基本结构
半监督学习之伪标签学习
https://blog.csdn.net/weixin_42764932/article/details/112910467
和伪标签学习差不多
-
为有标签和无标签的图片。
-
使用有标签的数据、标准交叉熵损失训练了一个EfficientNet作为教师网络。
-
用不添加噪音的教师网络,在无标签数据上生成伪标签,伪标签可以是soft label(持续分布),或者hard label(one-hot分布)。文章说软标签效果更好。
-
在有标签和无标签数据下,使用交叉熵训练一个添加噪音的学生网络。
-
通过把学生网络视为教师网络,迭代以上步骤,生成新的伪标签,并训练学生网络。
学生模型种添加噪音的作用:
-
数据噪音:总所周知提高泛化能力,例如:不同图像同一个类这个不变量鼓励学生模型超越老师学习,用更多不同的图像做出相同的预测。
-
模型噪音:提高模型鲁棒性和泛化能力
具体设置:
-
随机深度:幸存概率因子为 0.8
-
dropout:分类层引入 0.5 的丢弃率
-
随机增强:应用两个随机运算,其震级设置为 27
-
数据过滤:将教师模型中置信度不高的图片过滤,因为这通常代表着域外图像
-
数据平衡:平衡不同类别的图片数量
-
教师模型输出的标签使用1)软标签(eg:[0.1,0.2,0.6,0.9]) or 2)硬标签(eg:[1,0,1,0,0,1]),,经过实验表明,软标签对域外图像又更强的指导作用,所以作者才用软标签作为伪标签格式
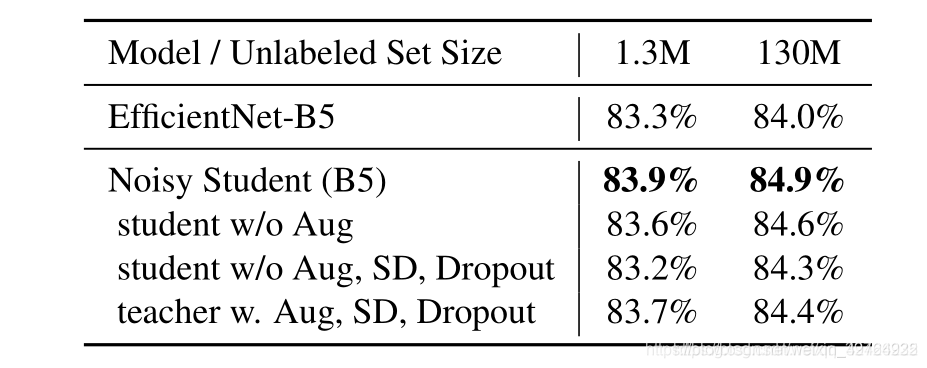
噪音、随机深度、数据扩充起着重要的作用使学生模型胜过教师模型,对此有人提出是不是对未标记数据加入正则项以防止过拟合来代替噪音,作者在实验中说明这是不对的。因为在去噪的情况下,未标记图像的训练损失并没有下降多少以此说明模型并没有对未标记数据过拟合。