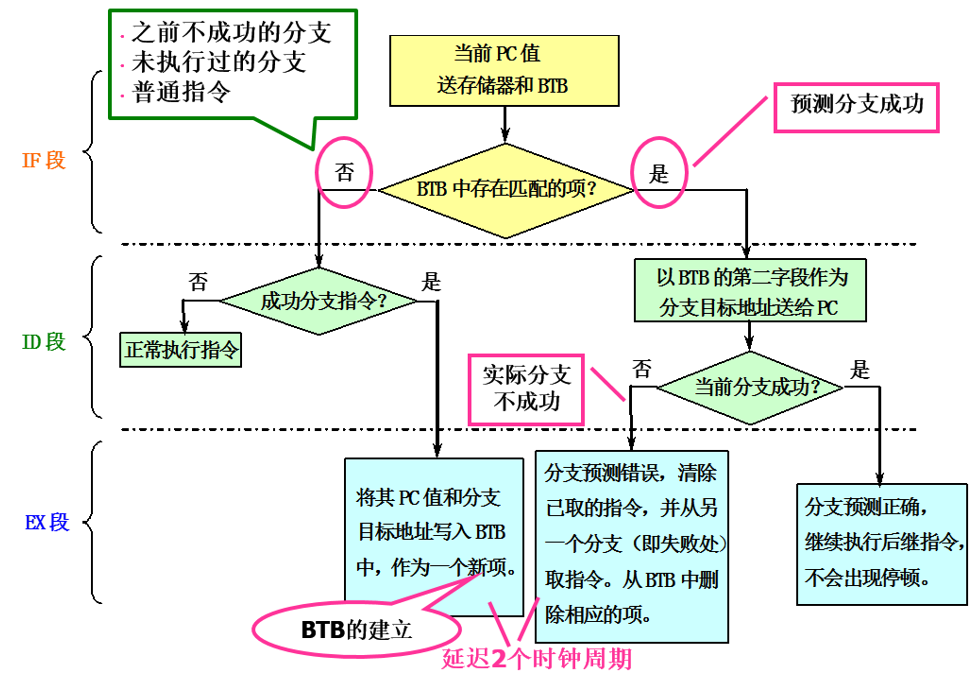
注意,为了填写或者删除BTB,需要 2 个周期。
这句话非常重要,对于我们的后续计算代码的阻塞周期数目十分重要。!!BTB分支的建立和错误,都会占用 2 个周期。
阻塞周期计算方法⭐
相信很多童鞋和我一样,在初次执行循环代码时,都会对阻塞的周期数目感到非常疑惑。
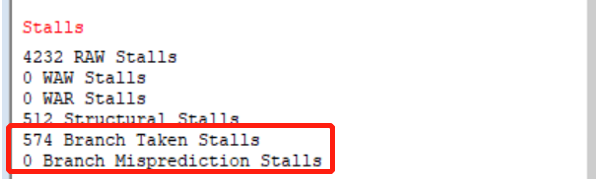
于是下面直接给出我总结的阻塞周期数目规律。以本实验的循环代码框架为例(即beq放在循环最后面,判断是否需要跳转回 loop 标号)
不开启 BTB
不开起 BTB 的情况下,mips 默认预测恒不跳转,一个 n 次的循环,会有 n-1 次 Branch Taken Stall,因为除了最后一次退出循环,beq 预测正确,其他的时候,beq 都是预测错误。而每个 Branch Taken Stall 阻塞一个周期
所以最终阻塞的周期数 = (n-1) * 1 = n-1 个周期
开启 BTB
开启 BTB 的情况下,一个 n 次的循环,会有 1 次 Branch Taken Stalls 和 1 次 Branch Misprediction Stalls
因为第一次进入循环,BTB 还未建立,发生 1 次 Branch Taken Stalls
此外,最后一次退出循环时的 beq,因为我们之前 BTB 都是预测它要跳转,于是最后一次出现预测失误,需要清除 BTB,发生一次 Branch Misprediction Stalls
不论 Branch Misprediction Stalls 和 Branch Misprediction Stalls,都需要花费 2 个周期去整改 BTB,所以最终阻塞的周期数 = 2
part 1 矩阵乘法与优化
在这一阶段,我们首先给出矩阵乘法的例子,接着将流水线设置为不带BTB功能(configure->enable branch target buffer)直接运行,观察结果进行记录;
然后,再开启BTB功能再次运行,观察实验结果。将两次的实验结果进行对比,观察BTB是否起作用,如果有效果则进一步观察流水线执行细节并且解释BTB起作用原因。
矩阵乘法的代码如下:
.data
str: .asciiz "the data of matrix 3:\n"
mx1: .space 512
mx2: .space 512
mx3: .space 512
.text
initial: daddi r22,r0,mx1 #这个initial模块是给三个矩阵赋初值
daddi r23,r0,mx2
daddi r21,r0,mx3
input: daddi r9,r0,64
daddi r8,r0,0
loop1: dsll r11,r8,3
dadd r10,r11,r22
dadd r11,r11,r23
daddi r12,r0,2
daddi r13,r0,3
sd r12,0(r10)
sd r13,0(r11)
daddi r8,r8,1
slt r10,r8,r9
bne r10,r0,loop1
# i=r17, j=r18, k=r19
mul: daddi r16,r0,8
daddi r17,r0,0
loop2: daddi r18,r0,0 #这个循环是执行for(int i = 0, i < 8; i++)的内容
loop3: daddi r19,r0,0 #这个循环是执行for(int j = 0, j < 8; j++)的内容
daddi r20,r0,0 #r20存储在计算result[i][j]过程中每个乘法结果的叠加值
loop4: dsll r8,r17,6 #这个循环的执行计算每个result[i][j]
dsll r9,r19,3
dadd r8,r8,r9
dadd r8,r8,r22
ld r10,0(r8) #取mx1[i][k]的值
dsll r8,r19,6
dsll r9,r18,3
dadd r8,r8,r9
dadd r8,r8,r23
ld r11,0(r8) #取mx2[k][j]的值
dmul r13,r10,r11 #mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 #中间结果累加
daddi r19,r19,1
slt r8,r19,r16
bne r8,r0,loop4
dsll r8,r17,6
dsll r9,r18,3
dadd r8,r8,r9
dadd r8,r8,r21 #计算result[i][j]的位置
sd r20,0(r8) #将结果存入result[i][j]中
daddi r18,r18,1
slt r8,r18,r16
bne r8,r0,loop3
daddi r17,r17,1
slt r8,r17,r16
bne r8,r0,loop2
halt
不设置BTB功能,运行该程序,观察Statistics窗口的结果截屏并记录下来。

接着,设置BTB功能(在菜单栏处选择Configure项,然后在下拉菜单中为Enable Branch Target Buffer选项划上钩)。并在此运行程序,观察Statistics窗口的结果并截屏记录下来。

接下来,对比其结果。我们就结合流水线执行细节分析造成这种情况发生的原因。
注:不要忘记初始化的时候执行了一次 64 的循环
未开启 BTB 的分析
而在没开启BTB的情况下,mips默认预测恒不跳转,那么只有最后一次循环结束时,不会跳转到 loop 标号,即预测正确。所以初始化阶段有 64-1=63 个 branch taken stalls。
而 8*8*8 的循环,每个循环,都是最后一步分支预测正确,即有不跳转,那么一个 8次的循环,就有 7 次 branch taken stalls。
而最内层循环执行 64 次,第二层循环执行 8 次,最外层循环执行 1 次那么有:64*7+8*7+1*7 = 511 个 branch taken stalls
开启 BTB 的分析
在开启 BTB 的情况下,branch taken stalls减少到了 148 个。
其中初始化时的 64 次单层循环,一共发生 1 次 branch taken stalls 和 1 次 branch mispronunciation stalls,即第一次和最后一次跳转,所以他们各占 2 个周期。
而三层的 8*8*8 循环体,共有 73 次 branch mispronunciation stalls 和 73 次 branch taken stalls,共占 146 个周期。其中 73=64+8+1。分析如下:
最内层循环每次循环结束,都会 mispronunciation(因为之前预测跳转,最后一次却不跳转)并且删除 BTB 中对应的项。
然后下一次循环开始,BTB 中没有对应项,故又会有 branch taken stalls。最内层循环共执行 64 次,故有 64 个 branch mispronunciation stalls 和 64 个 branch taken stalls。
第二层循环执行 8 次,最外层循环执行 1 次,同理。所以最后 branch mispronunciation stalls 和 branch taken stalls 的次数都是 64+8+1=73,而他们占的周期数是 73*2=146
所以最后有 2+146=148 个周期的 branch mispronunciation stalls 和 branch taken stalls
part 2 设计代码使 BTB 无效
在这个部分,我们要设计一段代码,这段代码包含了一个循环。根据BTB的特性,我们设计的这个代码将使得BTB的开启起不到相应的优化作用,反而会是的性能大大降低。
提示:一定要利用BTB的特性,即它的跳转判定是根据之前跳转成功与否来决定的。给出所用代码以及设计思路,给出运行结果的截屏证明代码实现了目标。
我们只需要设计一个循环,然后每次都有不同的跳转结果即可。比如根据循环计数器 i 是奇数或者偶数进行跳转,因为 i 总是奇偶交替的:
.data
.text
dadd r8, r0, r0
daddi r8, r8, 10 # r8 = i = 10
daddi r9, r0, 1 # r9 = 1
loop:
beq r8, r0, end # 跳出循环
and r10, r8, r9 # r10 = r8 & 1 取最低位判断奇偶
daddi r8, r8, -1 # i--
beq r10, r0, loop # 为偶数时跳转
j loop # 返回
end:
halt
以 i=10 为例,偶数跳转触发,此时 BTB 中记录了结果为:“跳转”,而当 i–,i=9 时,偶数跳转失败,BTB 失效。当 i–,i=8 时,偶数跳转又触发了,但是此时 BTB 已经清除了,所以再次 branch taken stalls
在关闭 BTB 的情况下,我们看到 10 次循环就发生了 11 次 branch taken stalls(因为最后 beq 跳出也算一次,而且每次循环 j 或者 beq 都预测失误,共失误 10 次)


可以看到,因为奇偶交替,我们每当遇到奇数的时候,beq 预测都出现偏差,这导致了 5 次 branch mispronunciation stalls 和 branch taken stalls,一共 10 个周期。
此外,因为进入和退出循 环的 beq,我们 branch taken stalls 多了 2 次,即最终结果为 10+4=14 个周期的 branch taken stalls。
part 3 循环展开优化矩阵乘法
首先,我们需要对循环展开这个概念有一定的了解。
什么是循环展开呢?所谓循环展开就是通过在每次迭代中执行更多的数据操作来减小循环开销的影响。其基本思想是设法把操作对象线性化,并且在一次迭代中访问线性数据中的一个小组而非单独的某个。这样得到的程序将执行更少的迭代次数,于是循环开销就被有效地降低了。
接下来,我们就按照这种思想对上述的矩阵乘法程序进行循环展开。要求将上述的代码通过循环展开将最里面的一个执行迭代 8 次的循环整个展开了,也就是说,我们将矩阵相乘的三个循环通过代码的增加,减少到了两个循环。
比较,通过对比循环展开(未启用 BTB)、使用 BTB(未进行循环展开)以及未使用BTB且未作循环展开的运行结果。比较他们的 Branch Tanken Stalls和Branch Misprediction Stalls 的数量,并尝试给出评判。
因为最内循环最耗时间,我们将最内循环的 8 个累加拆分,即手动写 8 次 mx1[i][k]*mx2[k][j],我们枚举 k 使其为 0~7 即可:
.data
str: .asciiz "the data of matrix 3:\n"
mx1: .space 512
mx2: .space 512
mx3: .space 512
.text
initial: daddi r22,r0,mx1 #这个initial模块是给三个矩阵赋初值
daddi r23,r0,mx2
daddi r21,r0,mx3
input: daddi r9,r0,64
daddi r8,r0,0
loop1: dsll r11,r8,3
dadd r10,r11,r22
dadd r11,r11,r23
daddi r12,r0,2
daddi r13,r0,3
sd r12,0(r10)
sd r13,0(r11)
daddi r8,r8,1
slt r10,r8,r9
bne r10,r0,loop1
# i=r17, j=r18, k=r19
mul: daddi r16,r0,8
daddi r17,r0,0
loop2: daddi r18,r0,0 #这个循环是执行for(int i = 0, i < 8; i++)的内容
loop3: daddi r19,r0,0 #这个循环是执行for(int j = 0, j < 8; j++)的内容
daddi r20,r0,0 #r20存储在计算result[i][j]过程中每个乘法结果的叠加值
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6 # r8 = i*64
dsll r9,r19,3 # r9 = k*8
dadd r8,r8,r9
dadd r8,r8,r22 # r8 = mx1[i][k]
ld r10,0(r8) # 取mx1[i][k]的值
dsll r8,r19,6 # r8 = k*64
dsll r9,r18,3 # r9 = j*8
dadd r8,r8,r9
dadd r8,r8,r23 # r8 = mx2[k][j]
ld r11,0(r8) # 取mx2[k][j]的值
dmul r13,r10,r11 # mx1[i][k]与mx2[k][j]相乘
dadd r20,r20,r13 # 中间结果累加
daddi r19,r19,1 # k++
# ----------------------------------------------------#
dsll r8,r17,6
dsll r9,r18,3
dadd r8,r8,r9
dadd r8,r8,r21 #计算result[i][j]的位置
sd r20,0(r8) #将结果存入result[i][j]中
daddi r18,r18,1
slt r8,r18,r16
bne r8,r0,loop3
daddi r17,r17,1
slt r8,r17,r16
bne r8,r0,loop2
halt

因为我们将最内层的循环拆分了,分析如下:
未开启 BTB
那么在未开启BTB的情况下,我们初始化循环有 63 次 branch taken stalls,而外层循环执行 1 次,有 7 次 branch taken stalls,内层循环执行 8 次,有 8*7 次 branch taken stalls,共 8*7+1*7+63=126 次 branch taken stalls
开启 BTB
在开启 BTB 的情况下,初始化循环有 64 次单层循环,一共发生 1 次 branch taken stalls 和 1 次 branch mispronunciation stalls,即第一次和最后一次跳转,所以他们各占 2 个周期。
而因为拆分了循环,只有内外两层 8 次的循环。内循环执行 8 次,共有 8 次 branch taken stalls 和 branch mispronunciation stalls,外层循环执行 1 次,共有 1 次branch taken stalls 和 1 次 branch mispronunciation stalls,所以最终的数目是 9次,共占 18 个周期。
综合初始化(2)和循环(18),一共有 20 个周期的 branch taken stalls 和 branch mispronunciation stalls
结束语
不使用分支语句就不会发生分支预测问题!经典鸵鸟思维
分支预测的计算一定要小心。在未使用 BTB 时,因为 mips 恒预测不跳转,一个 n 次的循环,共发生 n-1 次 branch taken stalls
而开启BTB的情况下,第一次进入循环时,最后一次退出循环时,分别发生 branch taken stalls 和 branch mispronunciation stalls 各 1 次,但是 BTB 撤销操作,需要 2 个周期,所以最后的结果需要 x2 !
结论
分支预测的阻塞计算一定要小心谨慎,要考虑初始化语句带来的阻塞。
在开启BTB之后,由于撤销和记录操作占用2个周期,最后的阻塞要乘以2,这一点很容易引起计算错误。。。
拆分循环是很好的避免分支的策略,在一些缓存吃紧的应用场景中,非常好用