首先分析知乎页面:
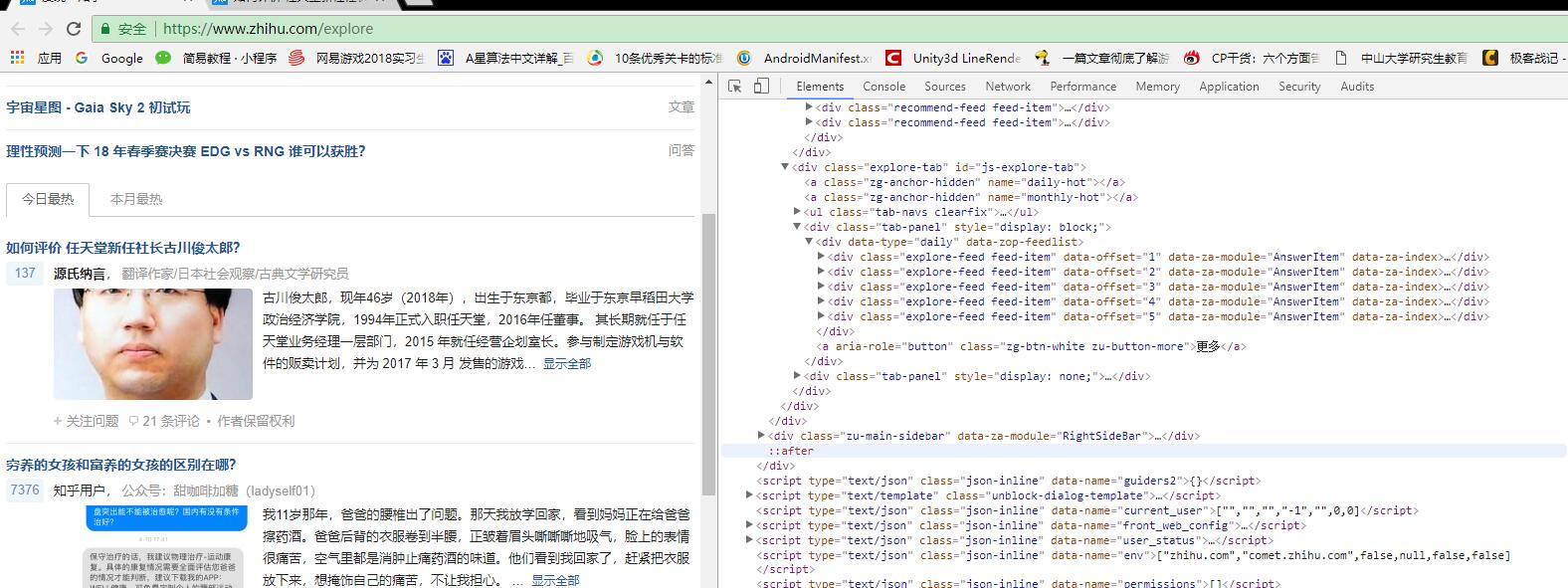
在Chrome检查模式下,Network选项卡中并未收到任何response。可见知乎的网页源码存放在Elements选项卡下。然后查看“今日最热”里的内容,发现子内容都保存在class属性为“explore-feed feed-item”的div标签中,任意打开其中一个子内容发现:
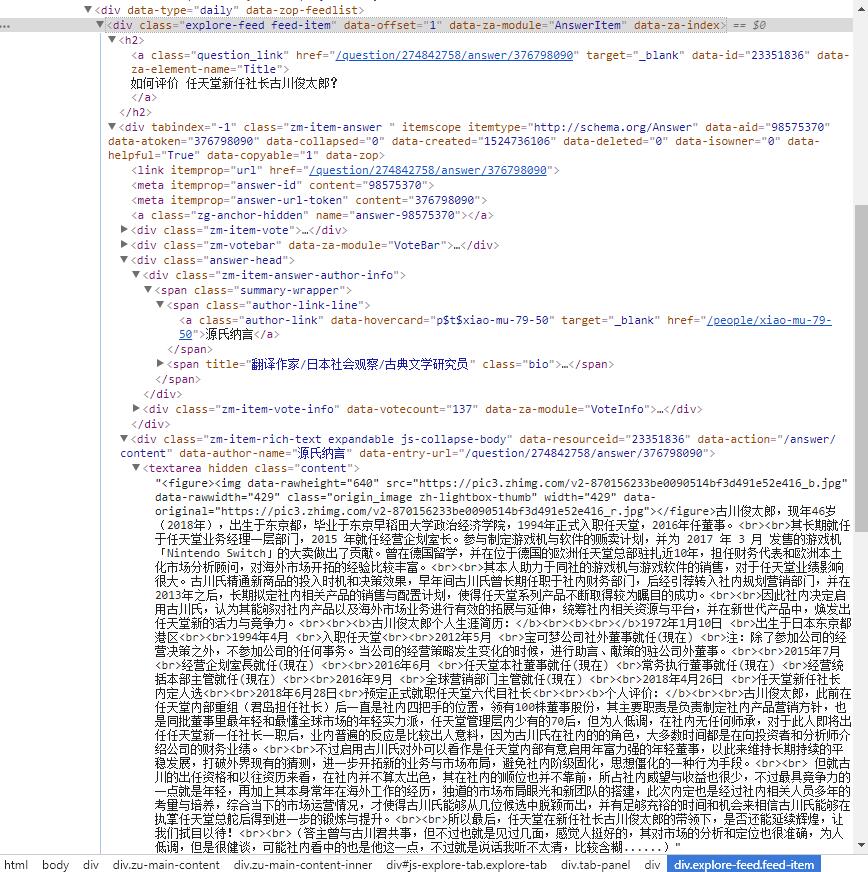
问题question存放在class="question-link"的h2标签中,回答作者author存放在class="author-link"的a标签中,回答内容answer就放在class="content"的标签中,本次我计划把这三部分内容提取出来,放在txt文件中。
相关代码如下:
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
html=requests.get(url,headers=headers).text
doc=pq(html)
items=doc('.exolore-feed.feed-item').items() #查找属性前面要加点。由字典函数返回遍历的元组数组
for item in items:
question=item.find('h2').text() #问题 ,查找标签相应的文本内容
author=item.find('.author-link').text() #回答者
answer=pq(item.find('.content').html()).text() #答案,查找相应的html模块对应的文本内容
file= open('explore.txt', 'w', encoding='utf-8')
file.write('\n'.join([question,author,answer]))
file.write('\n'+'='*50+'\n')
file.close()
print('finished!!!')